Introducing Multilingual Universal-Streaming: Go global with ultra-fast, ultra-accurate real-time speech-to-text
Universal-Streaming now supports six languages—English, Spanish, French, German, Italian, and Portuguese—in a single, unified model, while maintaining the superior accuracy that makes it the industry-leading streaming speech-to-text solution for voice agents.

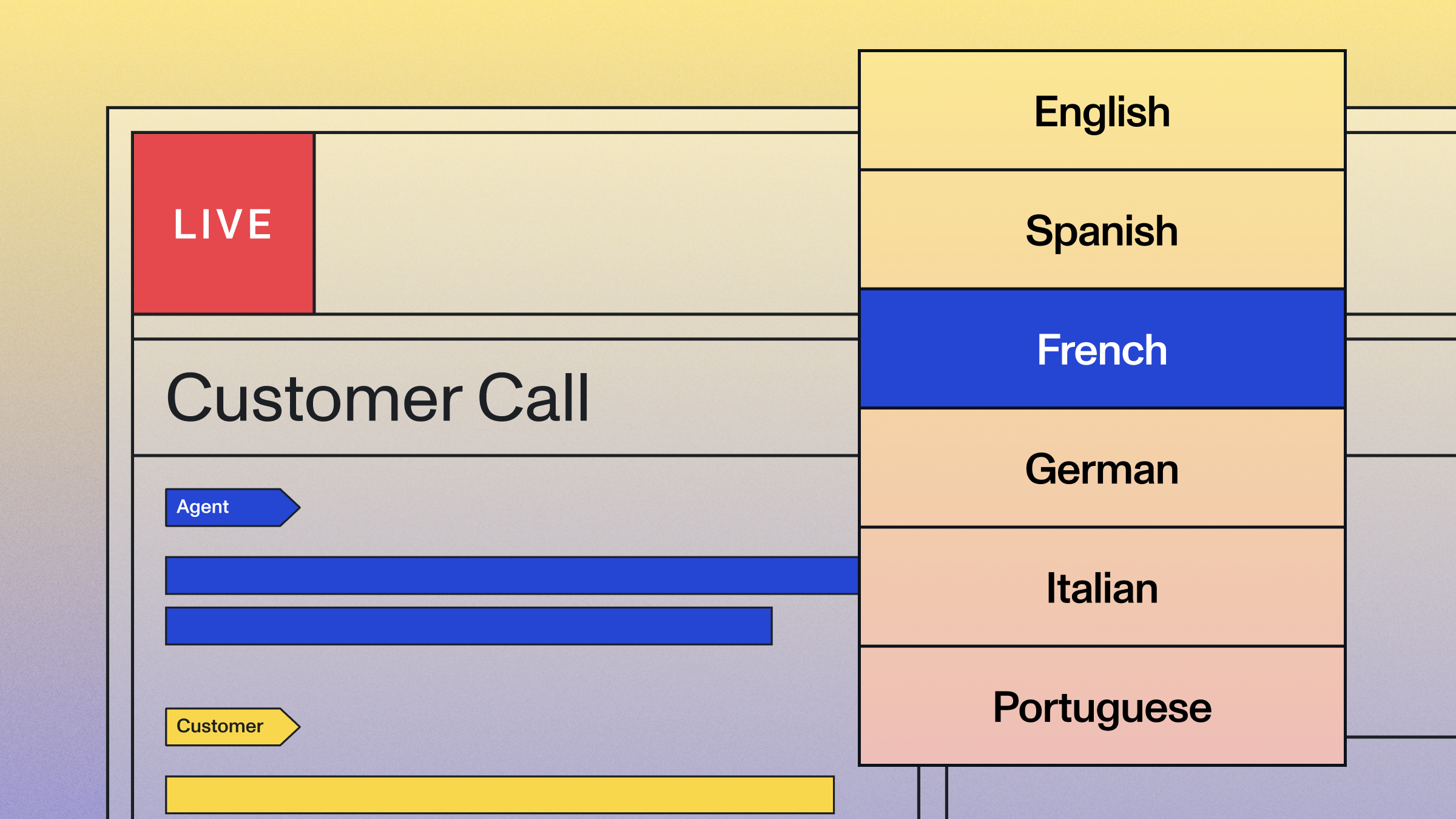

Universal-Streaming now supports six languages—English, Spanish, French, German, Italian, and Portuguese—in a single, unified model, while maintaining the superior accuracy that makes it the industry-leading streaming speech-to-text solution for voice agents.
Real-time Voice AI is transforming how businesses operate globally, from voice agents handling customer calls to AI assistants capturing meeting notes in multiple languages. But expanding beyond English presents technical and business challenges that force companies to choose between market reach and product quality.
Now, you can eliminate those trade-offs.
Universal-Streaming delivers six languages in one unified model (English, Spanish, French, German, Italian, and Portuguese) with industry-leading multilingual performance for production real-time applications.
Real-time Voice AI needs to speak everyone's language
The demand for multilingual real-time Voice AI spans every industry and use case. Voice agents serving customers in Madrid. Real-time agent assist tools helping support teams in São Paulo. Meeting assistants capturing board discussions across European offices. Medical scribes documenting patient consultations in multiple languages. But going global with real-time speech isn't always straightforward.
The hidden costs of going global
Most providers treat non-English languages as premium add-ons, charging up to 2x for multilingual support, with specialized languages requiring separate minimum commitments. However, the real expense arises from inconsistencies in accuracy across languages. A 3% higher error rate translates to 5-10% more in human QA costs, which becomes an expensive oversight at scale.
In regulated environments like healthcare or finance, where real-time transcription must be precise, these variable accuracy levels create unpredictable operational expenses throughout your workflows.
Unified architecture built for multilingual performance
Universal-Streaming eliminates these barriers with a single, unified architecture trained on all languages simultaneously. Rather than routing requests through language detection gateways, the model processes audio directly with a shared architecture optimized for multilingual conversations.
Key benefits include:
Instant processing: The model handles all six languages natively in a single forward pass, eliminating detection latency and routing complexity from your stack.
Natural code-switching: The use of an audio embedding space shared across all languages allows the model to handle intra-utterance language switches without special handling:
- "Hola, can you help me find el restaurante on Main Street?"
- "Je voudrais un coffee, s'il vous plaît, large with extra milk"
You get consistent quality across all languages with transparent, scalable pricing and a single WebSocket connection.
Consistent improvements: When we improve the model, every language benefits from the same architectural enhancements, decoder optimizations, and attention mechanism improvements.
Real-world performance benchmarks
Word Error Rate (WER) and P50 Latency measured on diverse real-world audio including call center recordings with background noise, medical consultations with domain terminology, and business meetings with multiple speakers. Any model can perform well in perfect audio conditions, but phone calls and meeting rooms are far less than perfect and present real challenges.
Why these metrics matter:
- WER (Word Error Rate) directly impacts user experience: Lower WER means fewer frustrating misunderstandings in your voice agents and more accurate transcripts for downstream processing.
- P50 latency affects conversation flow: Consistent sub-400ms latency ensures your voice agents respond naturally without awkward pauses that break the conversation.
Testing methodology: Evaluated across datasets of multilingual audio with samples from all six supported languages. Latency was measured as the time from when each word ended in the audio stream to when that same word first appeared in the transcript. Only words transcribed correctly were included, and the P50 (median) of those word-level latencies was calculated.
Test with your own audio: These benchmarks are a starting point, but your specific use case matters most. Use our Playground to speak to the model and evaluate Universal-Streaming's accuracy and latency with your actual data before integrating.
One price for all languages
Global adoption shouldn't limit your ability to scale. With all languages priced equally at $0.15/hr (including non-English), you can expand your real-time applications confidently across markets.
Production-ready from day one
Every transcript arrives perfectly formatted with the capabilities you need to deliver exceptional voice-agent experiences:
Punctuated text: Proper punctuation and sentence boundaries are included automatically, so transcripts are immediately readable for end users and ready for downstream LLM processing without additional formatting steps.
Proper capitalization: Names, places, and sentences formatted appropriately and consistently. You get professional-quality output without building custom post-processing pipelines to handle proper nouns or sentence structure.
Intelligent endpointing: Built-in end-of-turn detection for natural conversations. The model automatically identifies when a speaker has finished their turn, enabling your voice agent to respond at the right moment without awkward interruptions or delays that break conversation flow.
Integration in minutes, not months
Universal-Streaming is compatible with your existing stack. You can start building immediately:
- LiveKit: Native integration as the default provider
- Vapi: Configure multilingual agents with one parameter
- Pipecat/Daily: Drop-in replacement for any STT provider
- Via the API: Same WebSocket, new languages
Get started with a few lines of code
Just getting started? Simply set the "speech_model" to "universal-streaming-multilingual". For a quick start guide, check out our full docs.
BASE_URL = "wss://streaming.assemblyai.com/v3/ws"
CONNECTION_PARAMS = {
"sample_rate": RATE,
"format_turns": True,
"speech_model": "universal-streaming-multilingual",
}
Build global voice agents with Universal-Streaming
Three easy ways to get started:
- Implement immediately: Multilingual is available now through our API. Simply open a websocket to our wss://streaming.assemblyai.com/v3/ws endpoint using your current API key.
- Try it in the Playground: Use our no-code Playground to see Universal-Streaming's performance with your specific audio and use cases using our interactive testing environment.
- Explore the documentation: Review our comprehensive Getting Started Guide and technical documentation for detailed implementation information.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts