
Automatically determine video sections with AI using Python
In this tutorial, we will learn how to automatically determine video sections, how to generate section titles with LLMs, and how to format the information for YouTube chapters.



Video segmentation is the process of splitting a video into semantically-isolated sections. For example, if we have a video of a virtual meeting, then video segmentation would involve determining the timestamps at which new topics are discussed in the meeting. By doing so, we can make it easy for watchers to browse the video sections to easily find the information they are looking for.
YouTube implements video segmentation through its YouTube Chapters feature. The video sections are determined either automatically by YouTube, or set by creators manually.
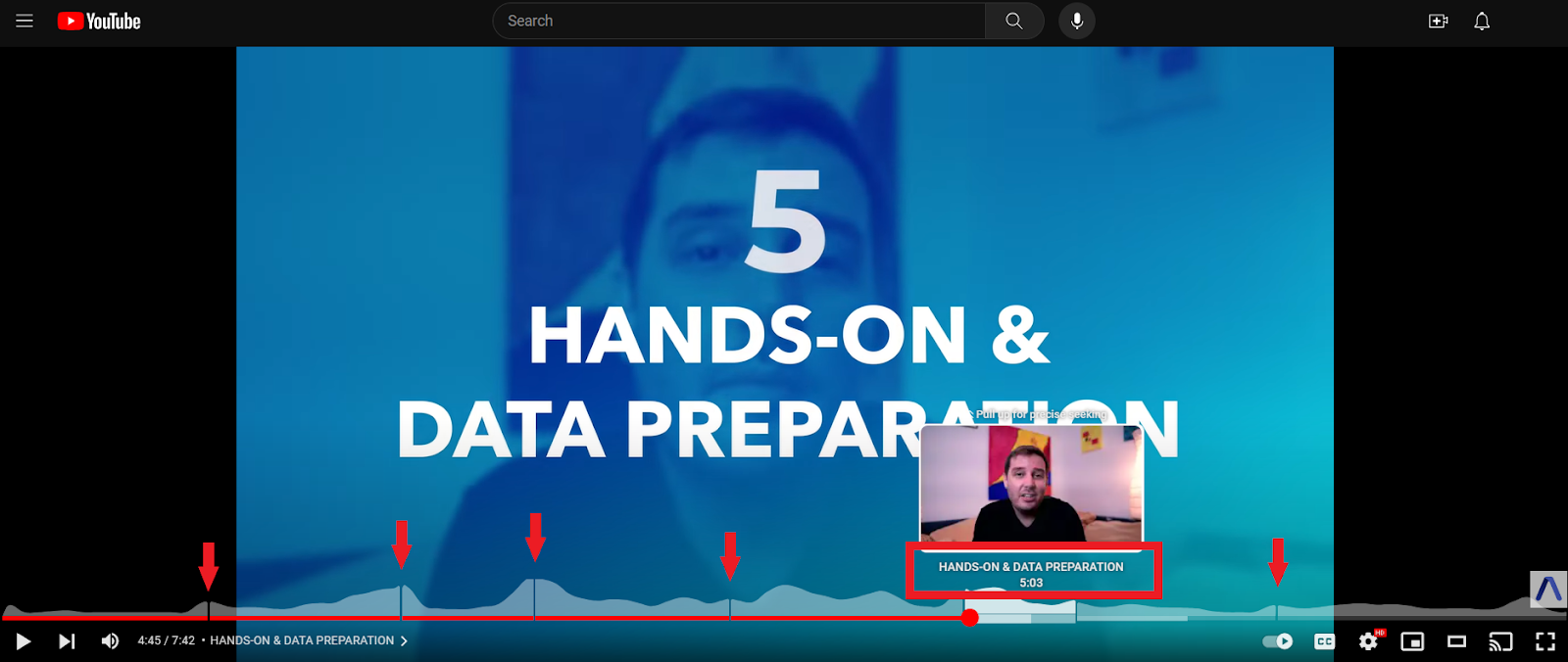
In this tutorial, we will learn how to automatically perform video segmentation using Python. Additionally, we'll learn how to use LLMs to generate improved section titles. We will work with a virtual meeting file, where the end result is shown below:
00:00 Proposing Department Key Reviews
01:40 Clarifying Merge Request Rate Definitions
03:51 Fixing the Wider Merge Request Rate Metric
08:18 Confirming Wider Rate is Community-Only
08:40 Data Team Lag Issues
09:40 Discussing Postgres Replication
13:05 Defect Tracking and SLO Update
18:32 Smaller Security Metric Decline Seen as Improvement
20:42 Investigating Below-Target Narrow Merge Request Rate
23:50 Wrapping Up the MeetingBoth the timestamps and video section titles above were automatically generated - the only input is an audio or video file. You can find all of the code for this tutorial in this repository.
Getting started
First, create a project directory and navigate into it. Then, create a virtual environment:
# Mac/Linux:
python3 -m venv venv
. venv/bin/activate
# Windows:
python -m venv venv
.\venv\Scripts\activate.batNext, install the AssemblyAI Python SDK:
pip install assemblyaiThen set your AssemblyAI API Key as an environment variable. You can get an AssemblyAI API key here for free.
# Mac/Linux:
export ASSEMBLYAI_API_KEY=<YOUR_KEY>
# Windows:
set ASSEMBLYAI_API_KEY=<YOUR_KEY>Transcribing the meeting
In your project directory, create a file called main.py. For this project, we will be using video of a GitLab meeting. Add the below code to main.py, which transcribes the meeting:
import assemblyai as aai
# we add a TranscriptionConfig to turn on Auto Chapters
transcriber = aai.Transcriber(
config=aai.TranscriptionConfig(auto_chapters=True)
)
transcript = transcriber.transcribe(
"https://storage.googleapis.com/aai-web-samples/meeting.mp4"
)
if transcript.error: raise RuntimeError(transcript.error)First, we create a Transcriber object, which will handle creating our transcription for us. We give it a TranscriptConfig that sets auto_chapters=True to tell the transcriber to use AssemblyAI’s Auto Chapters model when it is creating the transcription. This model automatically determines the chapters, i.e. video sections, of audio or video files.
Then, we use the transcriber’s transcribe method to create a transcript, where we pass in the URL of the file that we want to transcribe. You can use either a remote file as we have done here, or a local file by specifying its filepath.
We can access the transcript text with transcript.text, and we can find all of the video sections information through the chapters attribute of the transcript:
# print the text
print(transcript.text, end='\n\n')
# now we print the video sections information
for chapter in transcript.chapters:
print(f"Start: {chapter.start}, End: {chapter.end}")
print(f"Summary: {chapter.summary}")
print(f"Healine: {chapter.headline}")
print(f"Gist: {chapter.gist}")The start and end attributes of a given chapter provide the times, in milliseconds, at which the chapter starts and ends. summary, headline, and gist each provide a summary of the chapter of different lengths, descending in magnitude from a paragraph to just a few words.
Turning video sections into YouTube Chapters
Now that we have our timestamp information, we can prepare it in any way we like. The final format will of course depend on the final application - for this example, we will see how to format the Auto Chapters information into YouTube Chapters information, where each video section will be a distinct Chapter.
YouTube Chapter timestamp formatting
For manual timestamps, YouTube requires the timestamps to be formatted as HH:MM:SS for videos longer than an hour and as MM:SS for videos less than an hour. Given that AssemblyAI's API returns the timestamp information in milliseconds, we first need to write a small function that turns a time in milliseconds into its equivalent number of hours, minutes, and seconds. Add the following function to main.py:
def ms_to_hms(start):
s, ms = divmod(start, 1000)
m, s = divmod(s, 60)
h, m = divmod(m, 60)
return h, m, sIn more detail, YouTube expects, for manual Chapter specification, a sequence of lines in the video description, where each line has the form:
(HH):MM:SS <CHAPTER_TITLE>The parentheses around HH denote that this value is optional and depends on the length of the video, as mentioned above.
We’ll now write a function to prepare the Auto Chapters information returned by AssemblyAI’s API in this fashion. We will use each chapter's headline as its title for now:
def create_timestamps(chapters):
last_hour = ms_to_hms(chapters[-1].start)[0]
time_format = "{m:02d}:{s:02d}" if last_hour == 0 else "{h:02d}:{m:02d}:{s:02d}"
lines = []
for idx, chapter in enumerate(chapters):
# first YouTube timestamp must be at zero
h, m, s = (0, 0, 0) if idx == 0 else ms_to_hms(chapter.start)
lines.append(f"{time_format.format(h=h, m=m, s=s)} {chapter.headline}")
return "\n".join(lines)Then we can print the results:
timestamp_lines = create_timestamps(transcript.chapters)
print(timestamp_lines)Execute the program by running python main.py in your terminal. Now, we should see this response:
00:00 Eric Johnson proposes breaking up GitLab meeting into four department key reviews
01:40 R D wider Mr rate includes both community contributions and community Mrs
03:51 R and D wider Mr rate should be contributions per GitLab team member
08:18 Roman Ram: I think wider only counts for community
08:40 There's apparently a lag issue that's been problematic for the data team
09:40 I wanted to touch on the postgres replication issue there real quick
13:05 We are working on the measurement for average open bugs age
18:32 Security metrics had their smallest decline over several quarters, so we see improvement
20:42 The narrow Mr rate seems significantly below target, and maybe
23:50 Eric: Well said. Thanks, Eric. All cool. All right, that's it for the agenda
Improving results with LeMUR
The above results are a good start, but each section title is not very succinct. We can improve the results by leveraging the capabilities of LLMs, which is easy to do again using the AssemblyAI Python SDK.
In particular, we’ll use LeMUR to improve up the results. We define a custom task that tells LeMUR to modify the section titles to make them catchier:
prompt = f"""
ROLE:
You are a YouTube content professional. You are very competent and able to come up with catchy names for the different sections of video transcripts that are submitted to you.
CONTEXT:
This transcript is of a logistics meeting at GitLab
INSTRUCTION:
You are provided information about the sections of the transcript under TIMESTAMPS, where the format for each line is `<TIMESTAMP> <SECTION SUMMARY>`."
TIMESTAMPS:
{timestamp_lines}
FORMAT:
<TIMESTAMP> <CATCHY SECTION TITLE>
OUTPUT:
""".strip()Next, we feed this task to LeMUR using the .lemur.task method of our transcript object:
result = transcript.lemur.task(prompt)
# Extract the response text and print
output = result.response.strip()
print(output)Here are the results:
Here are catchy section titles for the transcript timestamps:
00:00 Proposing Department Key Reviews
01:40 Clarifying Merge Request Rate Definitions
03:51 Fixing the Wider Merge Request Rate Metric
08:18 Confirming Wider Rate is Community-Only
08:40 Data Team Lag Issues
09:40 Discussing Postgres Replication
13:05 Defect Tracking and SLO Update
18:32 Smaller Security Metric Decline Seen as Improvement
20:42 Investigating Below-Target Narrow Merge Request Rate
23:50 Wrapping Up the MeetingRegex and verification
Sometimes an LLM will return a "preamble" before the main contents of its response. We can filter out the preamble and any extraneous text with a regex:
import re
def filter_timestamps(text):
lines = text.splitlines()
timestamped_lines = [line for line in lines if re.match(r'\d+:\d+', line)] # Use regex to filter lines starting with a timestamp
filtered_text = '\n'.join(timestamped_lines)
return filtered_text
filtered_output = filter_timestamps(output)Finally, since LLMs are inherently probabilistic, we need to go back through and verify that none of the timestamps were changed from those provided by the original Auto Chapters model:
original = timestamp_lines.splitlines()
filtered = filtered_output.splitlines()
for o, f in zip(original, filtered):
original_time = o.split(' ')[0]
filtered_time = f.split(' ')[0]
if not original_time == filtered_time:
raise RuntimeError(f"Timestamp mismatch - original timestamp '{original_time}' does not match LLM timestamp '{filtered_time}'")
print(filtered_output)We iterate through each line of the Auto Chapters output and the LeMUR output and verify that the timestamps match. If they do not, we raise an error. After this check, we are left with our final, succinct, verified timestamps. When we run our program with python main.py in the terminal, we will see the following output:
00:00 Proposing Department Key Reviews
01:40 Clarifying Merge Request Rate Definitions
03:51 Fixing the Wider Merge Request Rate Metric
08:18 Confirming Wider Rate is Community-Only
08:40 Data Team Lag Issues
09:40 Discussing Postgres Replication
13:05 Defect Tracking and SLO Update
18:32 Smaller Security Metric Decline Seen as Improvement
20:42 Investigating Below-Target Narrow Merge Request Rate
23:50 Wrapping Up the MeetingThese timestamps can be copy-and-pasted into a YouTube video description to create manual timestamps, or you can use the YouTube API to programmatically add them.
Final words
In this tutorial, we learned how to use AssemblyAI’s Auto Chapters model in Python. We learned how to format the results in a YouTube Chapters compatible format, and how to improve the names of the video sections using LeMUR.
To learn how to use other features of AssemblyAI’s API, check out some of our other blogs like Key phrase detection in audio files using Python or our documentation.
Alternatively, check out other content on our Blog or YouTube channel to learn more about AI, or feel free to join us on Twitter or Discord to stay in the loop when we release new content.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.




