Detecting low confidence words from Speech-to-Text with Node.js
Learn how to identify potential issues in your transcripts using AssemblyAI and Node.js




Speech-to-Text models today are more accurate than ever and can transcribe speech with unbelievable fidelity. Modern models like Universal are even able to capture the high-resolution details of transcripts, like proper nouns, punctuation, and formatting.
But even the best AI speech recognition models can struggle on certain words, especially if the audio quality is low or a speaker is not speaking clearly. The good news? You can identify these potentially problematic sections by checking the confidence scores that come with your transcripts. This allows you to, for example, flag sentences that potentially have errors for manual review.
In this guide, you'll learn how to detect sentences containing words with low confidence scores using AssemblyAI in Node.js.
Understanding Confidence Scores
Each word, utterance, sentence, and paragraph in an AssemblyAI transcript comes with a confidence score ranging from 0.0 (low confidence) to 1.0 (high confidence). These scores represent how certain the model was when transcribing that particular word.
For this tutorial, we'll use a threshold of 0.55 to flag words as "low confidence" (to ensure we have some results printed), but you can adjust this threshold based on your needs when implementing this in your own applications.
Setting Up Your Environment
Before you get started, make sure to have your AssemblyAI API key handy. Additionally, you'll need Node.js and the AssemblyAI Node.js SDK installed on your machine with the package manager of your choice:
npm install assemblyaiStep 1: Create a transcript
Create and open a file called index.mjs. First, import the SDK and initialize the client with your API key. You can specify it as a string for this example if you have not saved it as an environment variable, but it's recommended to use environment variables for security reasons.
import { AssemblyAI } from "assemblyai";
const client = new AssemblyAI({
apiKey: process.env.ASSEMBLYAI_API_KEY,
// or you can specify it as a string
// apiKey: "your-api-key-here",
});Next, add the following code to submit your audio file for transcription. We use an example file here, but you can use any publicly-available remote file or a local file path.
const transcript = await client.transcripts.transcribe({
audio_url: "https://assembly.ai/wildfires.mp3",
})Step 2: Get Sentences from the Transcript
Once your file has been transcribed, retrieve the transcript broken down into sentences:
let { id } = transcript
let { sentences } = await client.transcripts.sentences(id)Step 3: Filter Sentences with Low Confidence Words
Set your confidence threshold - we'll use 0.55 in this example. A higher confidence threshold means more sentences will be flagged and therefore potentially more false positives, and a lower confidence threshold means fewer sentences will be flagged and potentially more false negatives.
let confidenceThreshold = 0.55Next, add the following code to find all sentences containing at least one word below our confidence threshold:
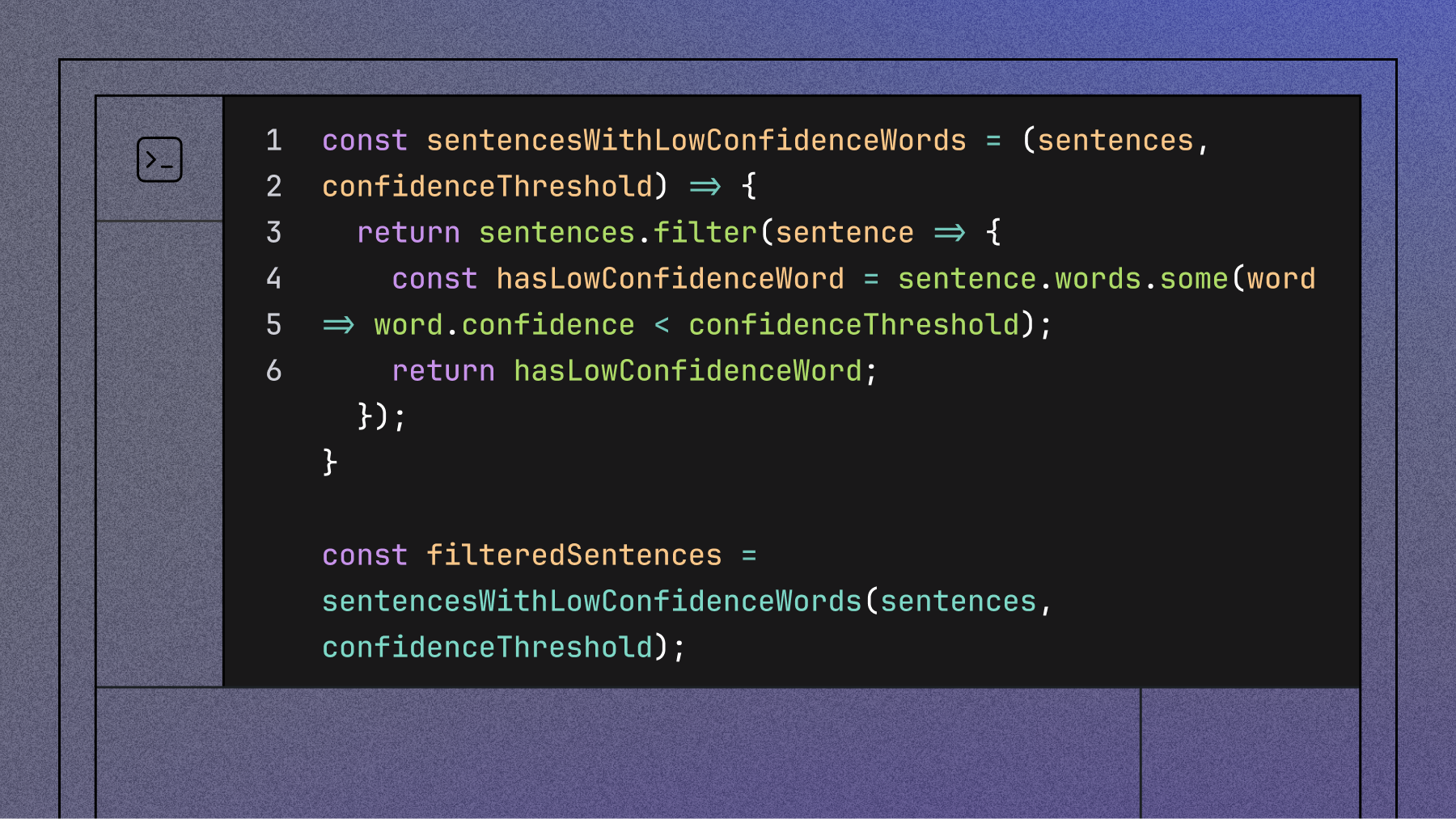
const sentencesWithLowConfidenceWords = (sentences, confidenceThreshold) => {
return sentences.filter(sentence => {
const hasLowConfidenceWord = sentence.words.some(word => word.confidence < confidenceThreshold);
return hasLowConfidenceWord;
});
}
const filteredSentences = sentencesWithLowConfidenceWords(sentences, confidenceThreshold);Step 4: Isolate the Low Confidence Words
For each sentence that contains low confidence words, filter out just those problematic words:
const filterScores = filteredSentences.map(item => {
return {
...item,
words: item.words.filter(word => word.confidence < confidenceThreshold)
}
})Step 5: Format and Display the Results
Now, let's format the results in a human-readable way. First, create a helper function to format timestamps:
const formatMilliseconds = (milliseconds) => {
// Calculate hours, minutes, and seconds
const hours = Math.floor(milliseconds / 3600000);
const minutes = Math.floor((milliseconds % 3600000) / 60000);
const seconds = Math.floor((milliseconds % 60000) / 1000);
// Ensure the values are displayed with leading zeros if needed
const formattedHours = hours.toString().padStart(2, '0');
const formattedMinutes = minutes.toString().padStart(2, '0');
const formattedSeconds = seconds.toString().padStart(2, '0');
return `${formattedHours}:${formattedMinutes}:${formattedSeconds}`;
}Next, format the final results:
// Format the final results
const finalResults = filterScores.map(res => {
return `The following sentence at timestamp ${formatMilliseconds(res.start)} contained low confidence words: ${res.text} \n Low confidence word(s) from this sentence: ${res.words.map(res => {return `${res.text}[score: ${res.confidence}]`}).join(', ')}`
})
console.log(finalResults)Finally, execute the script by executing the following command in the terminal:
node index.mjsSample Output
Here is the output when running the above example file with a threshold of 0.55:
[
'The following sentence at timestamp 00:00:00 contained low confidence words: Smoke from hundreds of wildfires in Canada is triggering air quality alerts throughout the US Skylines from Maine to Maryland to Minnesota are gray and smoggy. \n' +
' Low confidence word(s) from this sentence: gray[score: 0.50474]',
"The following sentence at timestamp 00:00:40 contained low confidence words: The season has been pretty dry already, and then the fact that we're getting hit in the US is because there's a couple weather systems that are essentially channeling the smoke from those Canadian wildfires through Pennsylvania into the mid Atlantic and the Northeast and kind of just dropping the smoke there. \n" +
' Low confidence word(s) from this sentence: and[score: 0.5298]',
"The following sentence at timestamp 00:01:07 contained low confidence words: And most of that is due to what's called particulate matter, which are tiny particles, microscopic, smaller than the width of your hair, that can get into your lungs and impact your respiratory system, your cardiovascular system, and even your neurological, your brain. \n" +
' Low confidence word(s) from this sentence: particles,[score: 0.51548], your[score: 0.53032]',
"The following sentence at timestamp 00:02:17 contained low confidence words: It's the youngest. \n" +
' Low confidence word(s) from this sentence: the[score: 0.53084]',
"The following sentence at timestamp 00:02:18 contained low confidence words: So children, obviously, whose bodies are still developing, the elderly who are, you know, their bodies are more in decline and they're more susceptible to the health impacts of breathing, the poor air quality. \n" +
' Low confidence word(s) from this sentence: you[score: 0.53058]',
"The following sentence at timestamp 00:03:23 contained low confidence words: Right now it's the weather systems that are pulling that air into our Mid Atlantic and Northeast region. \n" +
' Low confidence word(s) from this sentence: Atlantic[score: 0.52789]',
"The following sentence at timestamp 00:04:11 contained low confidence words: So yeah, this is probably something that we'll be seeing more, more frequently. \n" +
' Low confidence word(s) from this sentence: more,[score: 0.50826]'
]Practical Applications
This approach is particularly valuable for:
- Call Center Quality Assurance - Quickly identify potentially misheard customer or agent names
- Medical Transcription - Flag specialized terminology or drug names that may need expert review
- Legal Documentation - Ensure accuracy in critical case details where precision matters
- Educational Content - Verify technical terms are transcribed correctly in lectures
Conclusion
By identifying sentences with low confidence words, you can dramatically improve your transcription review workflow. Rather than reviewing an entire transcript, you can focus your attention on just the sections that are most likely to contain errors.
This not only improves the accuracy of your final transcripts but also saves valuable time in the review process. The AssemblyAI API makes this process straightforward with its built-in confidence scoring for every transcribed word.
This blog is based on our related cookbook. For more tips and tricks on working with AssemblyAI, check out our cookbooks repository.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.