Speaker diarization improvements: new languages, increased accuracy
Announcing several improvements to our Speaker Diarization service, yielding a more accurate model that's available in more languages.



We've recently made a series of updates to our Speaker diarization service, which identifies who said what in a conversation, leading to improvements across a number of relevant benchmarks. In particular, our new Speaker Diarization model is up to 13% more accurate than its predecessor, and available in 5 additional languages.

Speaker Diarization improvements
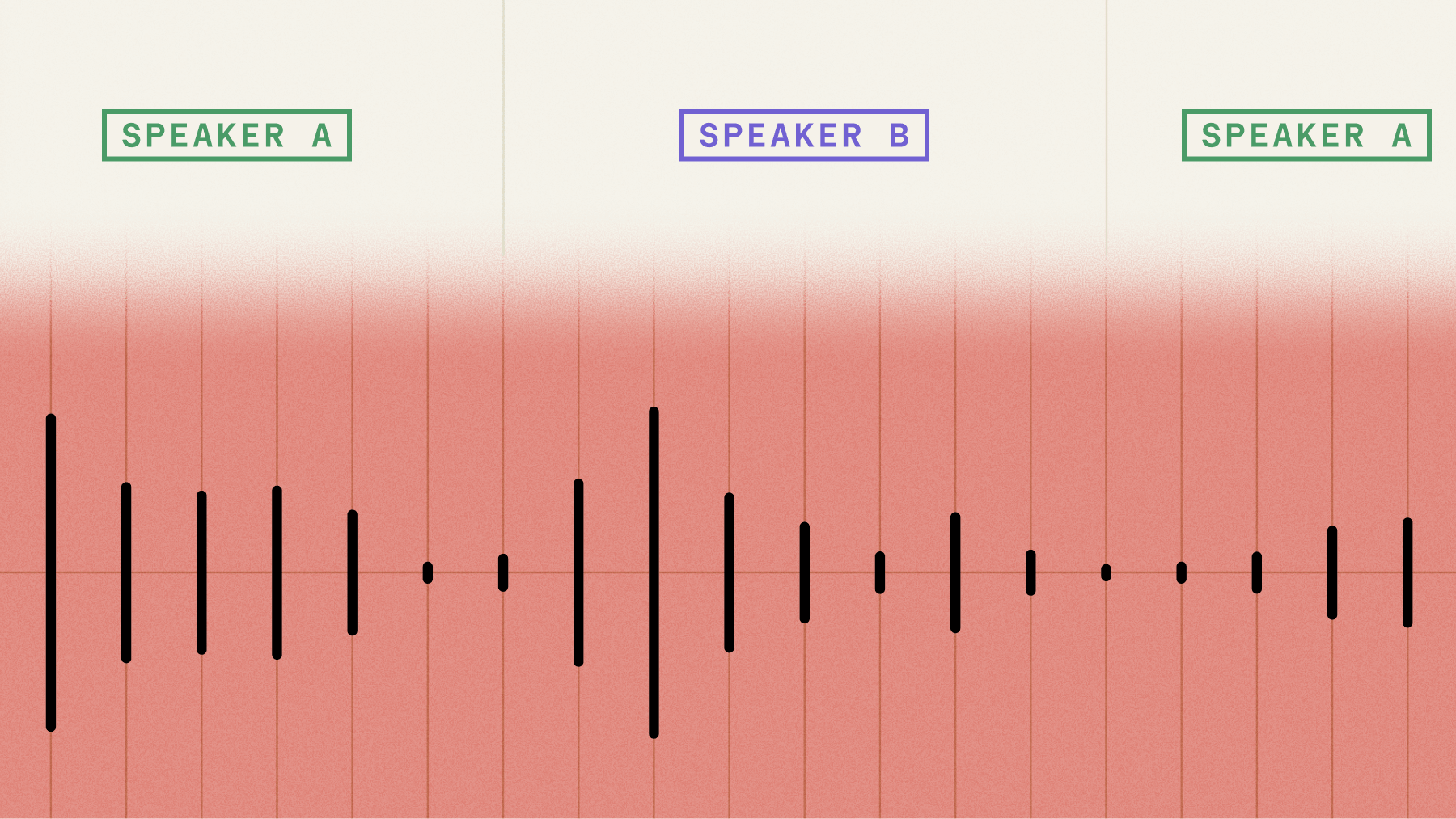
Speaker diarization is the process of identifying "who said what" in a conversation:

Speaker diarization increases the readability of transcripts and powers a wide range of downstream features in end-user applications, like automated video clipping, call coaching, and automated dubbing. As a result, improvements to speaker diarization have an outsized impact on end-user experiences for applications that process speech data. Here is an overview of the improvements to our Speaker Diarization model:
Diarization Accuracy
Our Speaker Diarization demonstrates a 10.1% improvement on Diarization Error Rate (DER), and a 13.2% improvement in concatenated minimum-permutation word error rate (cpWER), which are two widely-adopted metrics which measure the accuracy of a Diarization model
DER measures the fraction of time in the audio file to which an incorrect speaker was ascribed, while cpWER measures the number of errors a speech recognition model makes, where words with incorrectly-ascribed speakers are considered to be incorrect. The Word Error Rate (WER), a classic Speech Recognition accuracy metric, thus serves as a lower bound for the cpWER, which takes into account both transcription and diarization accuracy. Both DER and cpWER ultimately measure errors, so a lower value is better (indicates greater accuracy).
Here we report both the DER and cpWER of AssemblyAI's speaker diarization service and a number of alternative providers. Note that Whisper metrics are not reported here given that diarization is not a native capability of Whisper, but Gladia is based on Whisper and can therefore provide a ballpark estimate for those interested.

Speaker Number Accuracy
Our Speaker Diarization model demonstrates an 85.4% reduction in speaker count errors. A speaker count error occurs when a diarization model does not properly determine the number of unique speakers in an audio file. For example, if two people are having a conversation, then a Speaker Diarization model determining that any number of people other than 2 are speaking would be a speaker count error.
Properly determining the number of speakers in a file is important not only because it could affect diarization accuracy, but also because downstream features often rely on the number of speakers in a file - for example a call center software that expects two people on a call, the agent and customer.
Below we report the percentage of speaker count errors our Speaker Diarization model makes, along with several other providers. That is, the figure depicts the percentage of audio files processed in which an incorrect number of speakers were determined to be present by the model. AssemblyAI's Speaker Diarization model achieves the lowest rate at just 2.9%.

Increased Language Support
In addition to improvements to Speaker Diarization itself, we’ve increased language support. Speaker Diarization is now available in five additional languages:
- Chinese
- Hindi
- Japanese
- Korean
- Vietnamese
We now support Speaker Diarization in 16 languages — almost all languages supported by our Best tier, which you can browse here.
Where do these improvements come from?
These improvements to Speaker Diarization stem from a series of upgrades rolled out recently as part of our continual iteration and shipping. Three recent improvements in particular power many of these diarization improvements:
- Universal-1 - Our new Speech Recognition model Universal-1 demonstrates significant improvements in transcription accuracy, as well as in time stamp prediction, which is critical for aligning speaker labels with ASR outputs. Given that the transcript is a key input into the Speaker Diarization model, Universal-1's improvements propagated on to our Speaker Diarization service.
- Improved embedding model - we've made upgrades to the speaker-embedding model within our Speaker Diarization model, allowing the model to better identify and extract unique acoustical features to better differentiate between speakers.
- Sampling frequency - we've increased input sampling frequency from 8 kHz to 16 kHz, providing the Speaker Diarization model higher-resolution input data and therefore supplying it with more information to learn differences in speakers' voices.
Try it yourself
You can test our new diarization model for free in a no-code way by using our Playground.
Speaker Diarization use cases
Speaker Diarization is a powerful feature which can be used for a variety of use cases across industries. Here are a few use cases which would not be possible without performant Speaker Diarization:
Transcript readability
The increase in remote work over the past several years means that more meetings are happening remotely and being recorded for those who were not in attendance. Add to this the increase in webinars and recorded live events, and more speech data than ever is being recorded.
Many users prefer to read meeting and event transcripts and summaries rather than watch recordings, so the readability of these transcripts becomes critical to easily digesting the contents of recorded events.
Search experience in-product
Many Conversation Intelligence products and platforms offer search features, allowing users to e.g. search for instances in which "Person A" said "X". Diarization is a necessary requirement for these sorts of features, and accurate Diarization models ensure you're surfacing complete and accurate insights to end users.
Downstream analytics and LLMs
Many features are built on top of speech data and transcripts that allow information to be extracted from recorded speech in a meaningful way. Conversational intelligence features and Large Language Model (LLM) post-processing rely on knowing who said what to extract as much useful information as possible from this raw data. For example, customer service software can use speaker information to determine the ratio of time an agent speaks on a call, or to power coaching features that can help agents phrase questions in a more productive way.
Creator tool features
Transcription and Diarization lay at the absolute foundation of a range of downstream AI-powered features. Transcription and Diarization accuracy are therefore paramount in ensuring the utility, integrity, and accuracy of these downstream features, as reflected in the Machine Learning adage "garbage in, garbage out".
Here are a few downstream AI-powered features in the area of video processing and content creation which rely on Speaker Diarization:
- Automated dubbing: Automated dubbing allows creators to adapt their content to international audiences. For content with more than one speaker, diarization is needed to assign different AI translated voices to each speaker.
- Auto Speaker Focus: Video content can be made more engaging with auto speaker focus, which ensures the camera is focused on talking subjects during camera changes and automatically resizes videos to center active speakers. Performant speaker diarization is required to ensure the video is properly focused on the current speaker.
- AI-recommended short clips from long-form content: Short-form video content is an essential part of content creation pipelines. Automatically creating short-form content from long-form videos or podcasts helps creators get the most mileage out of the content they create. There are many creator tool companies which will automatically generate recommendations for short-form clips from long-form content. These platforms require accurate Speaker Diarization to ensure that their recommendation algorithms have accurate and complete information on which to base their recommendations.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.