Announcing the AssemblyAI integration for LiveKit
LiveKit allows you to build real-time audio and video applications - now you can build with AssemblyAI's Streaming Speech-to-Text in LiveKit.

LiveKit allows you to build real-time audio and video applications - now you can build with AssemblyAI's Streaming Speech-to-Text in LiveKit.
LiveKit allows you to build real-time audio and video applications - learn how to add real-time Speech-to-Text to your LiveKit application in this tutorial.

Universal-2 is solving problems in Conversational Intelligence by optimizing Speech-to-Text for real-world use cases
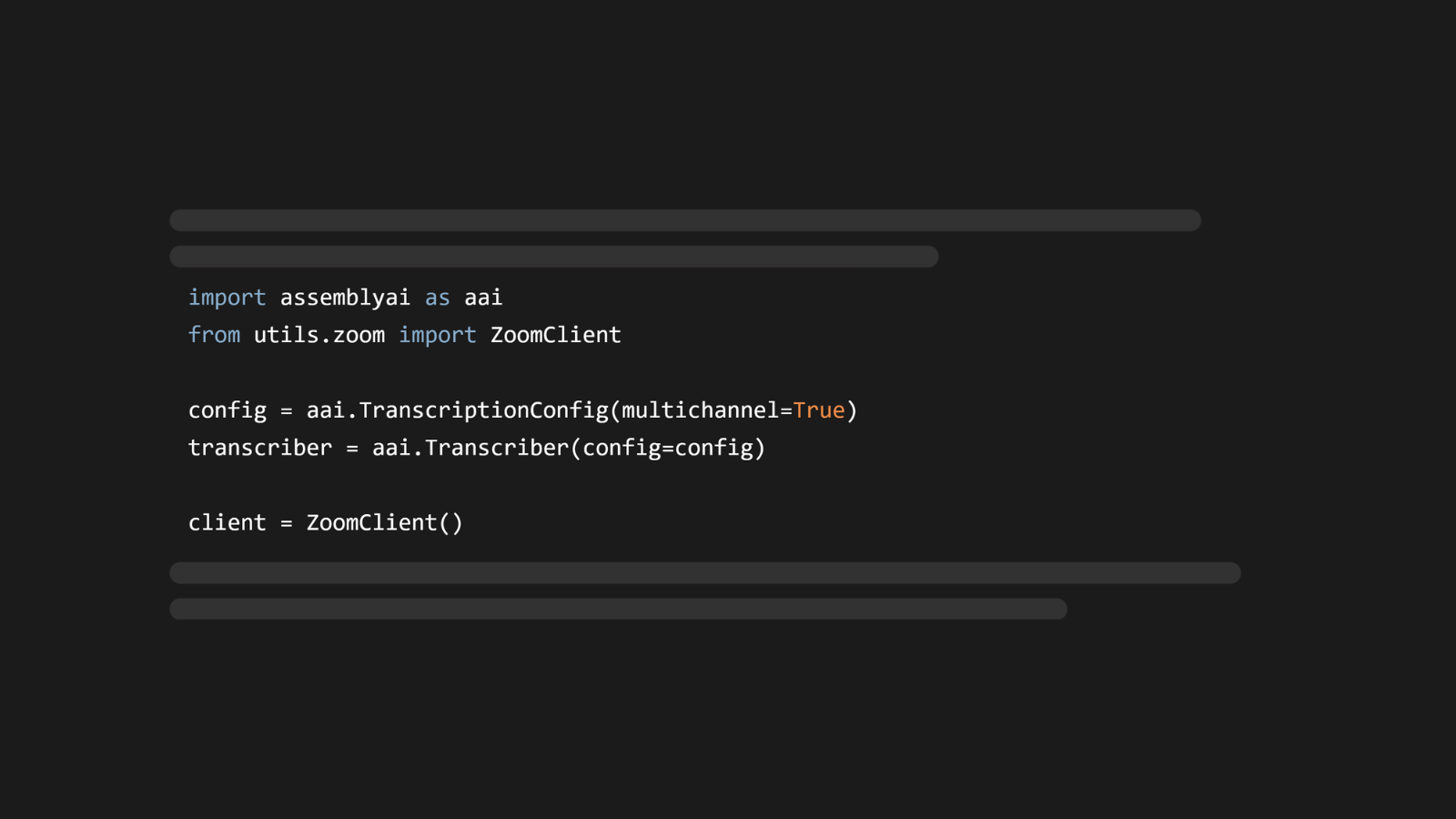
Zoom allows you to record each participant's audio track separately. Learn how to combine this with AssemblyAI's multichannel transcription for accurate meeting transcripts.
Learn how to transcribe audio and video files in your Python applications with AssemblyAI's Universal-1 speech recognition model.

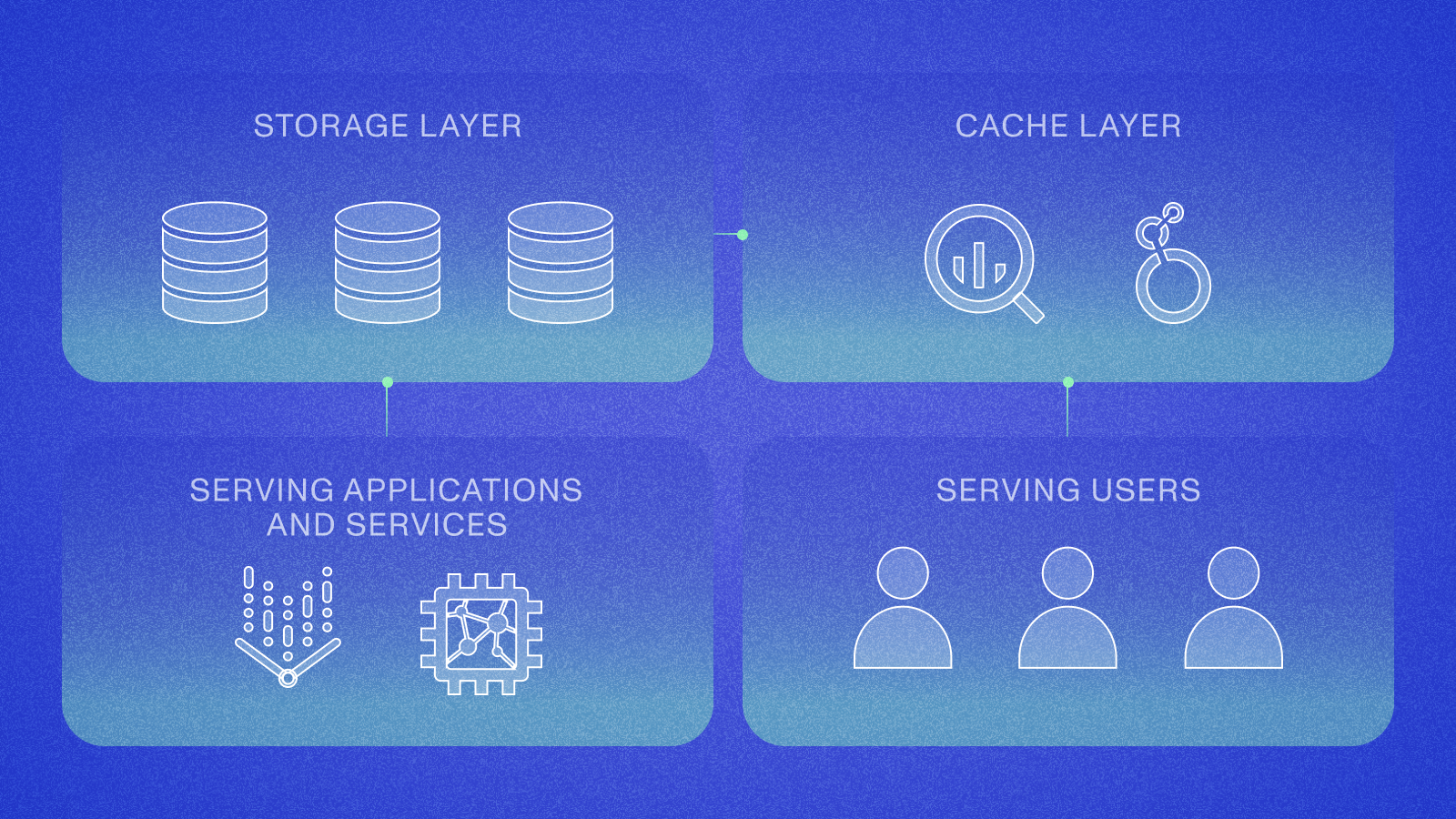
Learn how we built our AI data Lakehouse to allow for rapid research iteration while maintaining cohesive, secure, and deduplicated datasets.


Learn how to build a Speech AI app that lets you talk to ChatGPT over the phone.

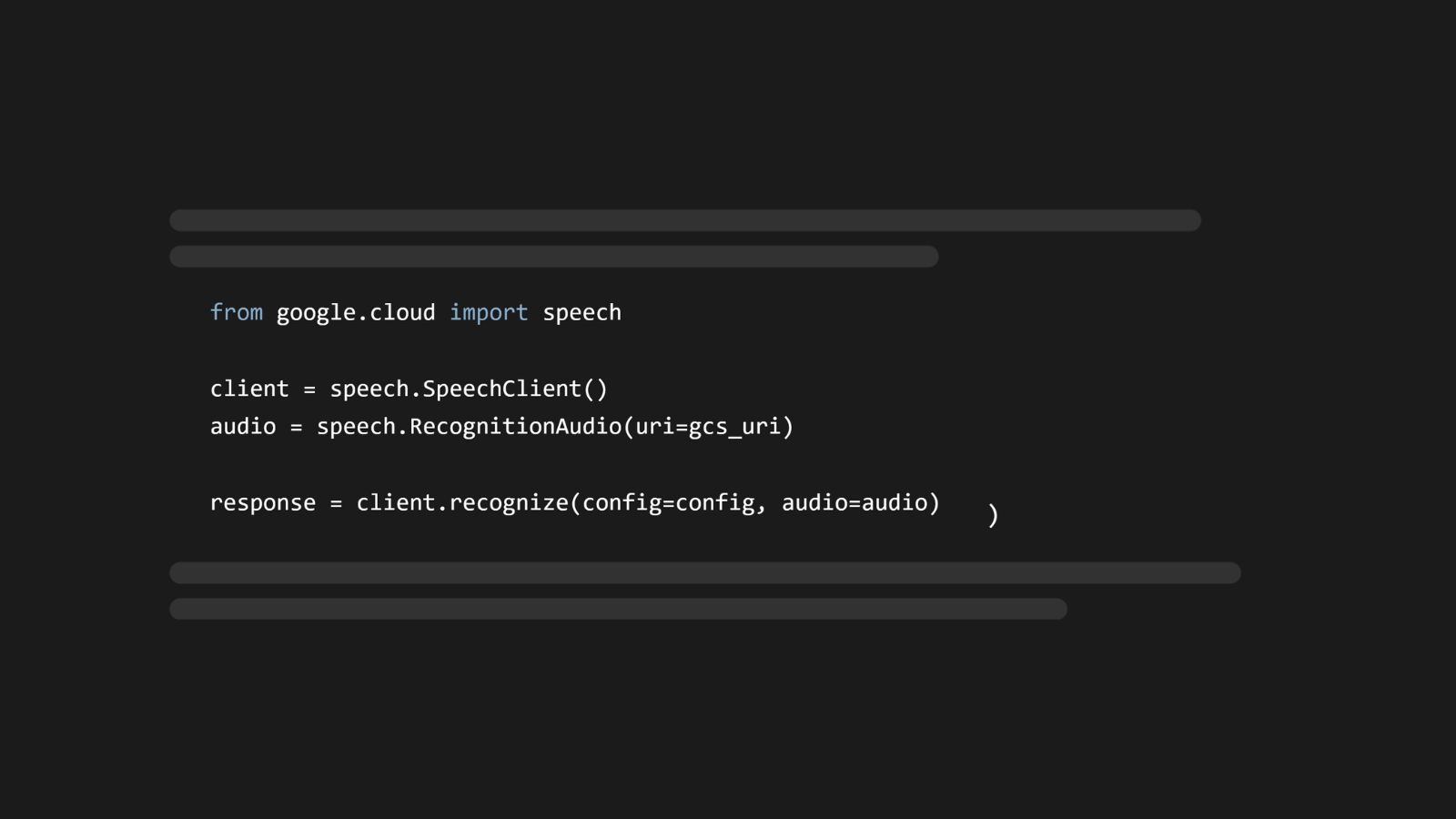
Learn how to set up a Google Cloud project to transcribe both local and remote audio files using Google's Speech-to-Text API and Python

Stop manually creating subtitles for your videos, and learn how to auto-generate them with Python and AssemblyAI in this tutorial.

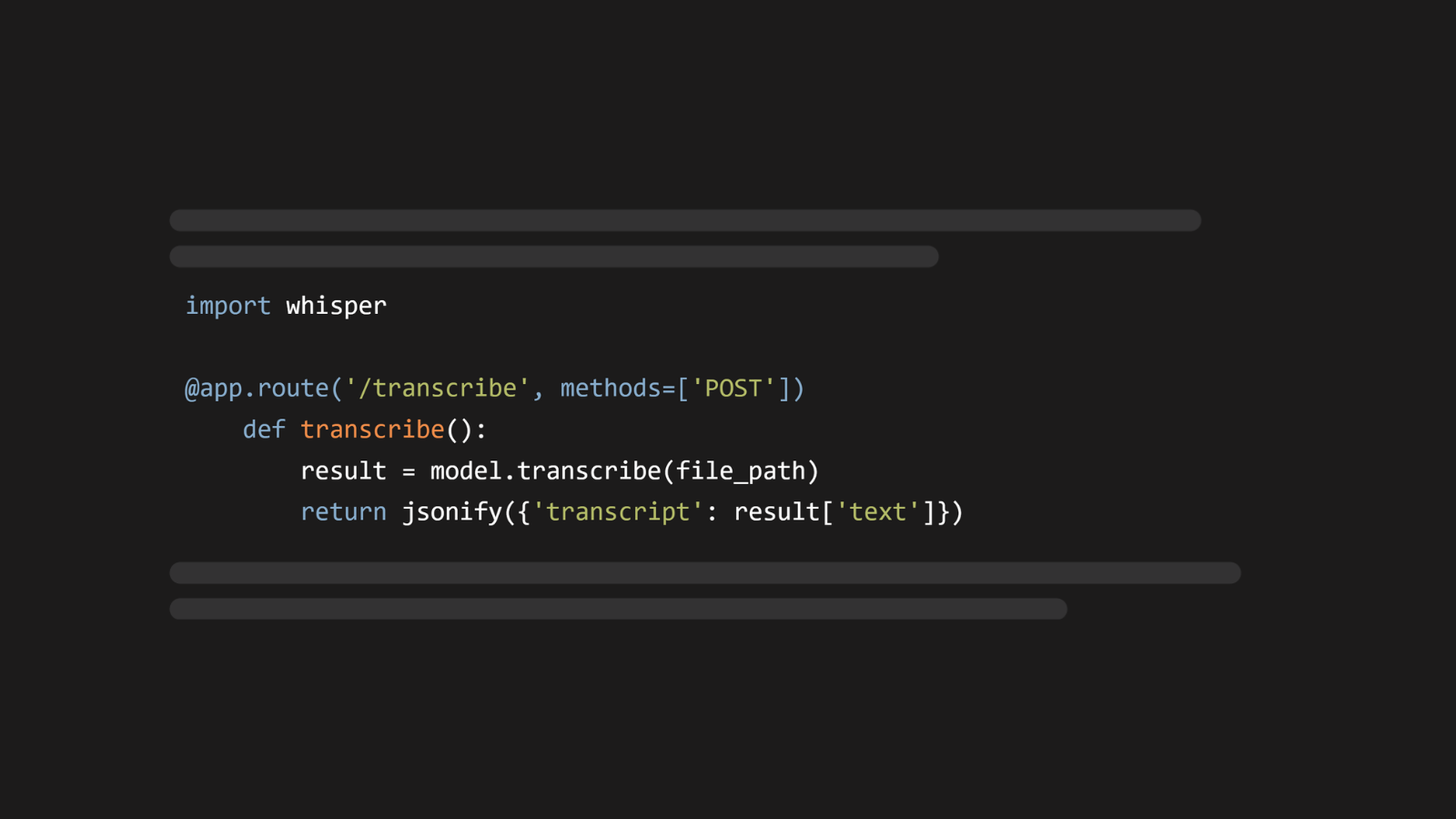
Learn how to make a free, GPU-powered Whisper API for transcribing audio files

Learn how to integrate Speech-to-Text functionality into Django and build an example app.


Learn how to use Python to automatically identify languages in audio files.

Learn how to use Python to perform speaker diarization on audio and video files to identify "who said what when"

Learn the differences between speaker diarization and speaker recognition, as well as speaker verification and speaker identification in audio analysis

Build a sophisticated Discord voice bot that leverages AssemblyAI for speech transcription, OpenAI's GPT-3.5 Turbo AI model for intelligent processing, and ElevenLabs for speech synthesis.


Learn how to analyze audio from Zoom calls using AssemblyAI and Node.js.


Large Language Models are trained to guess the next word. But when generating text, the combination of their probability estimates with algorithms known as decoding strategies is what determines how they actually choose words. Learn how decoding strategies work in this article.


Learn about the best audio and video formats for speech-to-text applications, as well as best practices for audio post-processing techniques.
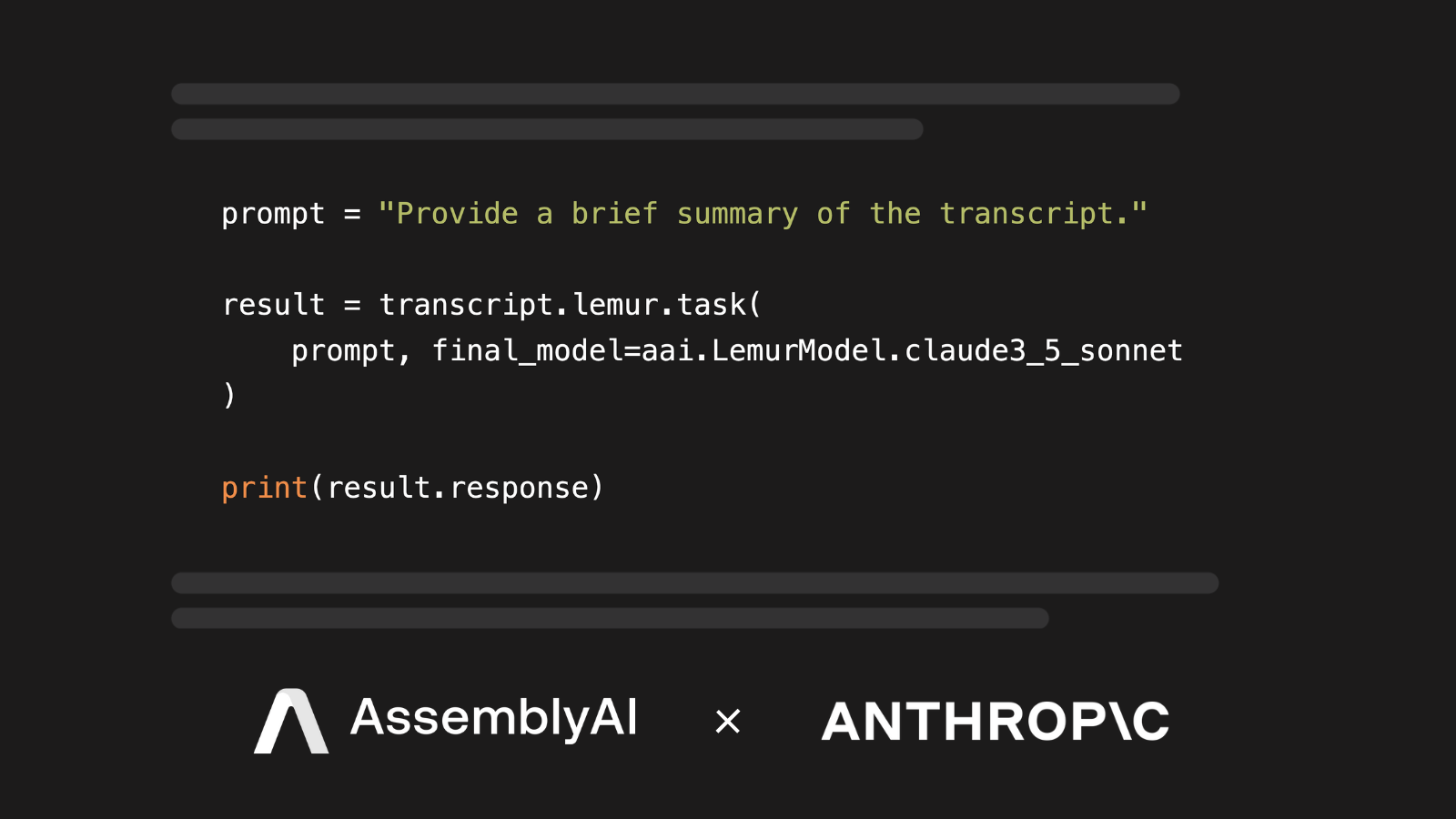
Learn how to use the Claude 3 models with audio and video data in Python.

Microsoft's Florence-2 is a foundational image model that can perform almost every common task in computer vision. Learn how Florence-2 works and how to use it in this guide.

Learn how to translate speech in real-time in JavaScript with AssemblyAI and DeepL.


Learn how to build a web app in Go that'll use AssemblyAI to transcribe an uploaded video file and generate subtitles.
Learn how to build a Next.js video conferencing app that supports video calls with live transcriptions and an LLM-powered meeting assistant.


In this tutorial, you'll learn how to respond to hotwords in voice data using Streaming Speech-to-Text in Go.


Modern AI models make it easy to automatically detect the presence of sensitive topics in speech data. Learn how to perform configurable content moderation with Python in this tutorial.