Real-Time is now Streaming Speech-to-Text, with added customization and control for users
Streaming Speech-to-Text makes it easier than ever to transcribe live audio and videos, now with customizable end-of-utterance detection at a lower cost.



Significant advancements in Voice AI research are making live Speech-to-Text transcription more accurate than ever before. This has led to growing demand for high-quality AI tools, such as AI voice bots for call centers and voice assistants for customer service, that leverage live Speech-to-Text technology.
With AssemblyAI’s Streaming Speech-to-Text (previously Real-Time) model, users can expect to build with the same powerful technology under a new name and a few improvements:
- More customization and control
- Lower cost to build (which was originally announced this past January)
These updates make it easier to build next-generation AI tools and products on top of live speech transcription.
Advanced use cases for Streaming Speech-to-Text
Historically, live Speech-to-Text users only had access to limited AI technology and were not content with how stilted and unnatural conversations felt when using other tools.
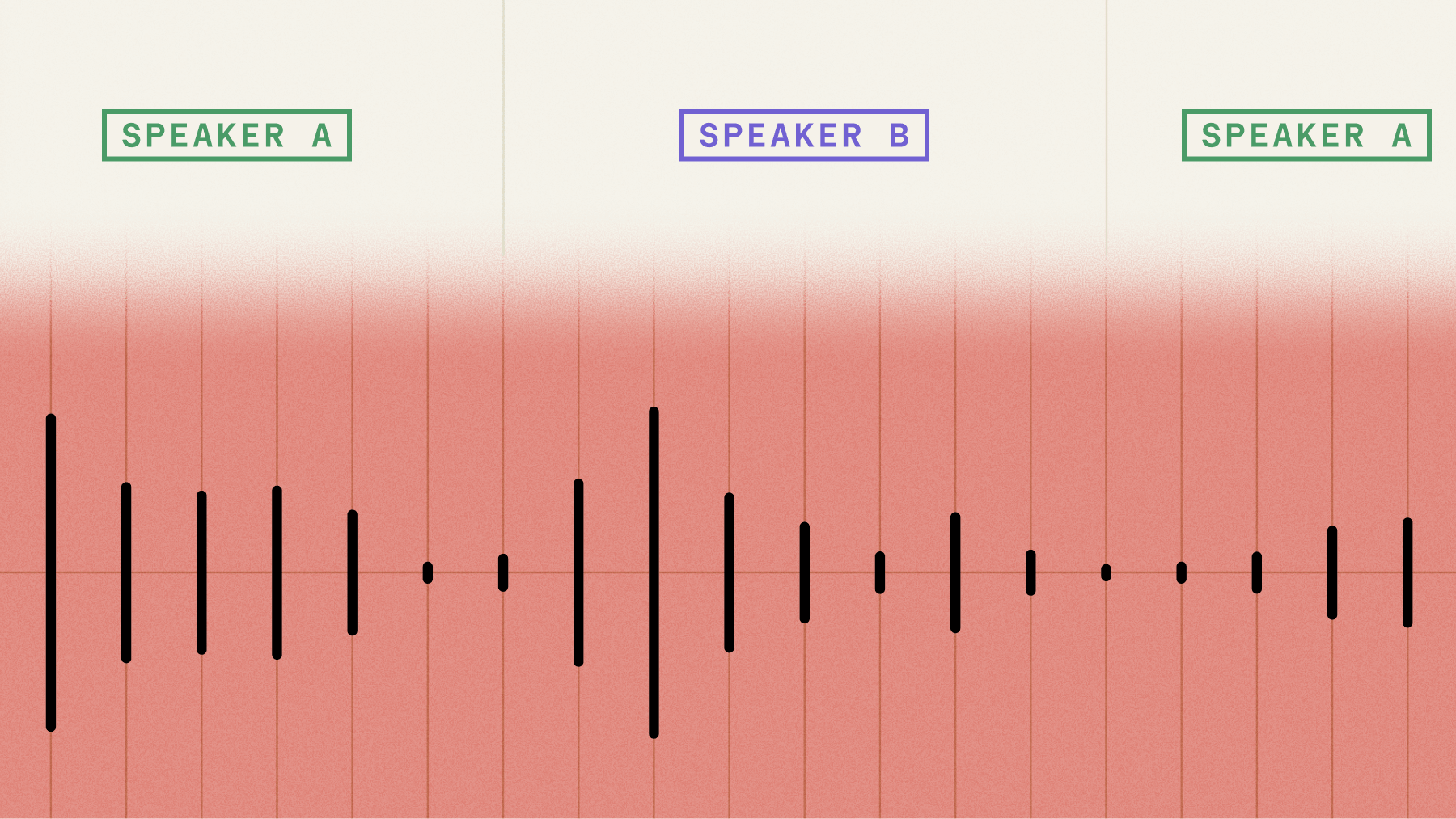
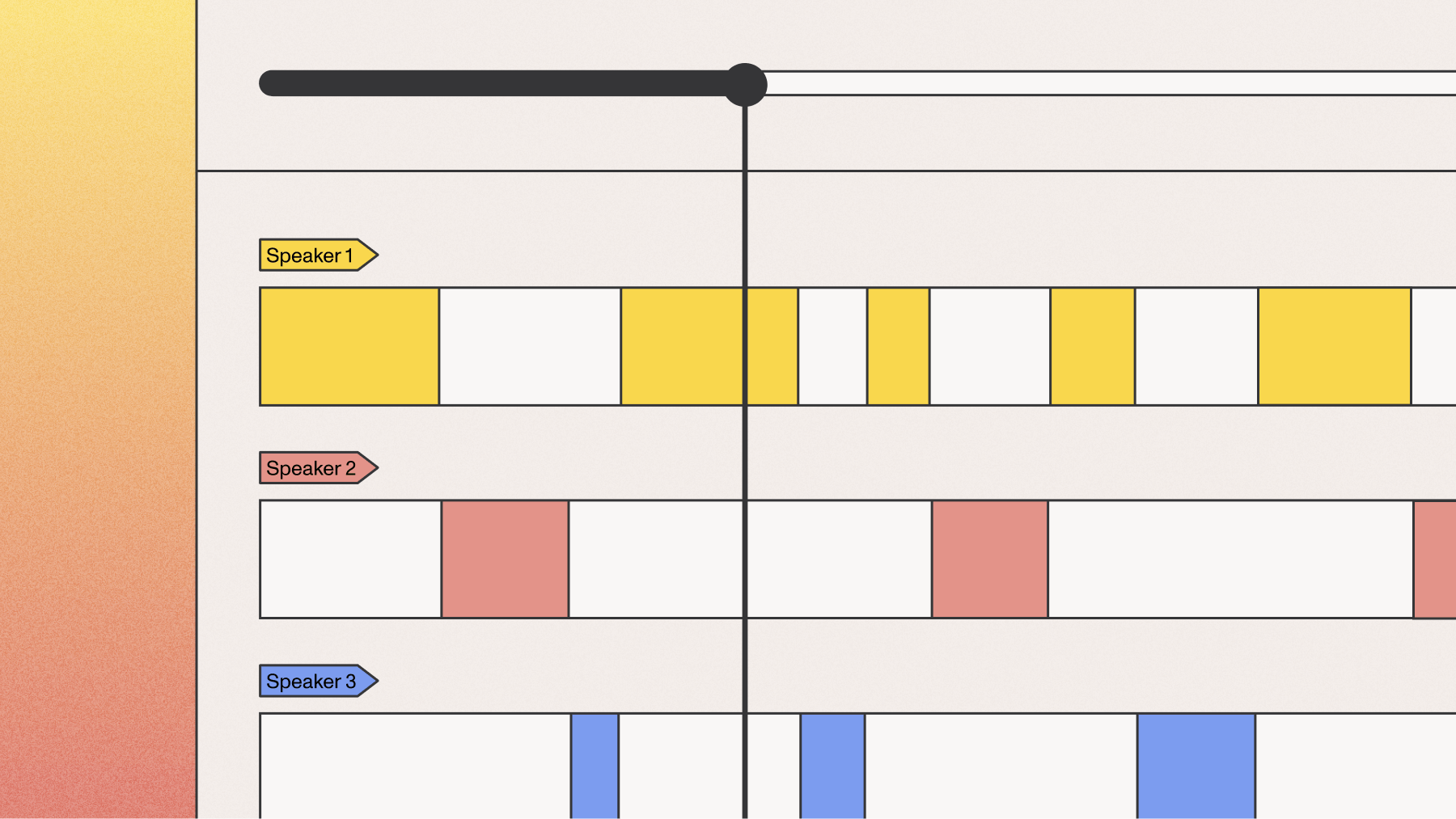
AssemblyAI’s Streaming Speech-to-Text (Streaming STT) offers a best-in-class experience for users who are looking for a seamless option. Streaming STT includes accurate, customizable end-of-utterance detection, which ensures that conversations are transcribed more naturally to enable better AI-human interactions.
Companies are now using Streaming STT for a variety of purposes:
- Live captions for streaming audio and video
- AI voice assistants and voice bots for customer service, call centers and sales applications
- Language learning tools
- Accessibility applications
- Virtual meetings
Start Building with Streaming Speech-to-Text
Transform your applications with real-time audio transcription. Sign up now to access AssemblyAI's powerful Streaming STT API.
Sign up to unlock $50 in credits
How to customize end-of-utterance detection
End-of-utterance detection enables the live speech-to-text model to identify when the human is finished speaking.
With our recent update to Streaming STT, developers can now customize how and when a speaker is done talking.
Developers can modify end-of-utterance detection in two ways:
- By deciding that the model will wait for less (or more) silence to transpire before declaring that the speaker is done speaking. This is accomplished by modifying the parameters displayed in the commented line.
import assemblyai as aai transcriber = aai.RealtimeTranscriber( on_data=on_data_callback, on_error=on_error_callback, sample_rate=sample_rate, end_utterance_silence_threshold=300 # Custom threshold for end of utterance detection ) transcriber.connect() audio_stream = ... for audio_chunk in audio_stream: transcriber.stream(audio_chunk)
- By forcing an end of utterance to happen programmatically. This is accomplished by modifying the parameters displayed in the commented line.
import assemblyai as aai transcriber = aai.RealtimeTranscriber( on_data=on_data_callback, on_error=on_error_callback, sample_rate=sample_rate, ) transcriber.connect() audio_stream = ... for audio_chunk in audio_stream: transcriber.stream(audio_chunk) speaker_changed = ... if speaker_changed: transcriber.force_end_utterance() # Steers the model to produce a final transcript
With these new controls, developers can build more natural interactions with their AI tools, giving their users a better overall experience with live Speech-to-Text applications.
Unlock powerful live Speech-to-Text use cases with faster, lower-cost STT
Streaming Speech-to-Text allows users to transcribe live audio streams with high accuracy and low latency at a lower price of $0.47 per hour (reduced from $0.75 per hour), or $0.0001306 per second, of audio data. This includes access to the Streaming Speech-to-Text model, Automatic Punctuation and Casing, and Custom Vocabulary.
To use the service, users stream audio data to our secure WebSocket API and receive transcripts back within a few hundred milliseconds.
Users can follow along with step-by-step instructions in our docs to get started, or by using one of our official SDKs.
Try Streaming Speech-to-Text for free in our no-code playground. Try it here
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts