
Offline speech recognition with Whisper: Browser + Node.js implementations
In part three of this 3-part blog series, you’ll learn how to run Whisper locally in the browser or on your server. This guide walks through private, offline speech recognition setups using WebAssembly and Node.js.



Note: This blog post is part 3 of a 3-part series. See OpenAI Whisper for Developers: Choosing Between API, Local, or Server-Side Transcription for the first in the series and How to use Whisper API to transcribe audio in JavaScript for the second.
Let's explore how to run Whisper directly in the browser. This approach offers several compelling advantages over API-based solutions: complete offline functionality eliminates network dependencies and enables transcription in environments without internet connectivity, enhanced privacy ensures that sensitive audio data never leaves the user's device, and cost elimination removes per-request charges that can accumulate with high-volume usage.
Browser-based Whisper implementations leverage WebAssembly (WASM) technology to run machine learning models natively in the browser. WebAssembly is a binary instruction format that enables near-native performance for computationally intensive tasks like neural network inference. For Whisper, this means we can run the same transformer architecture that powers the original Python implementation directly in JavaScript, albeit with some performance trade-offs compared to GPU-accelerated server environments.
The implementation we'll use comes from Hugging Face's [Transformers.js] library, which provides JavaScript bindings for popular transformer models. This library handles the complexities of model loading, WebAssembly compilation, and tensor operations, presenting a clean API similar to the Python transformers library.
To get started with browser-based Whisper, install the Transformers.js library:
npm install @xenova/transformers
Create a new file src/client/whisperClient.js to encapsulate all browser-based Whisper functionality:
This code defines a WhisperClient class that handles loading the Whisper model through a Transformations pipeline. The load method initializes the model and provides a callback for tracking loading progress. We also added a isLoaded and isLoading flags to prevent multiple concurrent loads.
The chunked processing approach (chunk_length_s: 30 with stride_length_s: 5) handles longer audio files by processing them in overlapping segments. This prevents memory issues with large files while maintaining transcription continuity through the 5-second overlap between chunks.
Update your HTML to include transcription method selection. Add this section right after your main heading:
<!-- Transcription Method Selection -->
<div class="p-6 bg-white border border-gray-200 rounded-lg shadow dark:bg-gray-800 dark:border-gray-700 mb-6">
<h5 class="mb-4 text-xl font-bold tracking-tight text-gray-900 dark:text-white">Transcription Method</h5>
<select id="transcriptionMethod" class="bg-gray-50 border border-gray-300 text-gray-900 text-sm rounded-lg focus:ring-blue-500 focus:border-blue-500 block w-full p-2.5 dark:bg-gray-700 dark:border-gray-600 dark:placeholder-gray-400 dark:text-white dark:focus:ring-blue-500 dark:focus:border-blue-500">
<option value="api" selected>OpenAI API (Server)</option>
<option value="browser">Browser-based (Local)</option>
</select>
<div id="whisperStatus" class="hidden mt-3 text-sm text-blue-500"></div>
</div>
<!-- Main Card Container -->
This allows users to choose between the OpenAI API and the browser-based Whisper implementation. Now let's write the code to load the Whisper model when the "browser" option is selected. Update the src/client/index.js file with the following code:
import WhisperClient from './whisperClient.js';
// Transcription method selection
const whisperClient = new WhisperClient();
const transcriptionMethodSelect = document.getElementById('transcriptionMethod');
const whisperStatus = document.getElementById('whisperStatus');
transcriptionMethodSelect.addEventListener('change', (e) => {
if (e.target.value === 'browser' && !whisperClient.isLoaded && !whisperClient.isLoading) {
loadWhisperModel();
} else {
transcriber = new OpenAITranscriber(loadingIndicator, resultsBox, transcriptionText);
}
});
// Load Whisper model
async function loadWhisperModel() {
if (!whisperClient.isLoaded && !whisperClient.isLoading) {
whisperStatus.textContent = 'Loading Whisper model...';
whisperStatus.classList.remove('hidden');
whisperStatus.className = 'mt-3 text-sm text-blue-500';
try {
await whisperClient.load((progress) => {
if (progress.status === 'progress') {
const percentage = Math.round(progress.progress);
whisperStatus.textContent = `Loading Whisper model: ${percentage}%`;
}
});
whisperStatus.textContent = 'Whisper model loaded and ready!';
whisperStatus.className = 'mt-3 text-sm text-green-500 success-message';
setTimeout(() => {
whisperStatus.classList.add('hidden');
}, 10000);
} catch (error) {
console.error('Error loading Whisper model:', error);
whisperStatus.textContent = 'Failed to load Whisper model. Please try again or use the API option.';
whisperStatus.className = 'mt-3 text-sm text-red-500 error-message';
}
}
}
First, we set an "on change" event listener on the transcription method selection. If the user selects the "browser" option, we check if the Whisper model is already loaded or if it's currently loading. If not, we call the WhisperClient.load function to load the model. Most of the code above is handling the visual feedback for model loading:
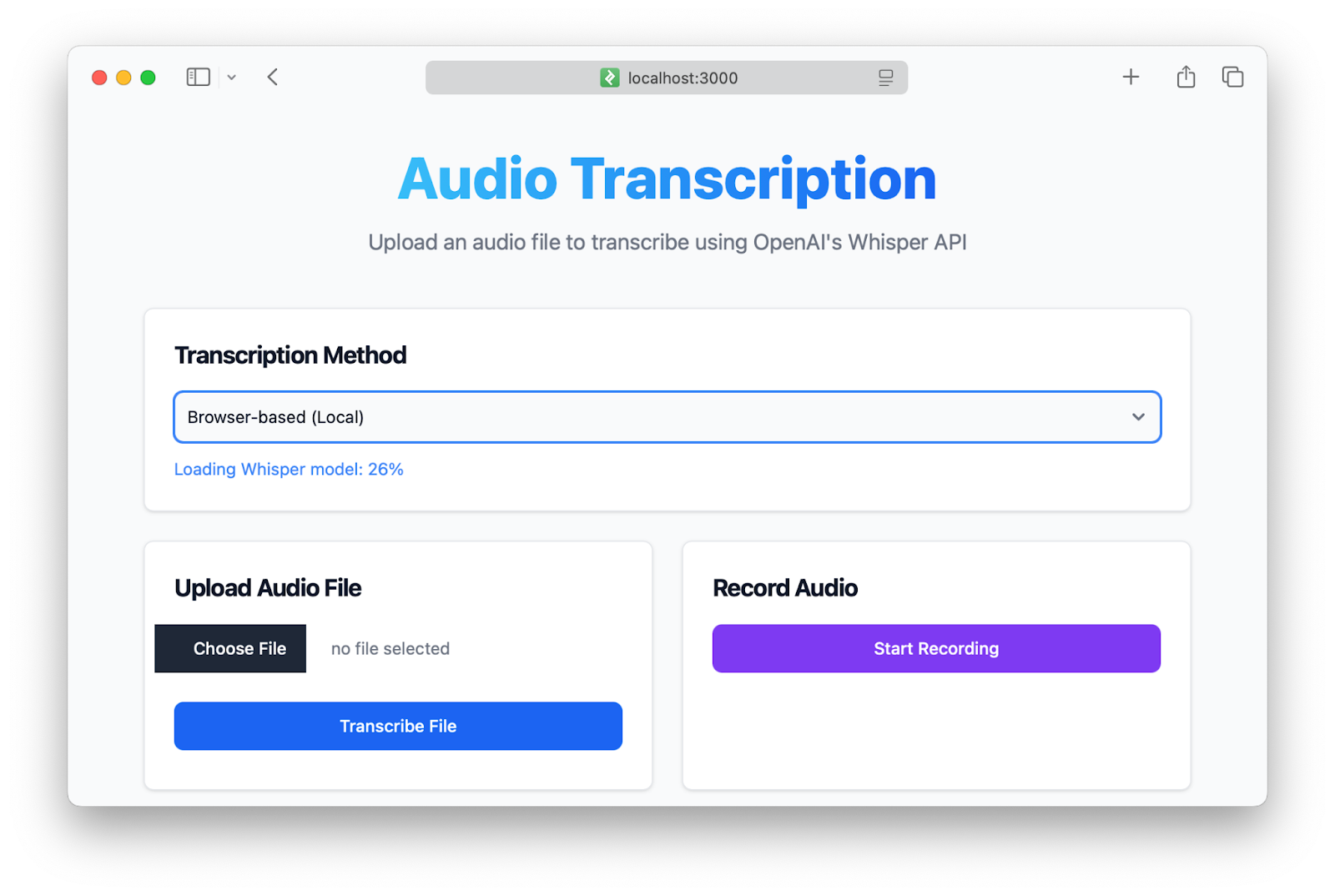
Once the model is loaded, we update the status message to indicate that the Whisper model is ready for use. At this point, we can implement the transcription functionality using the WhisperClient class. Let's implement the BrowserWhisperTranscriber transcriber which extends the base Transcriber class and prepares the audio data for transcription:
export class BrowserWhisperTranscriber extends Transcriber {
constructor(loadingIndicator, resultsBox, transcriptionText, whisperClient) {
super(loadingIndicator, resultsBox, transcriptionText);
this.whisperClient = whisperClient;
}
async transcribeAudio(audioFileOrBlob, onFinish) {
if (!this.whisperClient.isLoaded) {
alert('Please wait for the Whisper model to load.');
return;
}
if (audioFileOrBlob instanceof File) {
await this.transcribeAudioFile(audioFileOrBlob, onFinish);
} else {
await this.transcribeAudioData(audioFileOrBlob, onFinish);
}
}
async transcribeAudioFile(file, onFinish) {
const supportedTypes = ['audio/x-wav', 'audio/x-mp3', 'audio/x-mpeg', 'audio/x-ogg', 'audio/x-webm', 'audio/x-mp4'];
if (supportedTypes.some(type => file.type.includes(type))) {
const reader = new FileReader();
reader.addEventListener('load', async (e) => {
if (e.target && e.target.result) {
const arrayBuffer = e.target.result
const audioData = await this.decodeArrayBuffer(arrayBuffer);
const result = await this.whisperClient.transcribe(audioData);
onFinish(result.text);
}
})
reader.readAsArrayBuffer(file);
} else {
console.warn(`File type ${file.type} might not be supported`);
}
}
async transcribeAudioData(blob, onFinish) {
const arrayBuffer = await blob.arrayBuffer();
const audioData = await this.decodeArrayBuffer(arrayBuffer);
const result = await this.whisperClient.transcribe(audioData);
onFinish(result.text)
}
async decodeArrayBuffer(arrayBuffer) {
const audioContext = new AudioContext({sampleRate: 16000});
console.log(arrayBuffer);
const audioBuffer = await audioContext.decodeAudioData(arrayBuffer);
console.log('Web Audio API buffer info:', {
duration: audioBuffer.duration,
sampleRate: audioBuffer.sampleRate,
numberOfChannels: audioBuffer.numberOfChannels,
length: audioBuffer.length
});
return audioBuffer.getChannelData(0);
}
}
This implementation handles the audio processing pipeline required for browser-based Whisper transcription. The audio decoding process uses the Web Audio API to convert various audio formats into the raw PCM data that Whisper expects. This involves several steps:
Format Normalization: The decodeAudioBuffer method handles the conversion from various audio formats (MP3, WAV, WebM, etc.) into standardized PCM audio data. The Web Audio API automatically handles most format complexities, but we need to ensure the output matches Whisper's requirements.
Sample Rate Conversion: Whisper models are trained on 16kHz audio, so any input audio must be resampled to this rate. The resampleAudio method implements linear interpolation resampling, which provides good quality for speech audio while being computationally efficient for browser environments.
Channel Reduction: Whisper expects mono (single-channel) audio, so stereo recordings are converted by taking the first channel. For applications requiring better stereo handling, you could implement channel mixing instead.
With all components in place, rebuild your application and test both transcription methods:
npm run build
npm run dev
Navigate to http://localhost:8000 and test the browser-based functionality:
- Select "Browser Whisper (Local)" from the transcription method dropdown
- Wait for model loading - you'll see detailed progress as the ~39MB model downloads and initializes
- Test with both file uploads and recordings - the same interface works with both input methods
- Verify offline functionality - once loaded, disable your internet connection and confirm transcription still works
The browser-based implementation provides several advantages for specific use cases. Privacy-sensitive applications benefit from keeping audio data entirely on the user's device. Offline environments can use transcription without internet connectivity. High-volume applications avoid per-request API costs after the initial model download.
However, there are important performance considerations to keep in mind. Browser-based inference is significantly slower than server-based processing, especially on lower-powered devices. The model download represents a substantial initial overhead that may not be justified for occasional use. Additionally, accuracy may be lower than the full-size models available through the OpenAI API, particularly for audio with background noise or non-common accents.
Running Whisper with Node.js
Server-side Whisper implementation offers significant advantages over browser-based solutions, particularly in performance and scalability. Node.js can leverage powerful server hardware, including GPUs, to accelerate model inference, resulting in substantially faster processing times compared to browser-based WebAssembly implementations. While this approach sacrifices the complete offline functionality of browser-based solutions, it maintains data privacy by keeping audio processing within your controlled infrastructure without relying on third-party services.
This section demonstrates how to integrate a self-hosted Whisper implementation using the nodejs-whisper package, which provides Node.js bindings for OpenAI's Whisper model optimized for CPU processing. First, install the nodejs-whisper package, which handles model loading, audio preprocessing, and transcription:
npm install nodejs-whisper
The package automatically handles complex tasks including model management, audio format conversion to the required 16kHz WAV format, and memory-efficient processing. However, it requires [FFmpeg] for audio preprocessing. Install FFmpeg according to your operating system requirements:
export class OpenAITranscriber extends Transcriber {
constructor(openai) {
super();
this.openai = openai
}
async transcribe(filePath) {
const transcription = await this.openai.audio.transcriptions.create({
file: fs.createReadStream(filePath),
model: 'whisper-1',
language: 'en'
});
return transcription.text
}
}
export function transcriberFactory(type) {
switch (type) {
case 'openai':
const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
return new OpenAITranscriber(openai);
default:
throw new Error(`Unknown transcriber type: ${type}`);
}
}
The transcriberFactory function implements the factory to create appropriate transcriber instances based on the service type. This approach provides several benefits: it centralizes transcription service instantiation, enables easy addition of new services without modifying existing code, and allows runtime selection of transcription providers through query parameters.
When the OpenAI transcription service is extracted, we can simplify our main src/server/index.js file to utilize the new transcriber architecture.
app.post('/api/transcribe', upload.single('audio'), async (request, response) => {
// .. existing code ...
console.log(`Transcribing file: ${filePath} (${request.file.size} bytes)`);
try {
const transcriber = transcriberFactory(request.query.transcriber || 'openai');
response.json({
success: true,
transcription: await transcriber.transcribe(filePath)
});
} catch (error) {
console.error('Transcription error:', error);
response.status(500).json({success: false, error: error.message});
} finally {
fs.unlinkSync(filePath);
}
});
This update makes your server endpoint service-agnostic, allowing you to switch transcription providers by changing a query parameter. And finally, we can implement our WhisperTranscriber class and update the factory to support its initialization:
export class WhisperTranscriber extends Transcriber {
async transcribe(filePath) {
const transcription = await nodewhisper(filePath, {
modelName: 'base.en',
autoDownloadModelName: 'base.en',
})
return transcription.split("\n").map((x) => x.substring(34)).join(" ");
}
}
export function transcriberFactory(type) {
switch (type) {
// ... existing OpenAI case ...
case 'whisper':
return new WhisperTranscriber();
default:
throw new Error(`Unknown transcriber type: ${type}`);
}
}
This allows us to use the WhisperTranscriber class through the same /api/transcribe endpoint by passing the transcriber=whisper query parameter. Test your new server-side Whisper implementation using curl:
curl -X POST http://localhost:3000/api/transcribe?transcriber=whisper \
-F "audio=@/path/to/your/audio.wav" \
-H "Content-Type: multipart/form-data"
...
The first request will take longer as the model downloads and initializes. Subsequent requests will process much faster. You should see output similar to:
{
"success": true,
"transcription": "Your transcribed audio text will appear here"
}
You can pick different models by changing the modelName and autoDownloadModelName parameters in the nodewhisper function call. To see what Whisper models are available and their resource requirements, run:
npx nodejs-whisper download
The command outputs the list of models, their sizes and RAM requirements:
[Nodejs-whisper] Currently installed models:
- base.en
- large
[Nodejs-whisper] You can install additional models from the list below.
| Model | Disk | RAM |
|----------------|--------|---------|
| tiny | 75 MB | ~390 MB |
| tiny.en | 75 MB | ~390 MB |
| base | 142 MB | ~500 MB |
| base.en | 142 MB | ~500 MB |
| small | 466 MB | ~1.0 GB |
| small.en | 466 MB | ~1.0 GB |
| medium | 1.5 GB | ~2.6 GB |
| medium.en | 1.5 GB | ~2.6 GB |
| large-v1 | 2.9 GB | ~4.7 GB |
| large | 2.9 GB | ~4.7 GB |
| large-v3-turbo | 1.5 GB | ~2.6 GB |
Choose models based on your available resources: use tiny.en for development and testing, base.en for balanced performance, or large-v3-turbo for production quality with reasonable resource usage.
Let's now integrate Node.js Whisper with our frontend application. Update your src/client/transcriber.js file to add a new NodeWhisperTranscriber class that extends the base OpenAITranscriber class:
export class WhisperTranscriber extends OpenAITranscriber {
constructor(loadingIndicator, resultsBox, transcriptionText) {
super(loadingIndicator, resultsBox, transcriptionText);
this.apiUrl = '/api/transcribe?transcriber=whisper';
}
}
The only differences between this class and the OpenAITranscriber class are the model name added as query parameter to the apiUrl. Additionally, we need to add a third option to the models selection dropdown in the src/client/index.html file:
<select id="transcriptionMethod" class="bg-gray-50 border border-gray-300 text-gray-900 text-sm rounded-lg focus:ring-blue-500 focus:border-blue-500 block w-full p-2.5 dark:bg-gray-700 dark:border-gray-600 dark:placeholder-gray-400 dark:text-white dark:focus:ring-blue-500 dark:focus:border-blue-500">
<option value="api" selected>OpenAI API (Server)</option>
<option value="whisper">Whisper (Server)</option> <!-- New option -->
<option value="browser">Browser-based (Local)</option>
</select>
And to make the frontend logic aware of the new WhisperTranscriber class, we need to update the src/client/index.js file:
import {OpenAITranscriber, BrowserWhisperTranscriber, WhisperTranscriber} from './transcriber.js';
transcriptionMethodSelect.addEventListener('change', (e) => {
if (e.target.value === 'browser' && !whisperClient.isLoaded && !whisperClient.isLoading) {
loadWhisperModel();
transcriber = new BrowserWhisperTranscriber(loadingIndicator, resultsBox, transcriptionText, whisperClient);
} else if (e.target.value === 'whisper') {
transcriber = new WhisperTranscriber(loadingIndicator, resultsBox, transcriptionText);
} else {
transcriber = new OpenAITranscriber(loadingIndicator, resultsBox, transcriptionText);
}
});This code initializes the WhisperTranscriber class when the user selects the "Whisper (Server)" option from the transcription method dropdown.
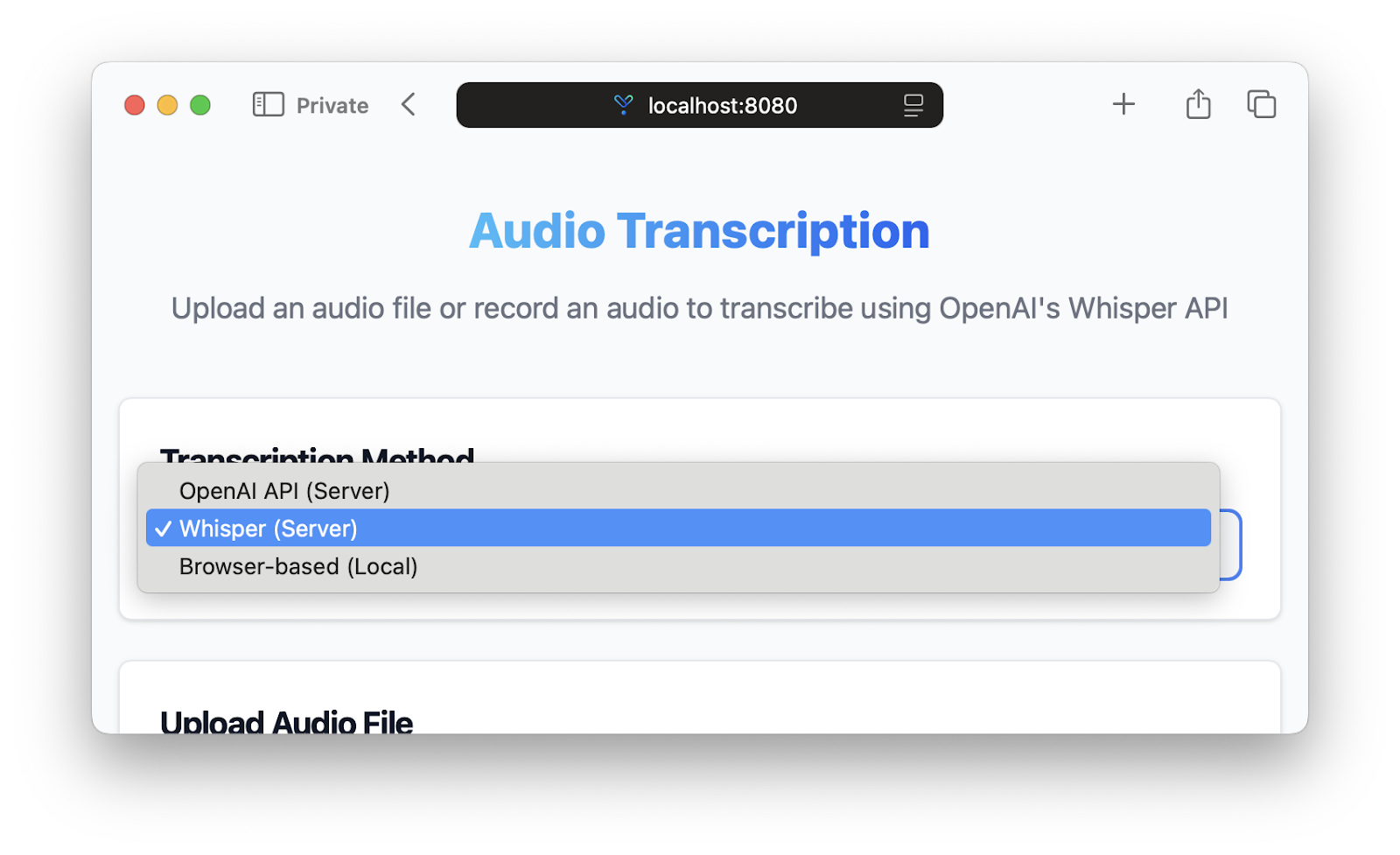
Navigate to http://localhost:8080 and test ensure the application now provides a flexibility to choose the three transcription methods: OpenAI API (Server), Whisper (Server) and Browser-based (Local).
Suggested Reads
- How to Build a JavaScript Audio Transcript Application
- Node.js Speech-to-Text with Punctuation, Casing, and Formatting
- Transcribe and generate subtitles for YouTube videos with Node.js
- Transcribe an audio file with Universal-1 in Node.js
- Summarize audio with LLMs in Node.js
- How To Convert Voice To Text Using JavaScript
- Filter profanity from audio files using Node.js
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts





