This tutorial shows you how to build a complete speaker identification and diarization system using AssemblyAI's Python SDK, addressing needs in the rapidly growing speaker diarization market that reached $1.21 billion in 2024. You'll learn to separate speakers in audio files and map them to actual names or roles, transforming generic "Speaker A" labels into meaningful identifications like "John Smith" or "Customer Service Agent."
We'll cover both approaches: enabling both features in a single API call and adding identification to existing transcripts. You'll work with AssemblyAI's speech-to-text API, the speech understanding endpoint, and explore role-based versus name-based identification strategies. By the end, you'll have working code examples for common scenarios like call center monitoring, meeting transcription, and podcast production.
What is the difference between speaker diarization and speaker identification?
Speaker diarization separates speech by different speakers and labels them as Speaker A, Speaker B, and so on. This means it knows when different people talk but doesn't know who they are.
Speaker identification takes those generic labels and replaces them with actual names or roles you provide. So instead of "Speaker A said hello," you get "John Smith said hello."
Here's how they work together:
Feature | Purpose | Output Example | When to Use |
|---|
Speaker Diarization | Separates speech by different speakers | "Speaker A: Hello, how can I help you?" | When you need to distinguish between speakers but don't need names |
Speaker Identification | Maps speaker labels to real names/roles | "John Smith: Hello, how can I help you?" | When you need to attribute speech to specific people or roles |
Both Combined | Complete speaker attribution | Full transcript with named speakers | Most production applications requiring speaker names |
You need diarization enabled first before identification can work. The system can't identify speakers by name if it hasn't separated them into distinct speakers.
Look at this example showing the difference:
// Diarization only
{
"speaker": "A",
"text": "Good morning, welcome to the show."
}
// With identification added
{
"speaker": "Michel Martin",
"text": "Good morning, welcome to the show."
}
How to implement speaker identification and diarization
You have several ways to set up both features using AssemblyAI's Python SDK. We'll show you the most common approaches.
Enable both features in one request
This approach combines both features in a single API call. It's the easiest method when you know speaker names upfront.
First, install the AssemblyAI Python SDK:
pip install assemblyai
Then create your transcription with both features:
import assemblyai as aai
# Set up your API key
aai.settings.api_key = "YOUR_API_KEY"
# Configure both diarization and identification
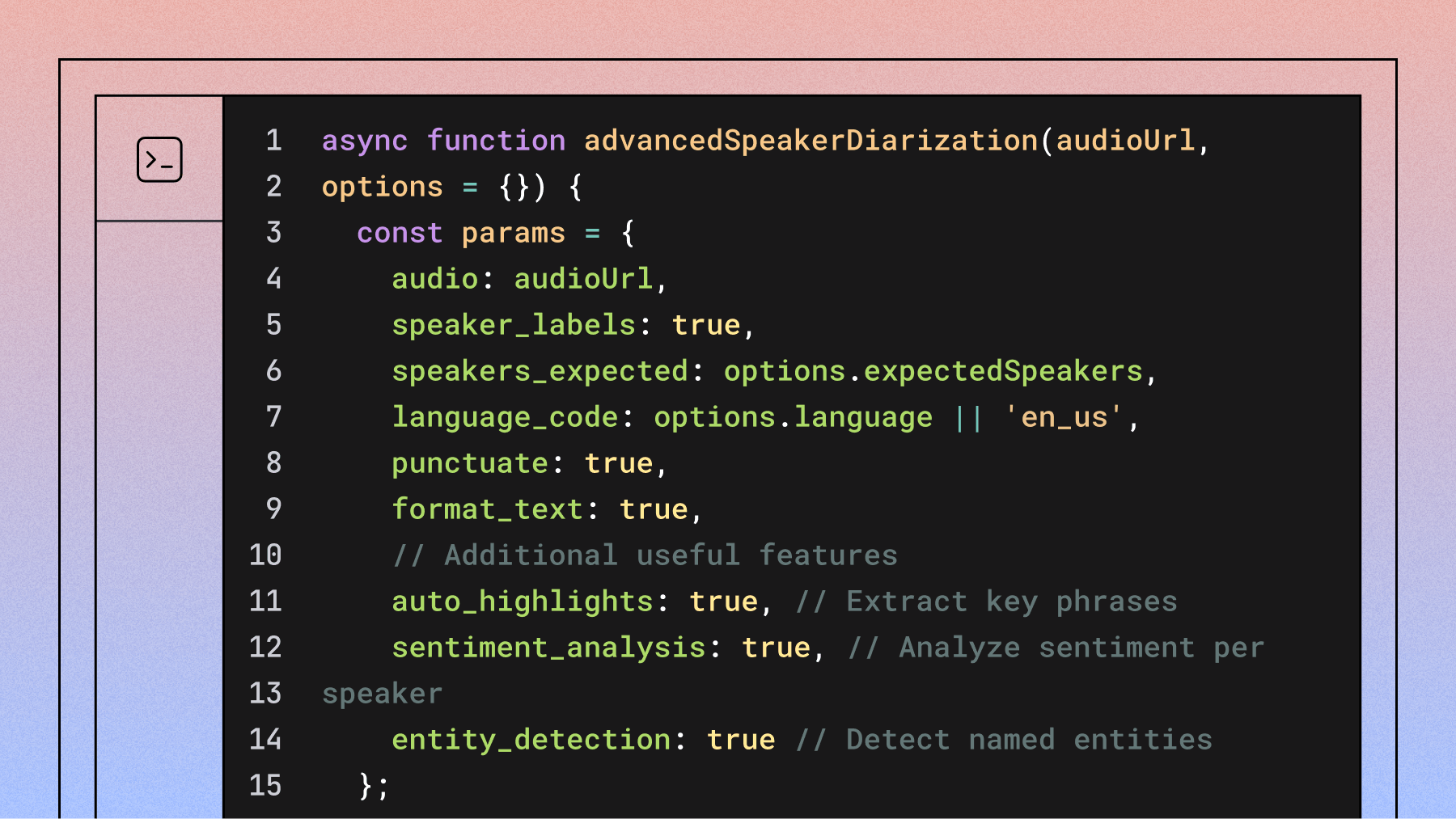
config = aai.TranscriptionConfig(
speaker_labels=True, # This enables diarization
speech_understanding={
"request": {
"speaker_identification": {
"speaker_type": "name",
"known_values": ["Michel Martin", "Peter DeCarlo"]
}
}
}
)
# Run the transcription
transcriber = aai.Transcriber()
transcript = transcriber.transcribe(
"https://assembly.ai/wildfires.mp3",
config=config
)
# Get your results with speaker names
for utterance in transcript.utterances:
print(f"{utterance.speaker}: {utterance.text}")
This method processes everything in one step. The system first separates speakers, then applies your provided names automatically.
Add speaker identification in one API call
You just saw how to enable diarization and identification together using the Python SDK. Create your account to get an API key and run the code on your audio.
Start free
Add identification to existing transcripts
Sometimes you already have transcripts with speaker labels but need to add names later. This works well when speaker names aren't known during transcription.
import assemblyai as aai
import requests
aai.settings.api_key = "YOUR_API_KEY"
# Create transcript with diarization only first
config = aai.TranscriptionConfig(speaker_labels=True)
transcriber = aai.Transcriber()
transcript = transcriber.transcribe(
"https://assembly.ai/wildfires.mp3",
config=config
)
# Add speaker identification later
headers = {"authorization": "YOUR_API_KEY"}
understanding_body = {
"transcript_id": transcript.id,
"speech_understanding": {
"request": {
"speaker_identification": {
"speaker_type": "name",
"known_values": ["Michel Martin", "Peter DeCarlo"]
}
}
}
}
# Send to the speech understanding endpoint
response = requests.post(
"https://llm-gateway.assemblyai.com/v1/understanding",
headers=headers,
json=understanding_body
)
result = response.json()
# Process your identified speakers
for utterance in result["utterances"]:
print(f"{utterance['speaker']}: {utterance['text']}")
This two-step process gives you flexibility. You can add identification anytime after transcription as long as the original transcript has speaker labels enabled.
Essential API parameters
You need to understand these key parameters for successful implementation:
Parameter | Type | Required | Description |
|---|
speaker_labels
| boolean | Yes | Enables speaker diarization (must be True) |
speakers_expected
| integer | No | Exact number of speakers if known (improves accuracy) |
speaker_identification.speaker_type
| string | Yes | Either "name" for personal names or "role" for job titles |
speaker_identification.known_values
| array | Conditional | List of names/roles (max 35 characters each). Required when speaker_type is set to 'role'. Optional when speaker_type is set to 'name'. |
Here's how to use them together:
config = aai.TranscriptionConfig(
speaker_labels=True,
speakers_expected=2, # Optional: helps if you know exactly 2 speakers
speech_understanding={
"request": {
"speaker_identification": {
"speaker_type": "name",
"known_values": ["John Smith", "Jane Doe"]
}
}
}
)
Key requirements for your parameters:
- Speaker labels must be True: Without this, identification won't work
- Keep names under 35 characters: Longer names get truncated
- Match speaker type to your values: Use "name" for personal names, "role" for job titles
Understanding the response format
The response structure changes when identification is applied. Here's what you'll see before and after.
Without identification:
{
"utterances": [
{
"speaker": "A",
"text": "Welcome to today's interview.",
"start": 240,
"end": 2560,
"words": [
{
"text": "Welcome",
"start": 240,
"end": 640,
"speaker": "A"
}
]
}
]
}
With identification applied:
{
"utterances": [
{
"speaker": "Michel Martin",
"text": "Welcome to today's interview.",
"start": 240,
"end": 2560,
"words": [
{
"text": "Welcome",
"start": 240,
"end": 640,
"speaker": "Michel Martin"
}
]
}
]
}
Notice how the speaker field at both utterance and word level now contains the identified name instead of a generic label. This applies throughout your entire transcript.
Test diarization in the Playground
Explore utterances, word-level speakers, and timestamps on sample audio before you integrate the API. See how speaker labels behave across different files.
Open Playground
Advanced implementation options
Identify speakers by role instead of names
Role-based identification works well when you don't know speaker names but understand their functions. This approach is perfect for customer service calls, medical consultations, or any scenario with defined roles.
Speaker Type | Use Case | Example Values |
|---|
"name" | Meetings, interviews, podcasts | ["John Smith", "Jane Doe"] |
"role" | Customer service, healthcare | ["Agent", "Customer"] |
Here's how to implement role-based identification:
import assemblyai as aai
aai.settings.api_key = "YOUR_API_KEY"
# Set up role-based identification
config = aai.TranscriptionConfig(
speaker_labels=True,
speech_understanding={
"request": {
"speaker_identification": {
"speaker_type": "role", # Changed from "name"
"known_values": ["Agent", "Customer"]
}
}
}
)
# Run transcription with role identification
transcriber = aai.Transcriber()
transcript = transcriber.transcribe(
"your_call_center_audio.mp3",
config=config
)
# Results show roles instead of names
for utterance in transcript.utterances:
print(f"{utterance.speaker}: {utterance.text}")
# Output: "Agent: How may I help you today?"
# Output: "Customer: I need to check my order status."
Common role combinations you can use:
- Call Centers: ["Agent", "Customer"]
- Healthcare: ["Doctor", "Patient"]
- Interviews: ["Interviewer", "Interviewee"]
- Support: ["Support", "User"]
- Podcasts: ["Host", "Guest"]
Industry applications
Different industries use speaker identification and diarization for specific purposes:
Industry | Application | Speaker Type Used | Key Benefits |
|---|
Call Centers | Quality monitoring and compliance | Roles (Agent/Customer) | Automated scoring, training insights |
Meeting Intelligence | Automated meeting notes and action items | Names (attendee list) | Accurate attribution, follow-up tracking |
Healthcare | Clinical documentation and EHR integration | Roles (Doctor/Patient) | HIPAA compliance, accurate records |
Legal | Deposition and hearing transcription | Names (all parties) | Court-ready transcripts, evidence tracking |
Media & Podcasts | Content creation and accessibility | Names or Roles | Searchable archives, show notes |
Call center quality monitoring represents one of the most common use cases, with recent call center AI implementations demonstrating how financial services providers extract actionable insights from call transcripts. By separating agents and customers, supervisors can automatically analyze talk time ratios, interruption patterns, and script adherence.
Meeting intelligence platforms use name-based identification to track individual contributions and assign action items. When integrated with calendar systems, these platforms can automatically populate speaker names from meeting invites.
Healthcare documentation relies on role-based identification to maintain clear records of doctor-patient interactions, with studies showing clinical accuracy improvements of up to 60% when speakers are correctly identified. The separation enables automated extraction of symptoms, diagnoses, and treatment plans while maintaining compliance requirements.
Final words
Speaker identification and diarization with AssemblyAI simplifies complex audio processing into a single API workflow. You can enable both features together or add identification to existing transcripts, giving you flexibility for any use case.
AssemblyAI's Voice AI models provide reliable speech-to-text with deep speech understanding capabilities. The platform scales to handle enterprise workloads while maintaining accuracy across different audio conditions and speaker types.
Build speaker identification today
Ship name- or role-based speaker attribution with AssemblyAI's Speech Understanding and diarization. Get your API key and start implementing the workflows from this guide.
Get API key
Frequently asked questions
Do I need to enable speaker diarization before using speaker identification?
Yes, speaker identification requires diarization as a prerequisite. The system must first separate speakers before it can map them to names or roles.
Can I use speaker identification with AssemblyAI's streaming transcription?
No, speaker identification only works with async transcription. Streaming transcription supports diarization but not identification.
How many speakers can AssemblyAI identify in a single audio file?
AssemblyAI can identify up to 10 speakers by default. The actual number depends on how well the diarization model can distinguish unique voices in your audio.
What happens if I provide more speaker names than the system detects?
The system automatically uses only the names needed for detected speakers. Extra names in your known_values array are ignored without causing errors.
Can I add speaker identification to transcripts that don't have speaker labels?
No, you must re-transcribe with speaker_labels=True enabled first. Speaker identification can only be applied to transcripts that already have speaker diarization.
Title goes here
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.