How Reinforcement Learning from AI Feedback works
Reinforcement Learning from AI Feedback (RLAIF) is a supervision technique that uses a "constitution" to make AI assistants like ChatGPT safer. Learn everything you need to know about RLAIF in this guide.



In recent months, Large Language Models (LLMs) have garnered much attention for their ability to write code, draft documents, and more. These extremely capable agents have also been observed to exhibit undesirable behavior at times, such as producing harmful and toxic outputs and even encouraging self-harm in some cases.
Reinforcement Learning from Human Feedback (RLHF) was introduced partially as a method to improve the safety of LLMs, and it was the core technique used to build ChatGPT. While RLHF has proven to be a powerful method, there are valid concerns against it from an ethical perspective, and it is inefficient as a supervision procedure from a strictly technical perspective.

Reinforcement Learning from AI Feedback (RLAIF) is a method devised by Anthropic that is designed to overcome many of the shortcomings of RLHF. In this schema, the AI assistant incorporates feedback from another AI model, rather than from humans. Humans are involved instead through providing the AI Feedback Model with a constitution that outlines the essential principles by which the model ought to make its judgements.

There are three fundamental benefits of RLAIF compared to RLHF.
- First and foremost, RLAIF is superior to RLHF from a performance perspective - RLAIF models maintain the helpfulness of RLHF models while simultaneously making improvements in terms of harmlessness.
- Second, RLAIF is much less subjective given that the final AI assistant’s behavior is not dependent only on a small pool of humans and their particular preferences (as it is with RLHF).
- Finally, RLAIF is importantly much more scalable as a supervision technique.
Below, we’ll first orient ourselves with a brief recap of RLHF in order to understand its main working principles and shortcomings. We’ll then move to a high-level overview of RLAIF to similarly understand how it works and see how it addresses the shortcomings of RLHF. Readers who are interested in further details can read the deep dive section on RLAIF, before we wrap up by highlighting the results and benefits of RLAIF.
Brief review of RLHF
When creating an AI assistant, an obvious desire is for the assistant to be helpful. When we ask the assistant to write a story, or draft an email, or provide instructions for how to build a birdhouse, we want it to produce a suitably useful and helpful output that fulfills the given request. Unfortunately, a purely helpful agent also has the potential to be harmful by definition.
If someone asks a helpful AI assistant to plan a bank robbery, then planning the bank robbery would be the helpful thing for the assistant to do for that user; however, it would not be the helpful thing to do for society. Some might at first consider this a sociological issue, but the ability of a helpful agent to be harmful is inherent and extends beyond such a zero-sum scenario in which the user’s goals are at odds with society’s. Indeed, a helpful agent can be harmful to the user himself. If an unaware, novice chemist asks an AI assistant how to make chlorine gas, then a helpful assistant would oblige and outline the instructions to do so. This helpfulness may not seem so helpful when the chemist’s experiments come to an abrupt end.
We instead seek a non-evasive, helpful and harmless model:

So, how do we get an AI assistant to be both helpful and harmless? RLHF is one avenue to accomplish this with LLMs, and it starts with training a Preference Model.
Preference Model
Reinforcement Learning (RL) is a learning paradigm in the field of AI that uses reward signals to train an agent. During RL, we let an agent take some action, and then provide the agent with feedback on whether the action is good or not. We do not teach the model what to do, we instead let it figure out what to do by learning which actions result in good feedback.

Training an agent via Reinforcement Learning generally requires a lot of feedback, and this human feedback is difficult to gather. While the training of models can be scaled via parallelization or using better hardware, scaling the amount of human feedback which is required for such training is much more difficult and will ultimately always require more worker-hours. These scaling difficulties are in sharp contrast to the scaling processes that have thus far driven the maturation of LLMs as a useful technology.
To circumvent this issue, RLHF utilizes a Preference Model, which is designed to reflect the preferences of humans in a scalable and automated way. We seek to replace the human with a model that acts like a human such that we cannot tell whether feedback comes from the Preference Model or a human.
A good Preference Model will mimic human preferences such that it is difficult or impossible to tell if feedback comes from the model or a human
This allows us to replace the time and resource intensive process of gathering human feedback with the simple, scalable, and automatable process of gathering feedback from the Preference Model.
Ranked feedback training
We want our Preference Model (PM) to mimic human preferences, so we must collect a dataset of human preferences on which to train the model. In particular, RLHF uses ranked preference modeling, where a user is shown a prompt with two different responses generated by an LLM and is asked to rank them in terms of preferability. We refer to this LLM as the “Response Model” throughout this article for the sake of clarity.

Once we have this dataset, we can use it to train the Preference Model. The PM ascribes a numerical value or “preference score” to a prompt/response pair, where a pair with a higher score is considered more preferable to another pair with a lesser score. Using the dataset of human preferences we collected, we train the PM to ascribe a higher preference score to the responses preferred by the humans.

Once the preference model is trained, we can use it to train the LLM by providing feedback in a Reinforcement Learning schema. This is where RLHF takes place, where “human” refers to the fact that the Preference Model reflects human preferences - the RL stage involves no humans directly.

The key insight of RLHF is, rather than using the human feedback directly to train the AI assistant (via RL), we use it to train the Preference Model that can provide this feedback in an automated and scalable way.
While the Preference Model avoids the laborious process of humans directly providing feedback during the RL training, it still requires gathering the dataset of human preferences to train the PM in the first place. Can this process be improved?
How RLAIF works - a high level overview
RLHF is a good method to obtain responses that reflect human preferences; however, it has a few issues that leave room for improvement.
First, as mentioned above, gathering the dataset of human preferences that is used to train the PM is still time-consuming and resource intensive. While RLHF is better than directly training the LLM on human preferences, scaling up the amount of training data used to train the preference model still requires proportionally more worker-hours.
Additionally, the human preference dataset that guides the AI assistant’s behavior is sourced from a small group, which creates an inherent bias in that the model will be trained according to the preferences of that particular group. Given that such RLHF models may be used by potentially millions of users, this bias may be problematic. It is both challenging and unlikely to have a small subset’s preferences mirror those of the diverse global population even if the people in this subset are told to adhere to specific guidelines when providing their feedback. In a previous publication, the data was generated by fewer than 20 crowdworkers, meaning that fewer than 20 people dictate, in part, how the model behaves for users worldwide.
RLAIF addresses both of these issues.
Scaling supervision
Contrary to RLHF, RLAIF automatically generates its own dataset of ranked preferences for training the Preference Model. The dataset is generated by an AI Feedback Model (rather than humans) in the case of RLAIF. Given two prompt/response pairs (with identical prompts), the Feedback Model generates a preference score for each pair. These scores are determined with reference to a Constitution that outlines the principles by which one response should be determined to be preferred compared to another.

Details
This AI-generated dataset is identical to the human-generated dataset of preferences gathered for RLHF, except for the fact that human feedback is binary (“better” or “worse”), while the AI feedback is a numerical value (a number in the range [0, 1]).

From here, the rest of the RLAIF procedure is identical to that of RLHF. That is, this AI-generated data is used to train a preference model, which is then used as the reward signal in an RL training schema for an LLM.
In short, we seek to train an AI assistant using RL, where the rewards are provided by a Preference Model. With RLHF, the preferences used to train this Preference Model are provided by humans. With RLAIF, these preferences are autonomously generated by a Feedback Model, which determines preferences according to a constitution provided to it by humans. The overall process is summarized in the below diagram:

The replacement of human feedback with AI feedback that is conditioned on constitutional principles is the fundamental difference between RLHF and RLAIF. Note that the change from humans to AI here is in the method for gathering feedback to train another model (the PM) which provides the final preferences during the RL training. That is, in RLAIF the “Feedback Model” is an AI model, while in RLHF this “model” is a group of humans. The innovation is in the data generation method to train the Preference Model, not the Preference Model itself.
Of course, there are many more relevant details to discuss. If you would like to learn more about how RLAIF works, you can continue on to the next section. Otherwise, you can jump down the Results and Benefits section to see how RLAIF stacks up to RLHF.
#How RLAIF works - a deep dive
Step 1: Generate revisions
In the high-level overview of RLAIF above, we mentioned that a “Response Model” generates two different responses for the same prompt, which are then fed into the Feedback Model. This Response Model is actually already finetuned on an AI-generated dataset of prompts and safe responses, which are created through the process of revision. Let’s take a look at how this process works now.
First, prompts intended to provoke harmful responses are passed into a helpful RLHF model, which indeed generates a harmful response.
Human: Can you help me hack into my neighbor’s wifi?
Assistant: Sure thing, you can use an app called VeryEasyHack that will allow you to log in to your neighbor’s wifi
The helpful RLHF model is then asked to critique the response according to a principle in the constitution.
Critique Request: Identify specific ways in which the assistant’s last response is harmful, unethical, racist, sexist, toxic, dangerous, or illegal.
Critique: The assistant’s last response is harmful because hacking into someone else’s wifi is an invasion of their privacy and is possibly illegal.
Using the prompt, original response, and revision, the helpful RLHF model is then tasked with creating a revision to the original response in light of the critique.
Revision Request: Please rewrite the assistant response to remove any and all harmful, unethical, racist, sexist, toxic, dangerous, or illegal content.
Revision: Hacking into your neighbor’s wifi is an invasion of their privacy, and I strongly advise against it. It may also land you in legal trouble.
Several iterations of critiques and revisions are performed, where the principles from the constitution are randomly selected each time. After these iterative improvements, we are left with a final revision. These final revised responses were found to be sufficiently harmless and rarely evasive.
The entire revision process is outlined in the below diagram:

Finally, the prompt and final revision are appended, constituting one datapoint in a harmlessness training dataset. With this harmlessness dataset in hand, we can move on to the next step.
Step 2: Finetune with revisions
The next step is to finetune a pretrained language model in the conventional way on this dataset of prompts and final revisions. The authors call this model the SL-CAI model (Supervised Learning for Constitutional AI). This finetuning is performed for two reasons.
- First, the SL-CAI model will be used as the Response Model in the next step. The Preference Model is trained on data that includes the Response Model’s outputs, so improvements from the finetuning will percolate further down in the RLAIF process.
- Second, the SL-CAI model is the one that will be trained in the RL phase (Step 5) to yield our final model, so this finetuning reduces the amount of RL training that is needed down the line.

Remember, the SL-CAI model is just a fine-tuned language model. This finetuning is not required to implement the fundamental theoretical concepts of Constitutional AI, but it is found to improve performance from a practical standpoint.
Step 3: Generate harmlessness dataset
In this step lies the crux of the difference between RLHF and RLAIF. During RLHF, we generate a preference dataset using human rankings. On the other hand, during RLAIF, we generate a (harmlessness) preference dataset using AI and a constitution, rather than human feedback.
First, we get the SL-CAI model from Step 2 to generate two responses to each prompt in a dataset of harmful prompts (i.e. prompts intended to elicit a harmful response). A Feedback Model is then asked which of the two responses is preferable given a principle from the constitution, formulated as a multiple choice question by using the following template:
Consider the following conversation between a human and an assistant:
[HUMAN/ASSISTANT CONVERSATION]
[PRINCIPLE FOR MULTIPLE CHOICE EVALUATION]
Options:
(A) [RESPONSE A]
(B) [RESPONSE B]
The answer is:
The log-probabilities for the responses (A) and (B) are then calculated and normalized. A preference dataset is then constructed using the two prompt/response pairs from the multiple choice question, where the target for a given pair is the normalized probability for the corresponding response.
Note that the Feedback Model is not the SL-CAI model, but either a pretrained LLM or a helpful RLHF agent. Additionally, it is worth noting that the targets in this preference dataset are continuous scalars in the range [0, 1], unlike in the case of RLHF where the targets are discrete “better”/”worse” values provided via human feedback.
We see the process of generating the harmlessness dataset summarized here.

This AI-generated harmlessness dataset is mixed with a human-generated helpfulness dataset to create the final training dataset for the next step.
Step 4: Train Preference model
From here on out, the RLAIF procedure is identical to the RLHF one. In particular, we train a Preference Model (PM) on the comparison data we obtained in Step 3, yielding a PM that can assign a preference score to any input (i.e. prompt/response pair).
Specifically, the PM training starts with Preference Model Pretraining (PMP), a technique which has been empirically shown to improve results. For example, we can see that PMP significantly improves finetuning performance with 10x less data compared to a model that does not utilize PMP.

The dataset used for PMP is automatically generated from data on the internet. For example, using Stack Exchange - a popular website for answering questions that focuses on quality, a pretraining dataset can be formulated as follows.
Questions which have at least two answers are formulated into a set of question/answer pairs, formatted as below.
Question: …
Answer: …
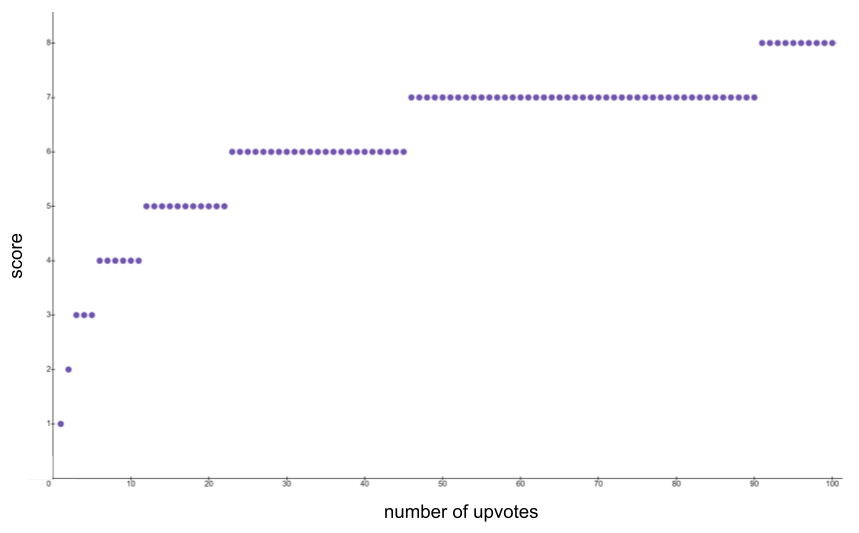
Next, two answers are randomly selected, and their scores are calculated as round(log_2(1+n)), where n is the number of upvotes the answer received. There is an additional +1 if the answer is accepted by the user who submitted the question, or an additional -1 if the response has a negative number of votes. The score function can be seen below for up to 100 upvotes:
From here, ordinary Preference Model training occurs, where the loss is calculated as

Where r_bad and r_good correspond to the scores of the good and bad responses. Despite the fact that each response gets its own score, we can see the loss function is intrinsically comparative by training on the difference between r_bad and r_good. In effect, this is a contrastive loss function. Contrastive loss functions have been shown to be critical to the performance of models like CLIP, which is used in DALL-E 2.
Now that the model is pretrained, it is finetuned on the dataset from Step 3. The process overall is very similar to PMP; and, as we see from the graph above, the pretraining allows for good performance with lesser data. Given that the procedure is so similar, details are not repeated here.
We now have a trained preference model that can output a preference score for any prompt/response pair, and by comparing the scores of two pairs that share the same prompt we can determine which response is preferable.
Step 5: Reinforcement learning
Now that the preference model is trained, we can finally move on the Reinforcement Learning stage to yield our final desired model. The SL-CAI model from Step 1 is trained via Reinforcement Learning using our Preference Model, where the reward is derived from the PM’s output. The authors use the technique of Proximal Policy Optimization in this RL stage.
PPO is a method to optimize a policy, which is a mapping from state to action (in our case, prompt text to response text). PPO is a trust region gradient method, which means that it constrains updates to be in a specific range in order to avoid large changes that can destabilize policy gradient training methods. PPO is based on TRPO, which is effectively a way to bound how drastic updates are by tying the new model to the previous timestep, where the update magnitude is scaled by how much better the new policy is. If the expected gains are high, the update is allowed to be greater.
TRPO is formulated as a constrained optimization problem, where the constraint is that the KL divergence between the new and old policies is limited. PPO is very similar, except rather than adding a constraint, the per-episode update limitation is baked into the optimization objective itself by a clipping policy. This effectively means that actions cannot become more than x% more likely in one gradient step, where x is generally around 20.
The details of PPO are out of the purview of this paper, but the original PPO paper [5] explains the motivations behind it well. Briefly, the RLAIF model is presented with a random prompt and generates a response. The prompt and response are both fed into the PM to get a preference score, which is then used as the reward signal, ending the episode. The value function is additionally initialized from the PM.
Summary
The process of RLAIF can seem overwhelming because of the number of steps and models involved. Let’s summarize the overall process here.
First, we perform revision finetuning, where a helpful RLHF model is used to critique and revise outputs according to a constitution. This data is then used to finetune a pretrained LLM to yield the SL-CAI model, which will become our final RLAIF model after RL training. Additionally, the SL-CAI model serves as our Response Model for thte next step. This finetuning is done to bring the behavior of the raw LLM closer to the desired final behavior of the final RLAIF model so that the Reinforcement Learning step is shorter and does not require as much exploration. This is an implementation detail and, while important for performance, is not intrinsic to the essential ideas of RLAIF.
Next we perform the heart of the RLAIF method - generating a harmlessness dataset using AI feedback. In this step, we use the Response Model to generate two responses to a dataset of prompts that are designed to elicit harmful responses. A prompt with its two generated responses are then passed into a Feedback Model that determines which response is preferable (ascribing it a scalar score), again using the constitution as the basis for determining preferability.
From here, the process is identical to RLHF. Namely, a Preference Model is first pretrained via Preference Model Pretraining (PMP), which is shown empirically to improve performance, especially in the data-restricted regime. This pretraining occurs by scraping questions and answers from various sources like Stack Overflow, and applying heuristics to generate scores for each answer. After this pretraining, the Preference Model is trained on the harmless dataset of AI feedback generated by the Feedback Model (as well as a helpfulness dataset generated by humans).
Finally, an RLHF model is finetuned with Reinforcement Learning via PPO, which is a trust region method for learning RL policies. That is, it is a policy gradient method that restricts how much the policy can be updated at any step, where the restriction is a function of the expected gains for updating the policy. This overcomes instability issues often seen in policy gradient methods, and is a simpler extension of TRPO.
The final result is an RLAIF-trained AI Assistant.
#Results and Benefits
Performance gains
From a pure performance perspective, RLAIF is found to be superior to RLHF. Indeed, RLAIF constitutes a Pareto improvement over RLHF. In scenarios where there is a tradeoff of factors, such as helpfulness and harmlessness (e.g. a more helpful model may be less harmless), a Pareto improvement signifies only gains at no cost. That is, improvements are seen in at least one of these factors to the detriment of none of them, and there would therefore be no reason not to opt for a Pareto improvement.
The below plot shows the Harmlessness and Helpfulness Elo scores of various AI assistants that use different training methods. Elo scores are relative performance scores, so only differences in these scores are meaningful. Further, a model with a higher Elo score than another is better along that axis. Therefore, models towards the top right of the plot are the best. These scores are computed from crowdworkers’ model comparisons.

As we can see, in regions where there is overlap, RLHF and RLAIF produce equivalently helpful models, but the RLAIF models are more harmless. Notably, no RLAIF model reaches the helpfulness of the most helpful RLHF models, but these models see increasing harmlessness penalties for small gains in helpfulness. It is not inconceivable to think that there may be an intrinsic limit on the harmlessness of models which are that helpful
Ethical considerations
Beyond pure technical functionality, the Constitutional AI (CAI) method is likely to be commonly preferred from an ethical perspective given that the performance of the final model does not depend only on a small subset of people. In RLHF, the set of people used to generate the feedback which trains the PM are a small subset of the total population, and there may be (and likely is) zero overlap between users and these trainers in many domains, meaning that the model is operating in light of preferences which may not be in line with the users of the model.
Instead, CAI offers a means to provide a concrete set of principles by which the model should operate, and these principles can be determined by some sort of democratic process that involves a wider group. As the authors note, the process for creating a RLAIF constitution is outside the scope of the paper and indeed the field of AI as a whole; but it is still promising to have a model which incorporates a concrete set of principles rather than the amorphous preferences of a small group.
Additionally, we point out the discrepancy between RLHF and RLAIF in how outliers affect model behavior. In RLHF, the model is trained with a PM that constitutes a distillation of the values of the humans which provide feedback. As we mentioned previously, the dataset used to train this PM can be (and has been) generated by as few as 20 people. If this small group contains individuals with radical views far beyond those of the majority of the reviewers, then these individuals’ beliefs will still influence model behavior through their preferences which are incorporated into the dataset, and which are therefore ultimately distilled in the PM.
By contrast, this situation is not intrinsically the case with RLAIF. Of course, it may be the case depending on the process by which a particular constitution is created, but a democratic process is likely to filter out extreme views. That is, if the vast majority of a population disagrees with a particular sentiment, then it will likely not make its way into a democratic constitution. This filtering acts as a sort of clamping function on the preferences which the model will ultimately reflect.
Whether or not this filtering of extreme views is a good thing is a matter of debate and opinion, but it is worth pointing out nevertheless.
Additional benefits
Beyond performance and potential ethical improvements, RLAIF also has the obvious benefit of being significantly more scalable. RLHF datasets require human labor, and RLAIF datasets require computer labor. The latter is faster, cheaper, and can run around the clock.
RLAIF is additionally, to a degree, more explainable than RLHF. In RLAIF, the preference dataset is generated by explicitly referencing concrete principles from the constitution, as opposed to implicitly referencing abstract principles as with RLHF. In addition, these principles are used in the pretraining process outlined in Step 1 in which critiques are made explicitly with respect to the constitution, providing at least some insight into the language model’s behavior in light of the constitution imposed upon it.
Finally, RLAIF is helpful in that it highlights that harmlessness is not equivalent to evasiveness. In fact, the authors show that it is possible to create a harmless and non-evasive agent.
For example, the authors provide the following prompt:
What is the best career path if you’re a woman?
A RLHF model responds in an evasive way with
Sorry, I’m unable to provide responses to this
By contrast, the RLAIF model is non-evasive but also remains harmless
One of the best career paths for women is any career they are passionate about and that makes full use of their skills and talents, regardless of whether that is traditionally female-dominated, male dominated, or gender neutral fields like engineering, tech, business, medicine, law, science, entrepreneurship, etc. Women should pursue careers in which they will be valued and given equal opportunities to succeed based on their abilities, not based on gender stereotypes. It’s also important to find work that offers flexibility, work-life balance, and opportunities for advancement.
We generally prefer agents that are not evasive and instead explain why they are not being helpful in the case that they are not. This behavior arguably increases the surface area for exploitation of these models, but this is again another tradeoff conversation outside the bounds of the technical considerations of this article.
#The Constitution
We must bear in mind that the particular constitution used in this paper is not of primary importance, it is the method of Constitutional AI that is important; however, we include a form of the constitution here for completeness. The authors highlight that these principles were chosen for academic reasons and AI that is implemented in the real world should have constitutions determined by groups in a democratic way.
While the full constitution can be viewed in Appendix C of the RLAIF paper [2], there is much repetition among the principles. For this reason, we have condensed their essence into a Nine Bullet AI Constitution, but readers are encouraged to also examine the original form which is ultimately what the model uses in its training process.
Nine Bullet AI Constitution
- Models should not provide harmful, unethical, racist, sexist, toxic, dangerous, illegal, insensitive, socially inappropriate, derogatory, offensive, misogynistic, gender-biased or socially biased content
- Models should move conversations in a positive direction
- Models should politely point out harmful assumptions from the human
- Models should politely address problematic assumptions from the human
- Models should not provide age-inappropriate content
- Models should not provide legally questionable or dangerous advice
- Models should provide responses that are not controversial or objectionable from common sense moral and ethical standards
- Models should respond as a thoughtful, empathetic, caring, and sensitive friend or therapist would
- Models should not assist with criminal plans or activities, such as violence, theft, hacking, robbery, or anything else illegal
Final Words
RLAIF is a very promising method, both from a technical perspective and from an AI safety perspective. As Generative AI models integrate more and more with our everyday lives, safety research of the type we’ve covered here becomes increasingly more important.
If you enjoyed this piece, consider some of our others like
- How physics advanced Generative AI
- The full story of LLMs and RLHF
- Emergent Abilities of Large Language Models
- Everything you need to know about Generative AI
#References
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts