
How to evaluate Speech Recognition models
Speech Recognition models are key in extracting useful information from audio data. Learn how to properly evaluate speech recognition models in this easy-to-follow guide.

Senior Developer Educator
Speech Recognition models are key in extracting useful information from audio data. Learn how to properly evaluate speech recognition models in this easy-to-follow guide.
A new method both improves performance and lowers computational requirements through a clever observation in speech theory

LiveKit allows you to build real-time audio and video applications - now you can build with AssemblyAI's Streaming Speech-to-Text in LiveKit.
LiveKit allows you to build real-time audio and video applications - learn how to add real-time Speech-to-Text to your LiveKit application in this tutorial.

Universal-2 is solving problems in Conversational Intelligence by optimizing Speech-to-Text for real-world use cases
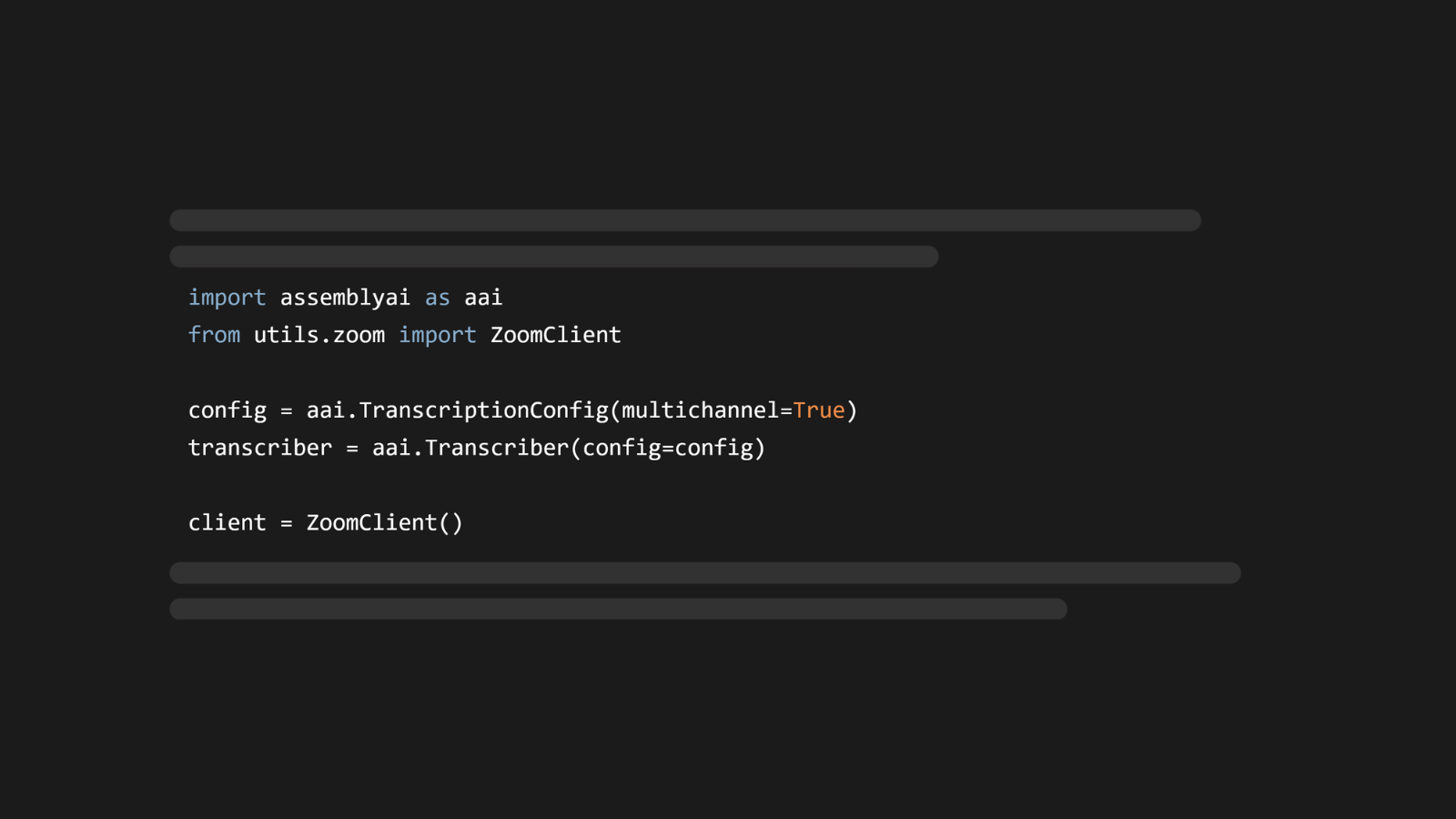
Zoom allows you to record each participant's audio track separately. Learn how to combine this with AssemblyAI's multichannel transcription for accurate meeting transcripts.
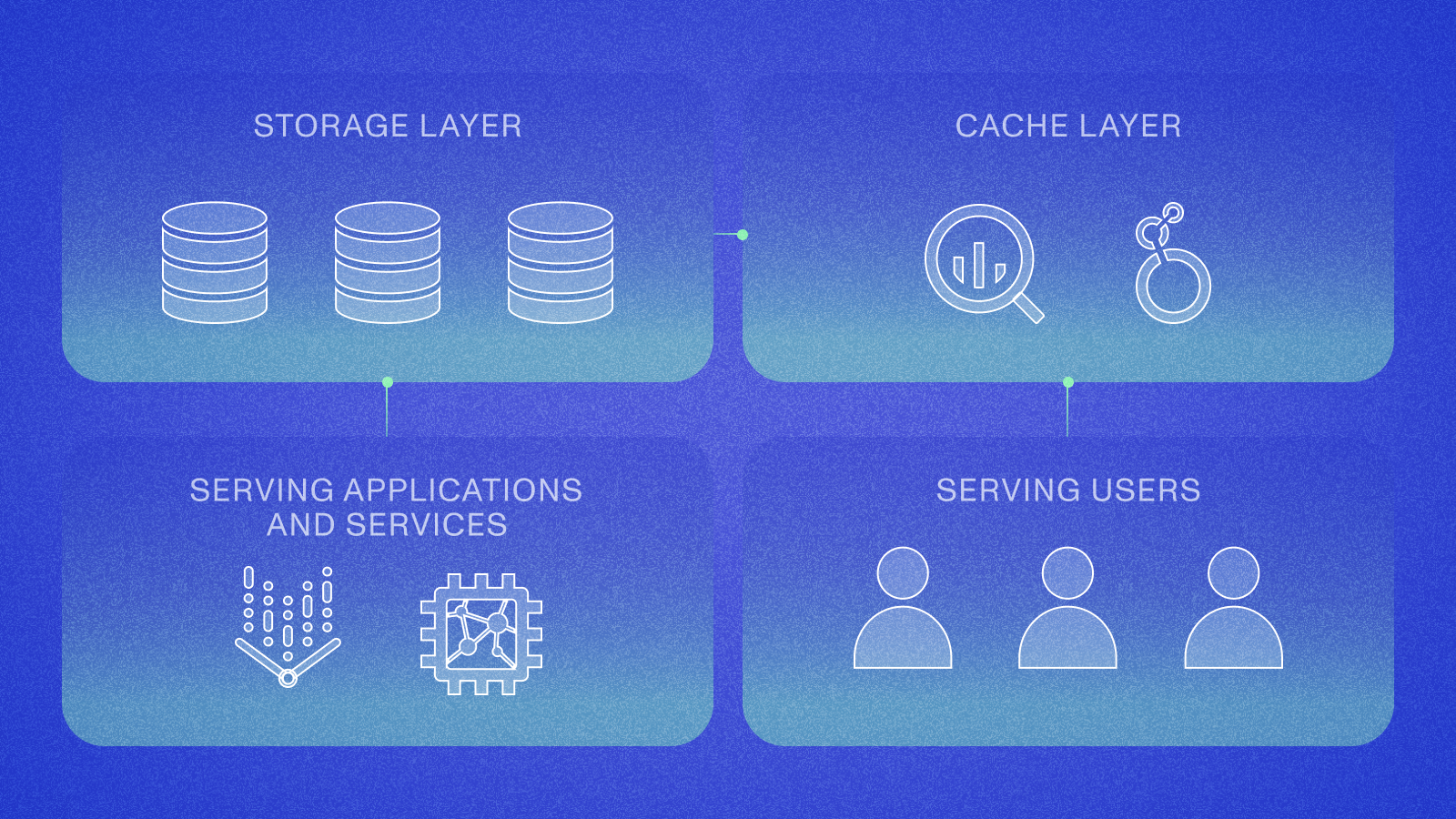
Learn how we built our AI data Lakehouse to allow for rapid research iteration while maintaining cohesive, secure, and deduplicated datasets.

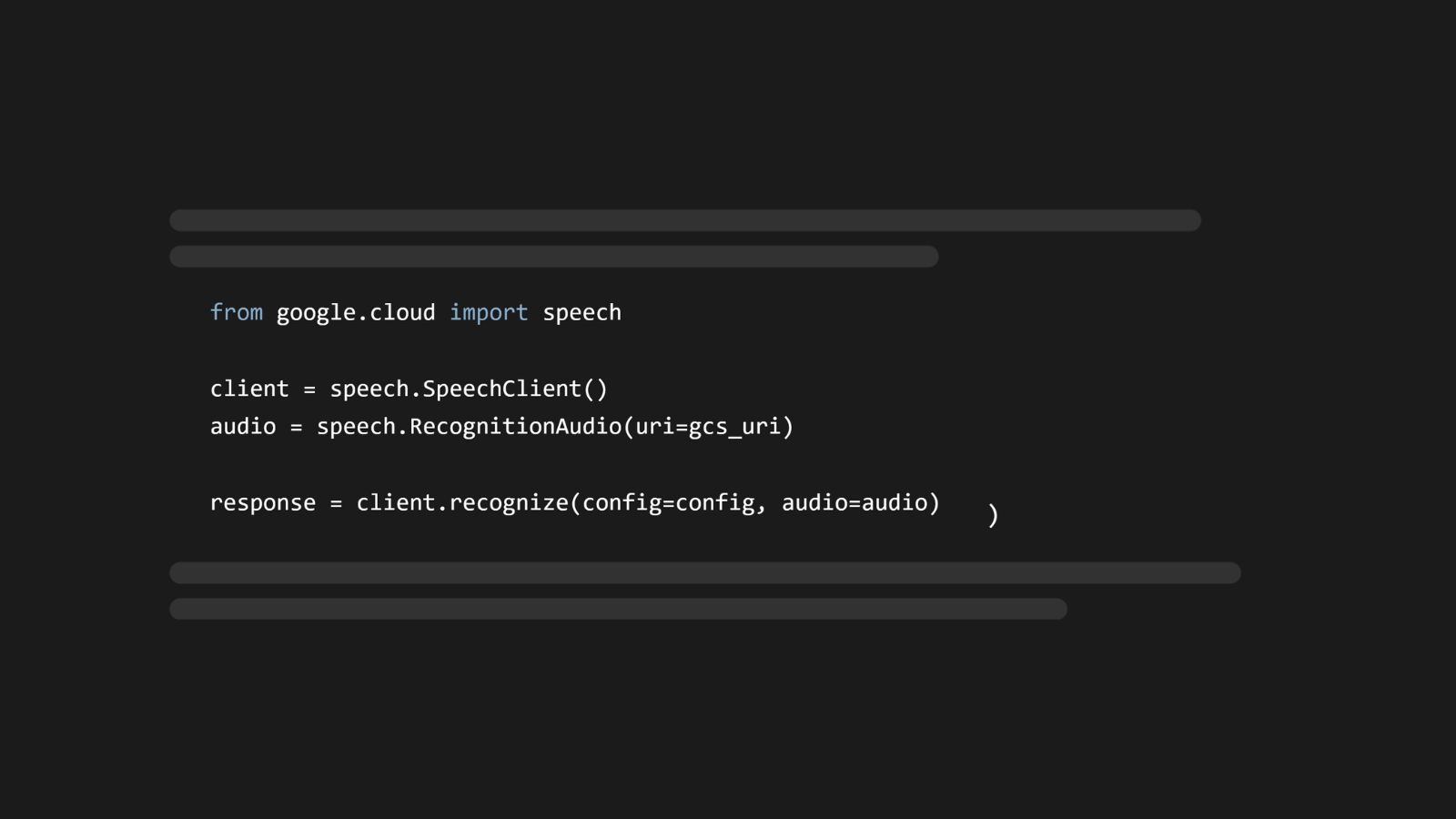
Learn how to set up a Google Cloud project to transcribe both local and remote audio files using Google's Speech-to-Text API and Python
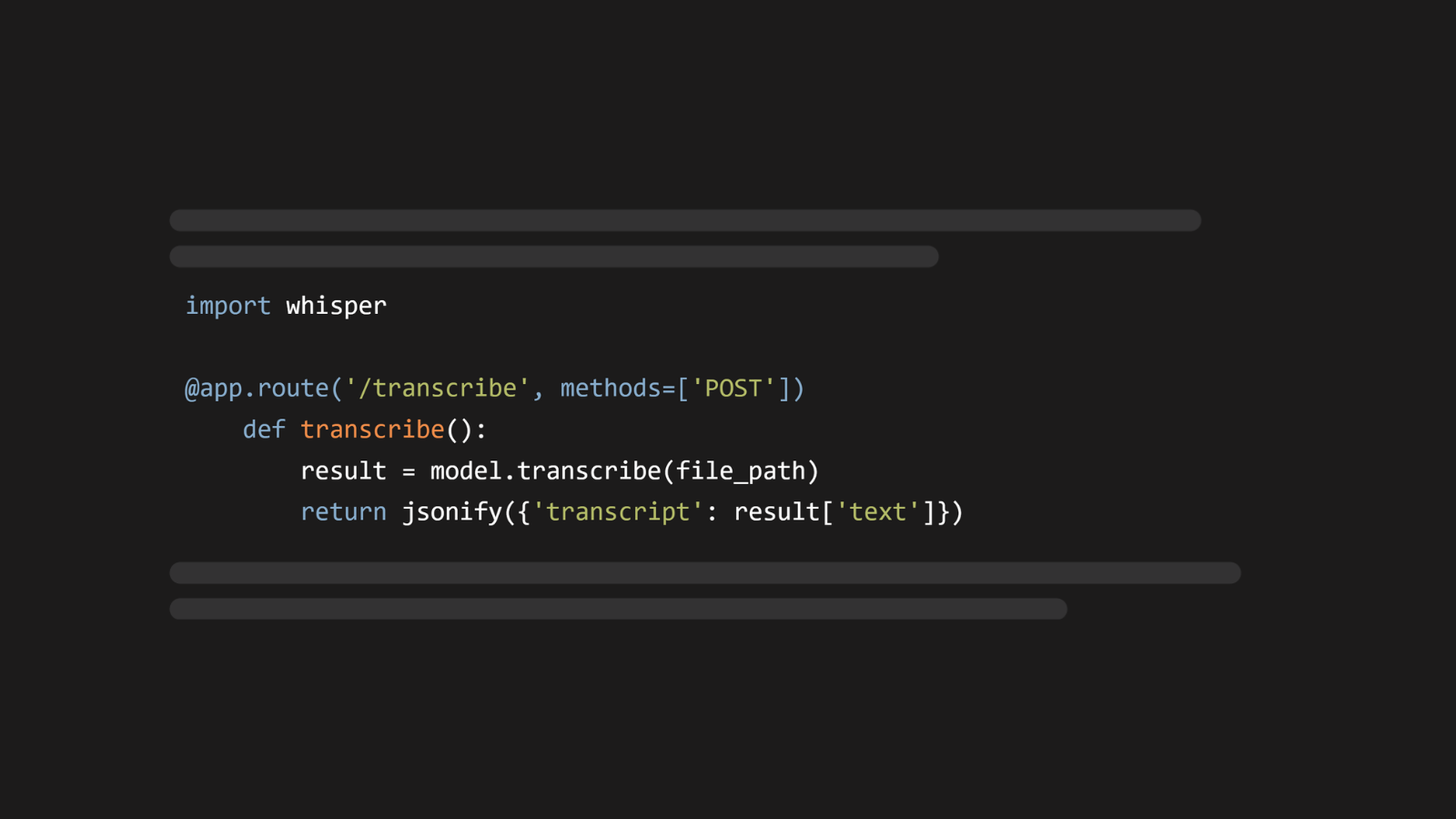
Learn how to make a free, GPU-powered Whisper API for transcribing audio files

Learn how to use Python to perform speaker diarization on audio and video files to identify "who said what when"

Learn the differences between speaker diarization and speaker recognition, as well as speaker verification and speaker identification in audio analysis

Microsoft's Florence-2 is a foundational image model that can perform almost every common task in computer vision. Learn how Florence-2 works and how to use it in this guide.
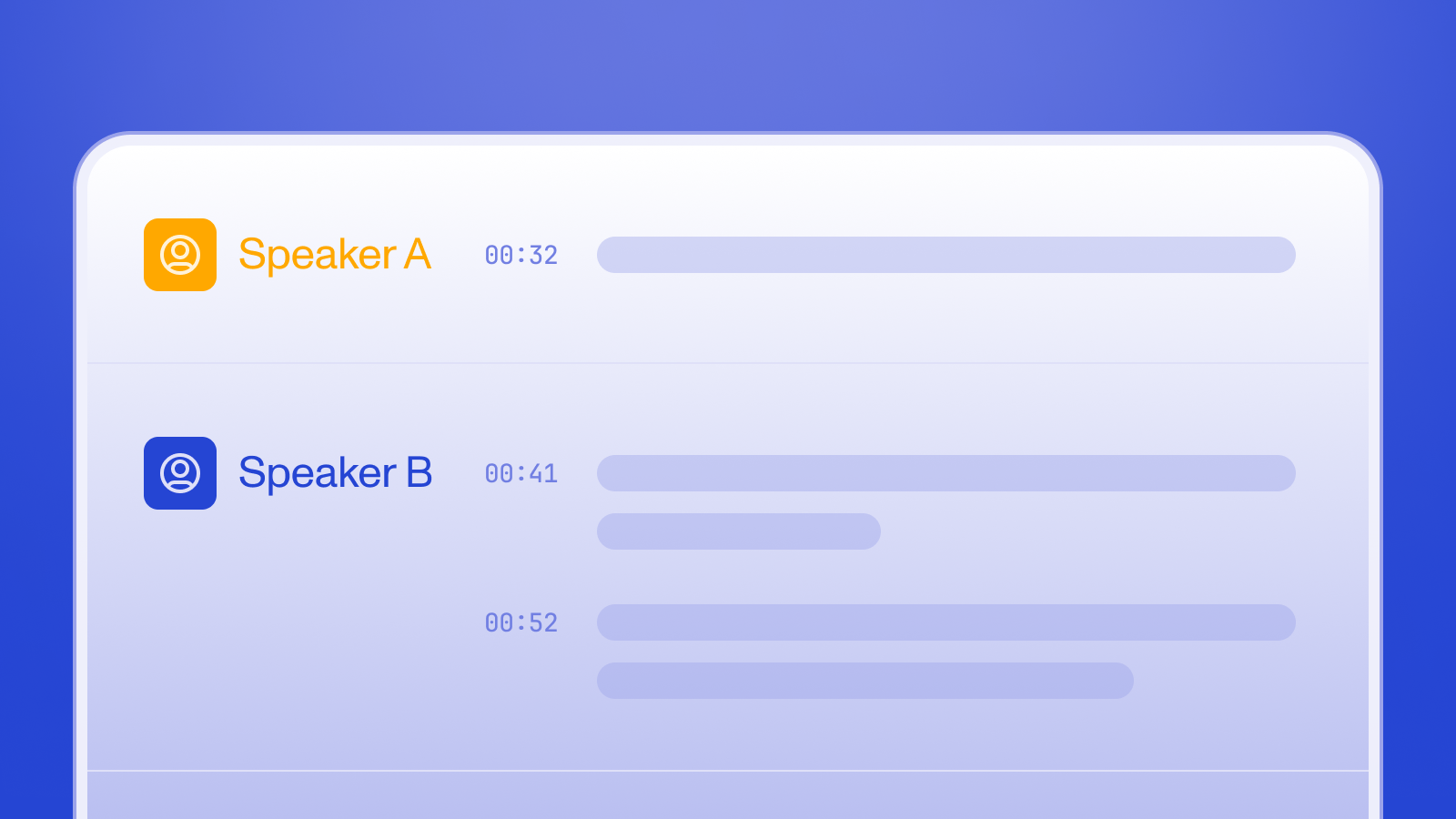
Announcing several improvements to our Speaker Diarization service, yielding a more accurate model that's available in more languages.

Modern AI models make it easy to automatically detect the presence of sensitive topics in speech data. Learn how to perform configurable content moderation with Python in this tutorial.

Learn how to filter profanity out of audio and video files with fewer than 10 lines of code in this tutorial

In this tutorial, we’ll learn how to automatically redact Personal Identifiable Information (PII) from audio and video files in 5 minutes using Python and AssemblyAI.

Learn how to transcribe a phone call in real-time using Python, AssemblyAI, ngrok, and Twilio

We’re excited to introduce major improvements to our API’s inference latency, with the majority of audio files now completing in well under 45 seconds regardless of audio duration.

Learn how to automatically extract insights from customer calls with Large Language Models (LLMs) and Python.

In this tutorial, we will learn how to automatically determine video sections, how to generate section titles with LLMs, and how to format the information for YouTube chapters.

Learn how to perform real-time transcription on audio streams using Python in this tutorial.

How does OpenAI's groundbreaking DALL-E 2 model actually work? Check out this detailed guide to learn the ins and outs of DALL-E 2.
Retrieval Augmented Generation (RAG) allows you to add relevant documents as context when querying LLMs. Learn how to perform RAG on audio data using LangChain and Chroma in this tutorial.

In this tutorial, we'll learn how to get Zoom transcripts using the Zoom API using Python.

Learn how to perform Automatic Speech Recognition in 5 minutes using Python and the AssemblyAI Speech-to-Text API with this simple tutorial.