Auto-tweet your words using speech recognition in Python
Build a Python app that auto-tweets your spoken words using AssemblyAI's Universal-Streaming API.


We say the funniest things when no one is listening. But what if someone did, all the time? In this article, we will learn how to make an app that will listen to you and tweet the funniest, smartest or most relatable things you say out loud.
The app will work by listening to you and transcribing your sentences. After you say something you would like to tweet, you can say the keyword "tweet" and it will post your latest sentence on X (formerly Twitter).
We will make the app with Python using AssemblyAI's industry-leading Universal-Streaming speech-to-text model, which delivers ultra-fast, ultra-accurate transcription with ~300ms latency and immutable transcripts perfect for real-time applications.
The main libraries will be:
- PyAudio for listening to the input source
- Tweepy for easy use of the X API
- AssemblyAI's Universal-Streaming for Speech-to-Text transcription
Setting up the dependencies
Before coding at all, we need X and AssemblyAI credentials. Getting an AssemblyAI API token is very simple. Just sign up for AssemblyAI and log in to find your token. New users get $50 in free credits to get started.
In order to use the X API, go to the X Developer Portal and create an account. After providing some information to X, you need to create a project and get the necessary credentials. For this project, you need read and write permissions.
There will be two files in this project. The main Python script and a configuration file. Fill in your configuration file with the authentication key from AssemblyAI and other credentials from X like so:
# configure.py
auth_key = 'your_assemblyai_api_key_here'
consumer_key = 'your_X_consumer_key'
consumer_secret = 'your_X_consumer_secret'
access_token = 'your_X_access_token'
access_token_secret = 'your_X_access_token_secret'
In the main script, we start by importing all the libraries we need.
import re
import string
import pyaudio
import websocket
import json
import threading
import time
import wave
import tweepy
from urllib.parse import urlencode
from datetime import datetime
from configure import (
auth_key,
consumer_key,
consumer_secret,
access_token,
access_token_secret
)
Audio configuration
Next up is setting up the parameters of PyAudio and the WebSocket.
CONNECTION_PARAMS = {
"sample_rate": 16000,
"format_turns": True, # request formatted final turns
}
API_ENDPOINT_BASE_URL = "wss://streaming.assemblyai.com/v3/ws"
API_ENDPOINT = f"{API_ENDPOINT_BASE_URL}?{urlencode(CONNECTION_PARAMS)}"
# Audio Configuration
FRAMES_PER_BUFFER = 800 # 50ms at 16kHz
SAMPLE_RATE = CONNECTION_PARAMS["sample_rate"]
CHANNELS = 1
FORMAT = pyaudio.paInt16
audio = None
stream = None
ws_app = None
audio_thread = None
stop_event = threading.Event()
The main point to pay attention to here is the SAMPLE_RATE parameter. When setting up the connection to AssemblyAI's Universal-Streaming endpoint, the same sample rate needs to be specified. Since sentences will be transcribed in real-time with immutable results, we'll use AssemblyAI's Universal-Streaming endpoint.
Connecting to X
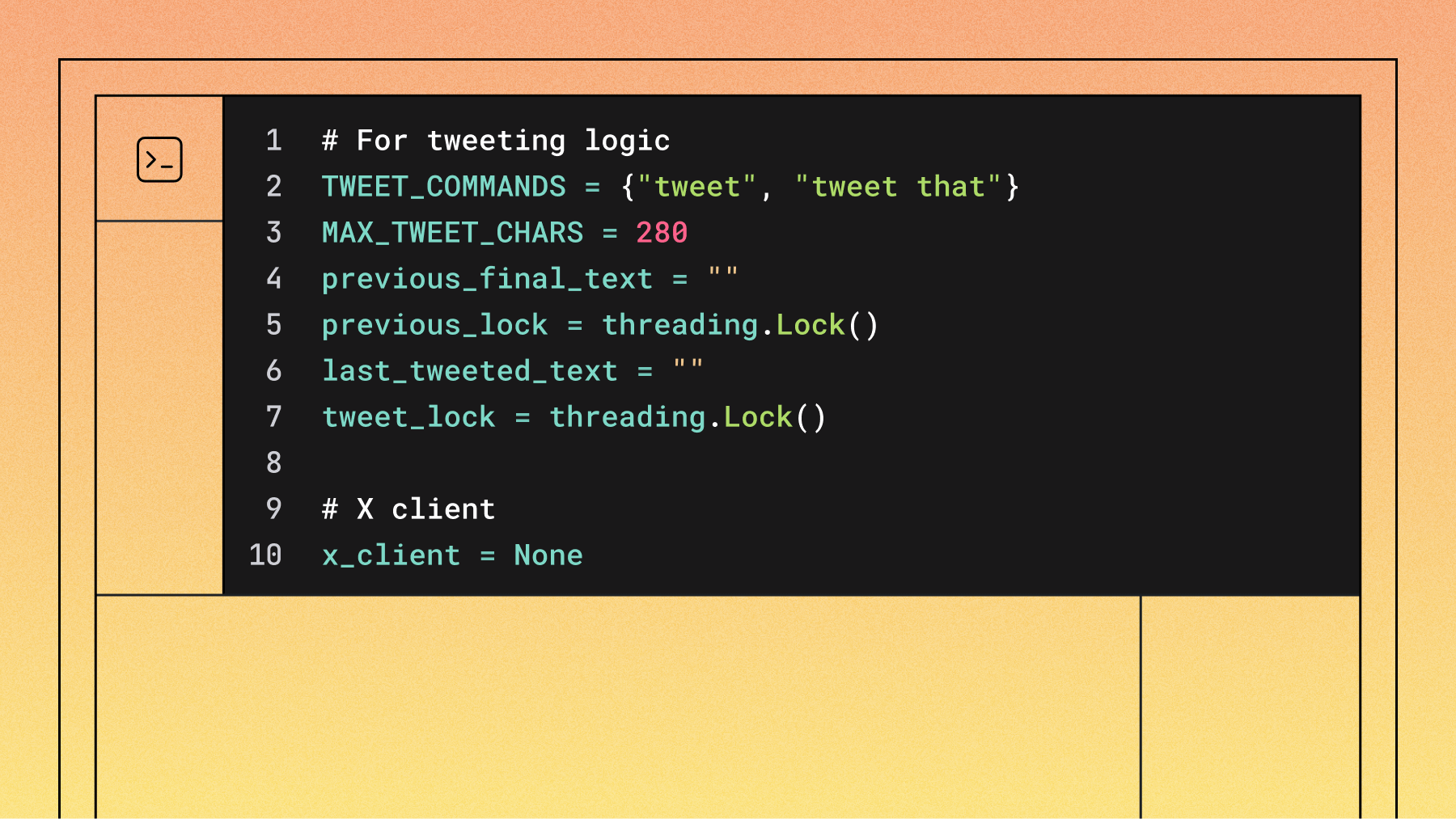
This section sets up the core functionality for detecting tweet commands and posting to X (formerly Twitter). The code defines two main command patterns: a simple "tweet" or “tweet that” command that posts previously recognized speech. The try_command_and_extract_payload() function uses regex patterns to identify tweet commands, and we use the Tweepy library to handle authentication and posting.
# For tweeting logic
TWEET_COMMANDS = {"tweet", "tweet that"}
MAX_TWEET_CHARS = 280
previous_final_text = ""
previous_lock = threading.Lock()
last_tweeted_text = ""
tweet_lock = threading.Lock()
# X client
x_client = None
# ===================== Helpers =====================
def make_x_client():
client = tweepy.Client(
consumer_key=consumer_key,
consumer_secret=consumer_secret,
access_token=access_token,
access_token_secret=access_token_secret,
wait_on_rate_limit=True,
)
return client
def tweet_text(client: tweepy.Client, text: str):
txt = (text or "").strip()
if not txt:
print("Refusing to tweet empty text.")
return
if len(txt) > MAX_TWEET_CHARS:
txt = txt[: MAX_TWEET_CHARS - 1] + "…"
try:
print(f"Posting tweet: {repr(txt)}")
resp = client.create_tweet(text=txt)
tweet_id = getattr(resp, "data", {}).get("id", None)
if tweet_id:
print(f"Tweeted (id={tweet_id}): {txt}")
else:
print(f"Tweeted: {txt}")
except Exception as e:
print("Tweet failed:", repr(e))
def try_command_and_extract_payload(text: str):
"""
Returns (is_command, payload_after_command_or_None).
Matches:
- 'tweet' / 'tweet that' (+ optional punctuation)
- 'tweet that <payload>' (tweets <payload> directly)
"""
if not text:
return (False, None)
s = text.strip()
# Pure command with optional punctuation, case-insensitive
if
re.fullmatch(r'(?i)\s*tweet(\s+that)?\s*[\.\!\?\'"\u2019\u201D]*\s*',
s):
return (True, None)
# Command + payload (payload ends before trailing punctuation)
m =
re.match(r'(?i)^\s*tweet(\s+that)?\s+(.+?)\s*[\.\!\?\'"\u2019\u201D]*\s*
$', s)
if m:
payload = m.group(2).strip()
if payload and payload.strip(string.punctuation + " "):
return (True, payload)
return (False, None)
This foundation allows your speech-to-tweet application to reliably process voice commands and convert them into social media posts with proper error handling and user feedback.
Establishing the WebSocket connection
Our application uses WebSocket connections to maintain a persistent connection with AssemblyAI's streaming service. We'll need four main handler functions to manage the connection lifecycle and process incoming messages.The on_open function is called when our WebSocket connection is successfully established with AssemblyAI's servers.
def on_open(ws):
"""Called when the WebSocket connection is established."""
print("WebSocket connection opened.")
print(f"Connected to: {API_ENDPOINT}")
def stream_audio():
global stream
print("Starting audio streaming...")
while not stop_event.is_set():
try:
audio_data = stream.read(FRAMES_PER_BUFFER,
exception_on_overflow=False)
# send raw PCM 16-bit mono as binary frame
ws.send(audio_data, websocket.ABNF.OPCODE_BINARY)
except Exception as e:
print(f"Error streaming audio: {e}")
break
print("Audio streaming stopped.")
global audio_thread
audio_thread = threading.Thread(target=stream_audio, daemon=True)
audio_thread.start()
Once connected, this function immediately starts streaming audio data. The key improvement here is that we're sending raw PCM audio data as binary frames directly to AssemblyAI, rather than encoding it as JSON. This creates a more efficient streaming experience with lower latency.
Processing transcription results
The heart of our application lies in the on_message function, which processes all incoming messages from AssemblyAI's streaming service.
def on_message(ws, message):
global previous_final_text, x_client, last_tweeted_text
try:
data = json.loads(message)
except json.JSONDecodeError:
return # ignore non-JSON frames
msg_type = data.get('type')
if msg_type == "Begin":
session_id = data.get('id')
expires_at = data.get('expires_at')
if expires_at is not None:
print(f"\nSession began: ID={session_id},
ExpiresAt={datetime.fromtimestamp(expires_at)}")
else:
print(f"\nSession began: ID={session_id}")
The new streaming API provides structured message types that give us much more control over the transcription process. When a session begins, we receive important metadata like the session ID and expiration time.
Handling real-time transcripts
The most exciting part is processing the actual transcription results. The API sends us both partial results (as you're speaking) and final results (when you finish a sentence).
elif msg_type == "Turn":
transcript = data.get('transcript', '')
formatted = data.get('turn_is_formatted', False)
if formatted:
# Clear previous line then print final
print('\r' + ' ' * 80 + '\r', end='')
final_text = (transcript or "").strip()
print(final_text)
print("FINAL TEXT (repr):", repr(final_text))
is_cmd, payload =
try_command_and_extract_payload(final_text)
if is_cmd:
print("Command detected.")
if payload:
# Same-turn payload: tweet what follows 'tweet
that'
with tweet_lock:
if payload != last_tweeted_text:
if x_client is None:
print("X client not initialized;
cannot tweet.")
else:
tweet_text(x_client, payload)
last_tweeted_text = payload
else:
print("Skipping duplicate tweet (same
content).")
When turn_is_formatted is true, we know this is a final, polished transcript. At this point, we check if the user said a tweet command. Our application supports two types of commands: saying "tweet" or "tweet that" to post the previous sentence.
Displaying live transcription
For partial results, we create a dynamic display that updates in real-time as you speak:
else:
# Interim partials: overwrite the same console line
print(f"\r{transcript}", end='')
This creates a user experience where you can see your words appearing on screen as you speak, before they're finalized and tweeted.
Managing session lifecycle
The API also tells us when sessions end and provides useful statistics:
elif msg_type == "Termination":
audio_duration = data.get('audio_duration_seconds', 0)
session_duration = data.get('session_duration_seconds', 0)
print(f"\nSession Terminated: Audio
Duration={audio_duration}s, Session
Duration={session_duration}s")
This information is valuable for understanding how much audio was processed and optimizing performance.
Error handling and connection management
Robust error handling ensures our application gracefully manages connection issues:
def on_error(ws, error):
print(f"\nWebSocket Error: {error}")
stop_event.set()
def on_close(ws, close_status_code, close_msg):
print(f"\nWebSocket Disconnected: Status={close_status_code},
Msg={close_msg}")
global stream, audio
stop_event.set()
if stream:
if stream.is_active():
stream.stop_stream()
stream.close()
stream = None
if audio:
audio.terminate()
audio = None
When connections close or errors occur, we properly clean up all audio resources and stop background threads.
Running the application
The main function ties everything together, initializing our microphone, WebSocket connection, and Twitter client:
def run():
global audio, stream, ws_app, x_client
# Initialize X client
x_client = make_x_client()
# Initialize PyAudio
audio = pyaudio.PyAudio()
try:
stream = audio.open(
input=True,
frames_per_buffer=FRAMES_PER_BUFFER,
channels=CHANNELS,
format=FORMAT,
rate=SAMPLE_RATE,
)
print("Microphone stream opened successfully.")
print("Speak into your microphone. Press Ctrl+C to stop.")
print("Say 'tweet' or 'tweet that' to post the PREVIOUS finalized
utterance to X,")
print("or say 'tweet that <text>' to post <text> directly.")
After setting up the audio stream, we create our WebSocket connection with all the handler functions we defined:
# Create WebSocketApp
ws_app = websocket.WebSocketApp(
API_ENDPOINT,
header={"Authorization": auth_key},
on_open=on_open,
on_message=on_message,
on_error=on_error,
on_close=on_close,
)
# Run WebSocketApp in a separate thread
ws_thread = threading.Thread(target=ws_app.run_forever, daemon=True)
ws_thread.start()
The application runs the WebSocket connection in a separate thread, allowing the main thread to handle user interrupts and cleanup.
Graceful Shutdown
When the user presses Ctrl+C, our application performs a clean shutdown:
except KeyboardInterrupt:
print("\nCtrl+C received. Stopping...")
stop_event.set()
# Ask server to terminate gracefully
if ws_app and ws_app.sock and ws_app.sock.connected:
try:
terminate_message = {"type": "Terminate"}
print(f"Sending termination message:
{json.dumps(terminate_message)}")
ws_app.send(json.dumps(terminate_message))
time.sleep(5)
except Exception as e:
print(f"Error sending termination message: {e}")
We send a termination message to AssemblyAI's servers before closing the connection, ensuring proper cleanup on both ends.
Key improvements with Universal-Streaming
This updated implementation leverages several advantages of AssemblyAI's Universal-Streaming:
- Immutable transcripts: Results are final from the start, no revisions
- Ultra-low latency: ~300ms response time for better user experience
- Superior accuracy: Industry-leading accuracy with proper nouns and formatting
- Cost-effective: $0.15/hour pricing with unlimited concurrent streams
- Enhanced reliability: Built for production voice applications
Production considerations
For production deployment, consider these additional features:
- Temporary tokens: For client-side applications, use temporary authentication tokens instead of exposing your API key
- Connection management: Implement reconnection logic for dropped connections
- Rate limiting: Monitor your usage to stay within X API limits
- Error recovery: Add more sophisticated error handling and retry logic
You can find the complete updated code on GitHub.
AssemblyAI's Universal-Streaming makes building real-time voice applications like this auto-tweeter both technically straightforward and cost-effective, enabling developers to focus on creating unique user experiences rather than wrestling with speech recognition infrastructure.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts