How to convert voice to text in real time using JavaScript
Learn how to build real-time voice-to-text in JavaScript using AssemblyAI's Universal-Streaming API.


Voice agents and conversational AI applications require lightning-fast, accurate speech recognition to deliver natural interactions. This article shows how Universal-Streaming real-time speech recognition can be integrated into your JavaScript voice agent application, delivering immutable transcripts in ~300ms with intelligent endpointing designed specifically for conversational use cases.
Real-time voice-to-text in JavaScript with AssemblyAI
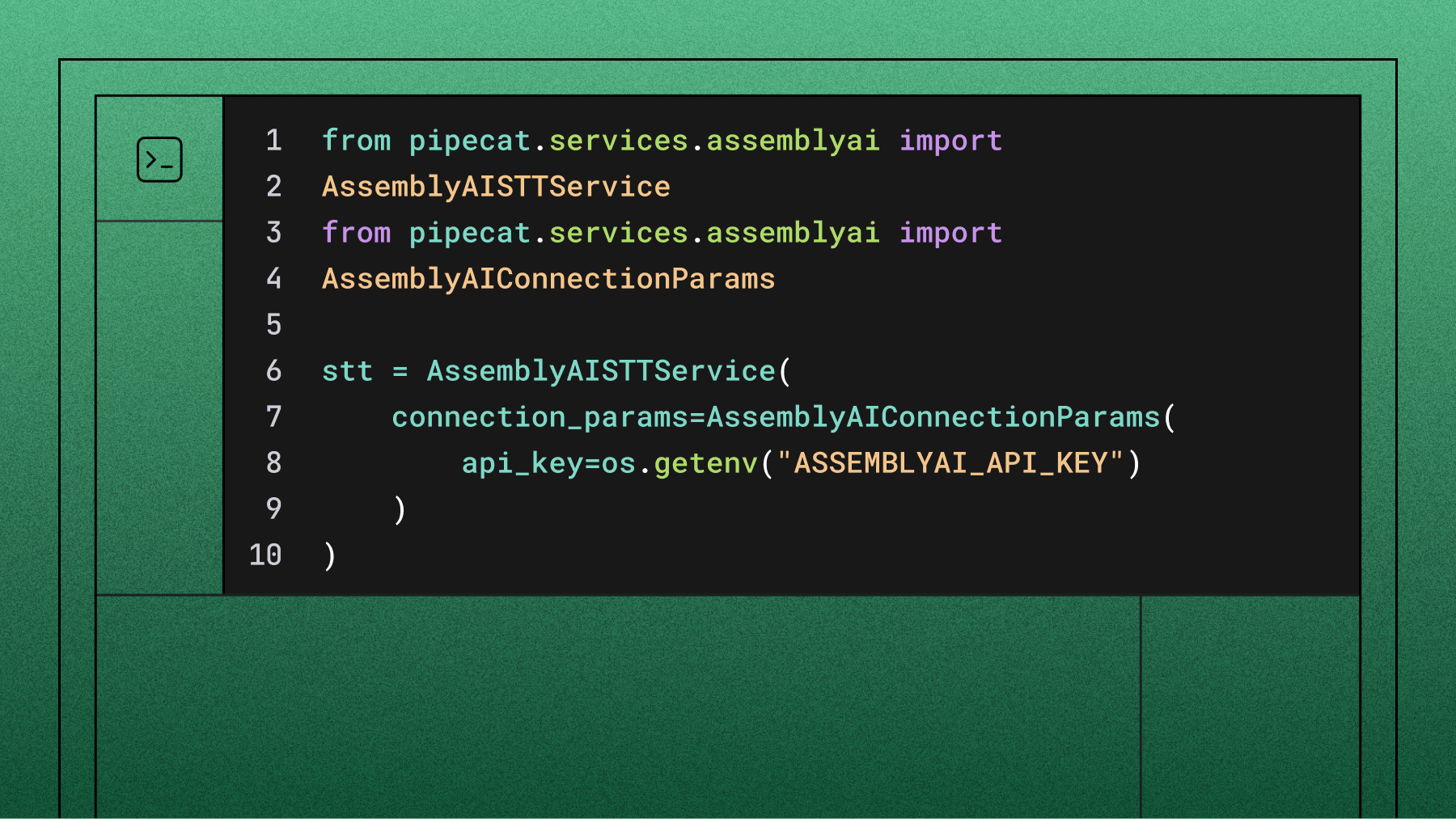
The easiest solution for voice agents is AssemblyAI's Universal-Streaming, a purpose-built Speech-to-Text API designed specifically for conversational AI applications. Unlike traditional transcription services, Universal-Streaming delivers immutable transcripts over WebSockets within ~300ms, with intelligent endpointing that understands when users finish speaking—perfect for voice agents that need to respond naturally without awkward pauses or premature interruptions.
Key advantages for voice applications:
- Immutable transcripts: No revision cycles that break conversation flow
- Sub-300ms latency: Lightning-fast response times for natural interactions
- Intelligent endpointing: Distinguishes thinking pauses from conversation completion
- Transparent pricing: $0.15/hour with unlimited concurrency
- Voice agent optimized: Built specifically for conversational AI use cases
Before getting started, we need to get a working API key. You can get one here and get started for free:
Step 1: Set up the HTML code and microphone recorder
Create a file index.html and add some HTML elements to display the text. To use a microphone, we embed RecordRTC, a JavaScript library for audio and video recording.
Additionally, we embed index.js, which will be the JavaScript file that handles the frontend part. This is the complete HTML code:
<!DOCTYPE >
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<script src="https://www.WebRTC-Experiment.com/RecordRTC.js"></script>
<body>
<header>
<h1 class="header__title">Real-Time Transcription</h1>
<p class="header__sub-title">Try AssemblyAI's Universal-Streaming endpoint!</p>
</header>
<div class="real-time-interface">
<p id="real-time-title" class="real-time-interface__title">Click start to begin recording!</p>
<button id="button" class="real-time-interface__button">Start</button>
<p id="message" class="real-time-interface__message"></p>
</div>
<script src="./index.js"></script>
</body>
</html>
Step 2: Set up the client with a WebSocket connection in JavaScript
Next, create the index.js and access the DOM elements of the corresponding HTML file. Additionally, we make global variables to store the recorder, the WebSocket, the sample rate, and the recording state.
// required dom elements
const buttonEl = document.getElementById('button');
const messageEl = document.getElementById('message');
const titleEl = document.getElementById('real-time-title');
messageEl.style.display = 'none';
let isRecording = false;
let socket = null;
let recorder = null;
const ENDPOINT = 'wss://streaming.assemblyai.com/v3/ws';
const SAMPLE_RATE = 16000;
Then we need to create only one function to handle all the logic. This function will be executed whenever the user clicks on the button to start or stop the recording. We toggle the recording state and implement an if-else-statement for the two states.
If the recording is stopped, we stop the recorder instance and close the socket. Before closing, we also need to send a JSON message that contains { "type": "Terminate" }. Then we need to implement the else part that is executed when the recording starts. To not expose the API key on the client side, we send a request to the backend and fetch a session token.
Then we establish a WebSocket that connects with wss://streaming.assemblyai.com/v3/ws.
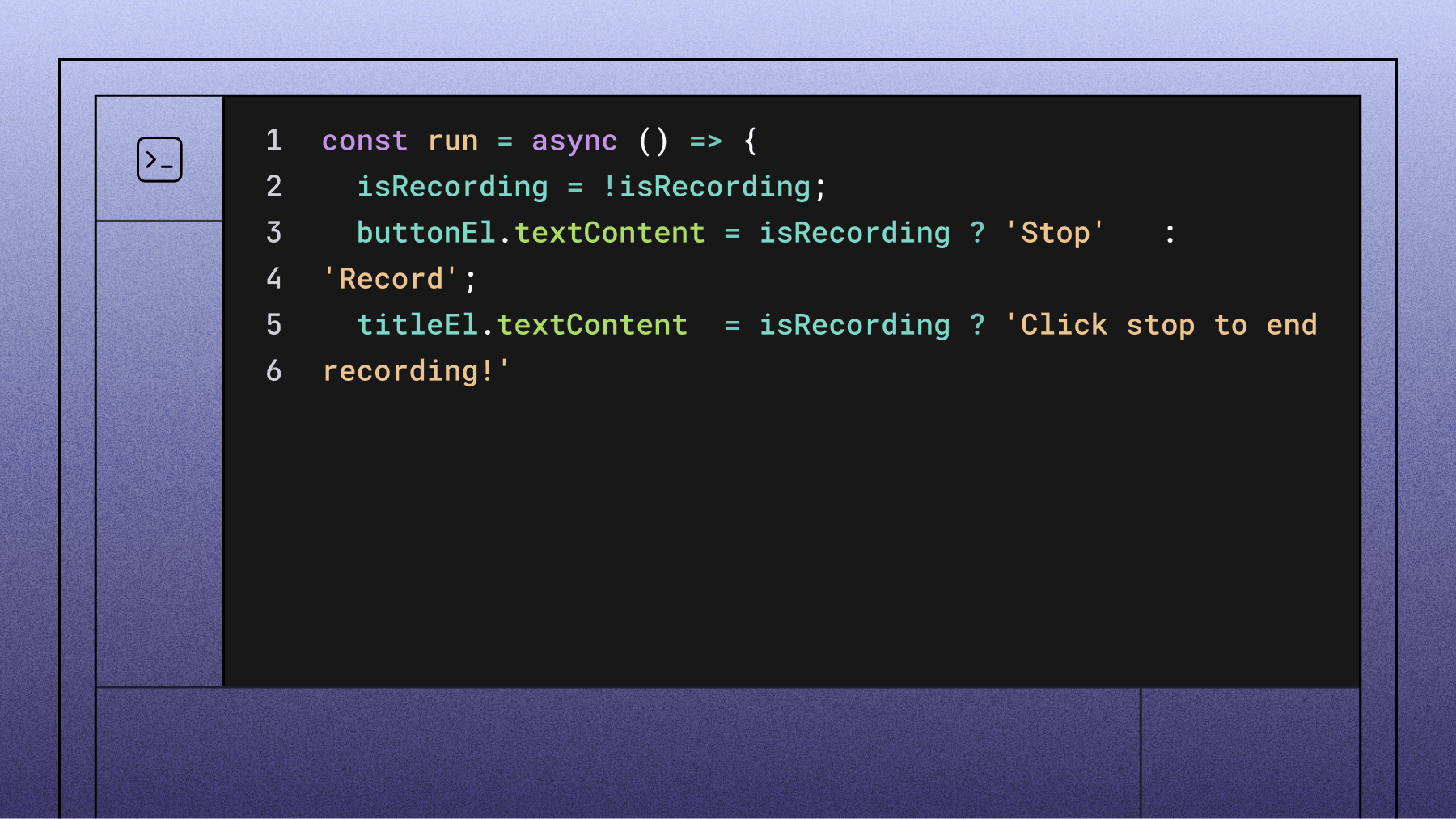
const run = async () => {
isRecording = !isRecording;
buttonEl.textContent = isRecording ? 'Stop' : 'Record';
titleEl.textContent = isRecording ? 'Click stop to end recording!'
: 'Click start to begin recording!';
if (!isRecording) {
if (recorder) { recorder.pauseRecording(); recorder = null; }
if (socket && socket.readyState === WebSocket.OPEN) {
socket.send(JSON.stringify({ type: 'Terminate' }));
socket.close();
}
socket = null;
return;
}
const { token, error } = await fetch('http://localhost:8000/token')
.then(r => r.json());
if (error) { alert(error); return; }
// 2. Open the v3 WebSocket
socket = new WebSocket(
`${ENDPOINT}?sample_rate=${SAMPLE_RATE}&encoding=pcm_s16le&token=${token}`
);
//To Do Add Websocket event handlers
}
buttonEl.addEventListener('click', run);
For the socket, we have to take care of the events onmessage, onerror, onclose, and onopen. In the onmessage event we parse the incoming Universal-Streaming response data and handle the turn-based transcript format.
In the onopen event we initialize the RecordRTC instance and then send the audio data. The other two events can be used to close and reset the socket. This is the remaining code for the else block:
let committedText = '';
socket.onmessage = ({ data }) => {
const msg = JSON.parse(data);
if (msg.type === 'Begin') {
console.log(`Session ${msg.id} started (expires ${new Date(msg.expires_at * 1000).toLocaleTimeString()})`);
return;
}
if (msg.type === 'Turn') {
// live text for the current turn
messageEl.textContent = committedText + msg.transcript;
if (msg.end_of_turn) {
committedText += (msg.turn_is_formatted ? msg.transcript : msg.transcript + '.')
+ ' ';
console.log('End-of-turn, confidence =', msg.end_of_turn_confidence.toFixed(3));
}
return;
}
if (msg.type === 'Termination') {
console.log('Server terminated the session');
}
};
socket.onerror = console.error;
socket.onclose = () => { console.log('WebSocket closed'); socket = null; };
// 3. Capture microphone audio once the socket is open
socket.onopen = () => {
messageEl.style.display = '';
navigator.mediaDevices.getUserMedia({ audio: true })
.then(stream => {
recorder = new RecordRTC(stream, {
type: 'audio',
mimeType: 'audio/webm;codecs=pcm_s16le',
recorderType: StereoAudioRecorder,
desiredSampRate: SAMPLE_RATE,
numberOfAudioChannels:1,
bufferSize: 4096,
timeSlice: 250, // ≈250 ms chunks
ondataavailable: blob => {
if (socket && socket.readyState === WebSocket.OPEN) {
blob.arrayBuffer().then(buffer => socket.send(buffer));
}
}
});
recorder.startRecording();
})
.catch(console.error);
};
Step 3: Set up a server with Express.js to handle authentication
Lastly, we need to create another file server.js that handles authentication. Here we create a server with one endpoint that creates a temporary authentication token by sending a GET request to https://streaming.assemblyai.com/v3/token.
Important note: Temporary tokens must have an expiration time between 1 and 600 seconds.
To use it, we have to install Express.js, Axios, and cors:
bash
$ npm install express axios cors
And this is the full code for the server part:
const express = require('express');
const axios = require('axios');
const cors = require('cors');
const app = express();
app.use(express.json());
app.use(cors());
app.get('/token', async (req, res) => {
try {
const response = await axios.get('https://streaming.assemblyai.com/v3/token?expires_in_seconds=60',
{ headers: { authorization: 'YOUR_TOKEN' } });
const { data } = response;
res.json(data);
} catch (error) {
const {response: {status, data}} = error;
res.status(status).json(data);
}
});
app.set('port', 8000);
const server = app.listen(app.get('port'), () => {
console.log(`Server is running on port ${server.address().port}`);
});
This endpoint on the backend will send a valid session token to the frontend whenever the recording starts. And that's it! You can find the whole code in our GitHub repository.
Run the JavaScript files for real-time voice and speech recognition
Now we must run the backend and frontend part. Start the server with:
bash
$ node server.js
And then serve the frontend site with the serve package:
bash
$ npm i --global serve
$ serve -l 3000
Now you can visit http://localhost:3000, start the voice recording, and see the real-time transcription in action!
Key features and pricing
Universal-Streaming delivers purpose-built capabilities for voice agents:
- Transparent pricing: $0.15/hour based on session duration (not audio duration)
- Language support: Currently available in English only
- Unlimited concurrency: Scale from 5 to 50,000+ streams without caps
- Immutable transcripts: No revision cycles that break conversation flow
- Intelligent endpointing: Built-in end-of-turn detection optimized for voice agents
For traditional transcription use cases, AssemblyAI also offers pre-recorded Speech-to-Text starting at $0.27/hour with support for 99+ languages.
Real-time transcription video tutorial
Watch our video tutorial to see an example of real-time transcription:
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts