How to perform speaker diarization in JavaScript
Learn speaker diarization in JavaScript with AssemblyAI's SDK. Complete guide with code examples for identifying who spoke when in audio recordings.


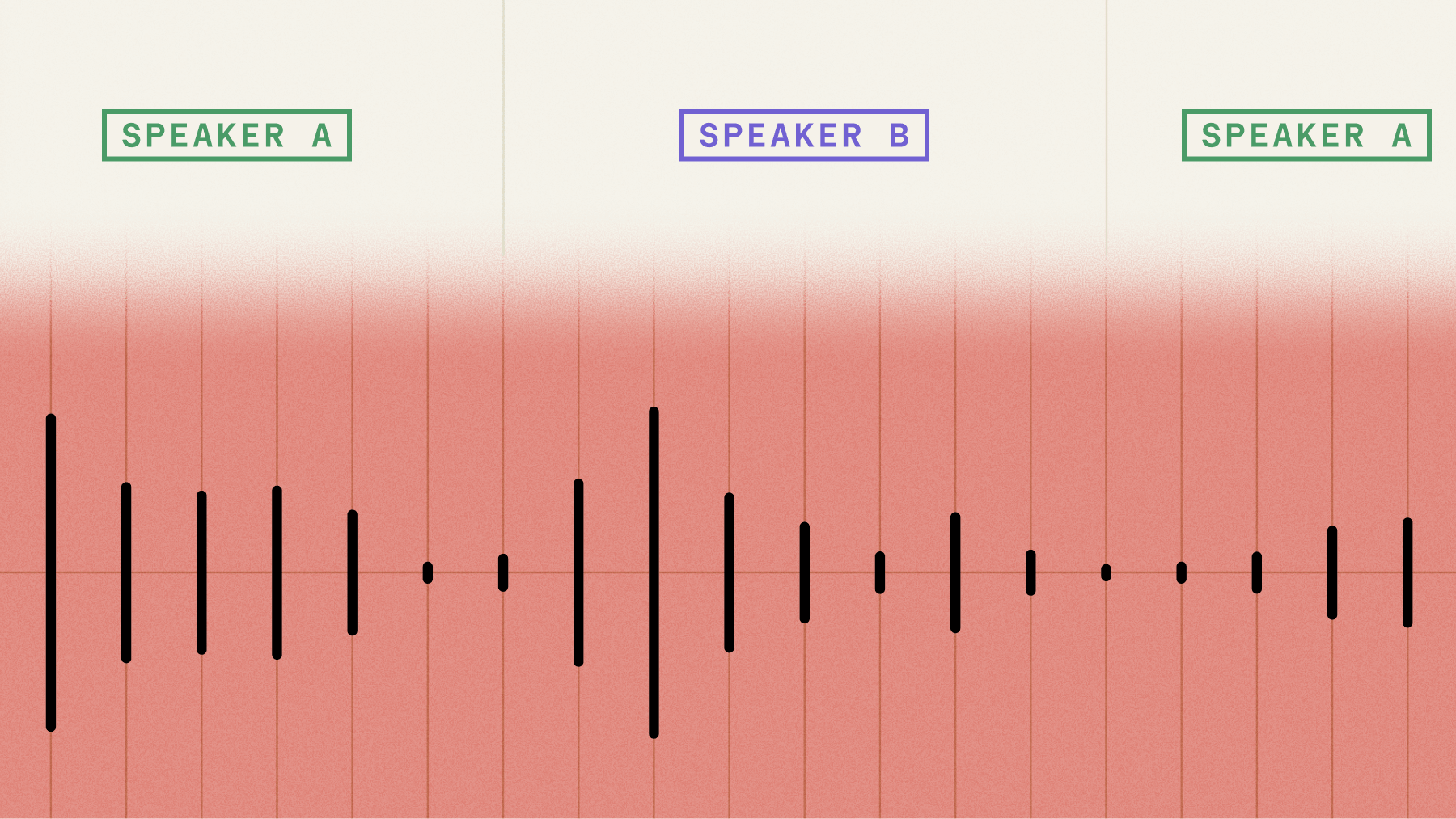
Speaker diarization answers "who spoke when?" in multi-speaker recordings by partitioning audio into segments based on speaker identity. This technology has become essential for applications like automated meeting transcriptions, podcast analysis, and customer service call processing.
This tutorial walks you through implementing speaker diarization in JavaScript with AssemblyAI's SDK—from setup to processing audio files and handling results.
Step-by-step guide to perform speaker diarization in JavaScript
Prerequisites and environment setup
Before implementing speaker diarization, ensure your development environment meets these requirements:
Install the AssemblyAI JavaScript SDK
Start by creating a new Node.js project and installing the required dependencies:
mkdir speaker-diarization-demo
cd speaker-diarization-demo
npm init -y
npm install assemblyai
Set up your API credentials
Create a .env file in your project root to store your AssemblyAI API key:
# .env
ASSEMBLYAI_API_KEY=your_api_key_here
Install the dotenv package to load environment variables:
npm install dotenv
Basic speaker diarization implementation
Create a new file called diarization.js with the following implementation:
require('dotenv').config();
const { AssemblyAI } = require('assemblyai');
// Initialize the AssemblyAI client
const client = new AssemblyAI({
apiKey: process.env.ASSEMBLYAI_API_KEY
});
async function performSpeakerDiarization(audioUrl) {
try {
// Configure transcription with speaker diarization
const params = {
audio: audioUrl,
speaker_labels: true, // Enable speaker diarization
speakers_expected: 2, // Optional: hint about number of speakers
};
// Submit transcription request
console.log('Submitting audio for transcription...');
const transcript = await client.transcripts.transcribe(params);
// Check if transcription was successful
if (transcript.status === 'error') {
console.error('Transcription failed:', transcript.error);
return;
}
// Display results
console.log('\n--- Speaker Diarization Results ---');
const detectedSpeakers = transcript.utterances ?
Math.max(...transcript.utterances.map(u =>
parseInt(u.speaker.replace('Speaker ', ''), 10))) : 'Unknown';
console.log(`Total speakers detected: ${detectedSpeakers}`);
// Process utterances with speaker labels
if (transcript.utterances) {
transcript.utterances.forEach((utterance, index) => {
const startTime = formatTime(utterance.start);
const endTime = formatTime(utterance.end);
console.log(`\nSpeaker ${utterance.speaker}: [${startTime} -
${endTime}]`);
console.log(`"${utterance.text}"`);
});
}
return transcript;
} catch (error) {
console.error('Error during speaker diarization:', error);
}
}
// Helper function to format timestamps
function formatTime(milliseconds) {
const seconds = Math.floor(milliseconds / 1000);
const minutes = Math.floor(seconds / 60);
const remainingSeconds = seconds % 60;
return `${minutes}:${remainingSeconds.toString().padStart(2, '0')}`;
}
// Example usage
const audioUrl = 'https://assembly.ai/sports_injuries.mp3';
performSpeakerDiarization(audioUrl);
Advanced configuration options
For better results, you can customize the speaker diarization configuration based on your specific use case:
Here's an enhanced implementation with additional configuration:
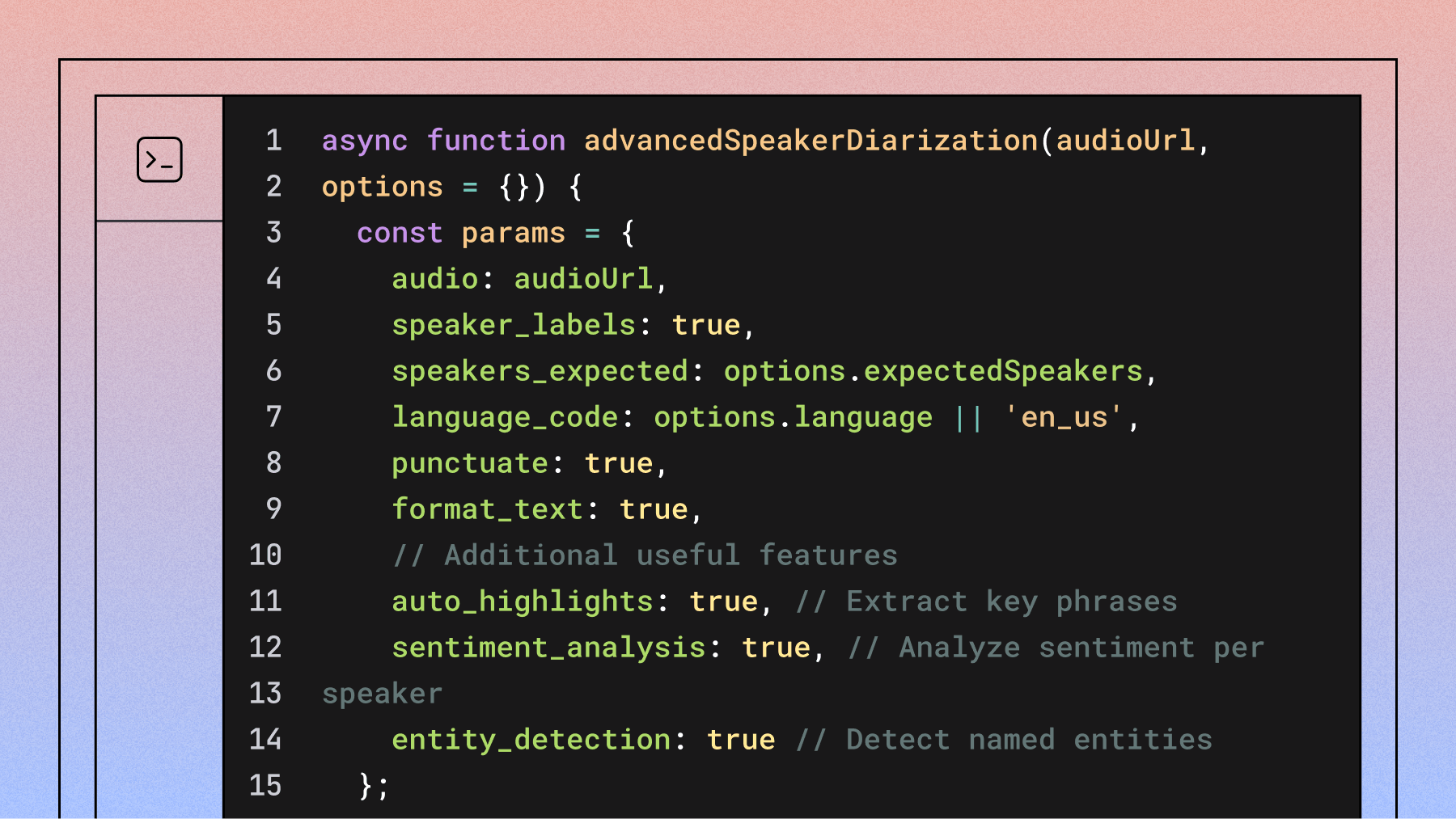
async function advancedSpeakerDiarization(audioUrl, options = {}) {
const params = {
audio: audioUrl,
speaker_labels: true,
speakers_expected: options.expectedSpeakers,
language: options.language,
punctuate: true,
format_text: true,
// Additional useful features
auto_highlights: true, // Extract key phrases
sentiment_analysis: true, // Analyze sentiment per speaker
entity_detection: true // Detect named entities
};
try {
const transcript = await client.transcripts.transcribe(params);
if (transcript.status === 'error') {
throw new Error(transcript.error);
}
// Process and analyze results
const analysis = analyzeSpeakerData(transcript);
return { transcript, analysis };
} catch (error) {
console.error('Advanced diarization failed:', error);
throw error;
}
}
function analyzeSpeakerData(transcript) {
const speakerStats = {};
if (!transcript.utterances) return speakerStats;
transcript.utterances.forEach(utterance => {
const speaker = utterance.speaker;
const duration = utterance.end - utterance.start;
const wordCount = utterance.text.split(' ').length;
if (!speakerStats[speaker]) {
speakerStats[speaker] = {
totalTime: 0,
utteranceCount: 0,
totalWords: 0,
averageWordsPerUtterance: 0
};
}
speakerStats[speaker].totalTime += duration;
speakerStats[speaker].utteranceCount += 1;
speakerStats[speaker].totalWords += wordCount;
speakerStats[speaker].averageWordsPerUtterance =
speakerStats[speaker].totalWords /
speakerStats[speaker].utteranceCount;
});
return speakerStats;
}
Handle local audio files
To process local audio files, you'll need to upload them first:
const fs = require('fs');
async function diarizeLocalFile(filePath) {
try {
// Upload local file - returns object with upload_url
console.log('Uploading audio file...');
const audioFile = await
client.files.upload(fs.createReadStream(filePath));
// Process with speaker diarization
const result = await
performSpeakerDiarization(audioFile.upload_url);
return result;
} catch (error) {
console.error('Error processing local file:', error);
}
}
// Example usage with local file
// diarizeLocalFile('./path/to/your/audio.mp3');
Error handling and best practices
Implement robust error handling for production applications:
async function robustSpeakerDiarization(audioSource, options = {}) {
const maxRetries = 3;
let attempt = 0;
while (attempt < maxRetries) {
try {
// Validate audio source
if (!audioSource) {
throw new Error('Audio source is required');
}
const params = {
audio: audioSource,
speaker_labels: true,
speakers_expected: options.expectedSpeakers,
// Note: The SDK handles polling automatically
};
const transcript = await client.transcripts.transcribe(params);
if (transcript.status === 'completed') {
return transcript;
} else if (transcript.status === 'error') {
throw new Error(`Transcription error: ${transcript.error}`);
}
} catch (error) {
attempt++;
console.warn(`Attempt ${attempt} failed:`, error.message);
if (attempt >= maxRetries) {
throw new Error(`Failed after ${maxRetries} attempts:
${error.message}`);
}
// Wait before retry
await new Promise(resolve => setTimeout(resolve, 1000 * attempt));
}
}
}
Conclusion
Speaker diarization in JavaScript becomes straightforward with AssemblyAI's SDK. Configure your environment, set speaker_labels: true in your transcription parameters, and process the utterances data.
AssemblyAI's SDK handles complex audio processing and AI model inference, letting you focus on integrating speaker identification into your application's workflow. Whether you're building meeting transcription tools, podcast analysis platforms, or customer service automation, speaker diarization provides the foundation for understanding multi-speaker conversations.
Speaker diarization with AssemblyAI's JavaScript SDK enables powerful multi-speaker audio analysis for meeting transcriptions, podcast platforms, and customer service automation. The straightforward API integration lets you focus on your application's unique features while leveraging enterprise-grade Speech AI capabilities.
For more advanced implementations, explore AssemblyAI's speaker diarization documentation and consider combining speaker identification with other audio intelligence features like sentiment analysis and entity detection.
Next steps:
- Experiment with different speakers_expected values for your use cases
- Integrate speaker diarization with your existing transcription workflows
- Check out our guide on speaker diarization vs speaker recognition to understand the differences
Related resources:
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts