How to convert an MP3 file to text with an API
Recent advances in deep learning technology have made speech recognition available to developers at large. Here, we go over how to convert an MP3 file to text with AssemblyAI's Speech-to-Text API.


Converting MP3 files to text programmatically has become essential for developers building modern applications. Whether you're creating a podcast transcription service, building accessibility features, or analyzing audio content at scale, you need a reliable way to convert audio to text through code. This tutorial shows you how to implement MP3 to text conversion using AssemblyAI's Speech-to-Text API with proper error handling and optimization techniques.
Let's build a complete implementation that handles real-world scenarios.
Prerequisites and setup
Before we start, you'll need a few things:
- An AssemblyAI account and API key: Sign up for a free account on the AssemblyAI dashboard to get your key.
- Python installed: This tutorial uses Python, but you can adapt the concepts to any language.
- The requests library: If you don't have it, install it by running pip install requests in your terminal. This library makes it simple to send HTTP requests to our API.
A quick primer on automatic transcription
Converting MP3 files to text requires three API calls: upload your file, submit a transcription request, then poll for results. AssemblyAI's Speech-to-Text API handles this workflow with human-level accuracy.
This technology was previously limited to enterprise companies, but cloud APIs now make speech recognition accessible to any developer.
In this example, we'll use AssemblyAI's API for automatic transcription. AssemblyAI's API is not only free to start, fast, and super simple to use, but also comes with a bunch of plug and play features. In the section below I'll show you how to convert an MP3 file to text using AssemblyAI's API.
Convert an MP3 file to text
To start converting an MP3 file to text, you'll need to get an API key for AssemblyAI's speech-to-text API. Once you sign up, you can find your API key located in the console where I've circled in red in the picture below. You should store this as an environment variable or a variable in a separate configuration file.
If you don't already have an MP3 file downloaded to start, I have an MP3 file you can download. I chose a video on how our brains process speech, a TED-ed talk by Gareth Gaskell. It talks about how we, as humans (not the machines), understand language.
Alright, on to how we actually convert this MP3 file to a text file with AssemblyAI's speech recognition API. The entire process can be broken down into 3 simple steps:
- Upload MP3 file to AssemblyAI's API
- Start transcription job
- Get result of transcription job
Now to the code!
First, let's import the necessary library and set up our API credentials:
import requests
import time
# Store your API key securely
auth_key = '<your assemblyai api key here>'
headers = {
"authorization": auth_key,
"content-type": "application/json"
}
Upload your MP3 file using a generator function for memory efficiency:
def read_file(filename):
with open(filename, 'rb') as _file:
while True:
data = _file.read(5242880) # Read in 5MB chunks
if not data:
break
yield data
Key technical details:
- Chunk size: 5242880 bytes (5MB) prevents memory issues with large files
- Generator pattern: Streams data without loading entire file into memory
- Binary mode: 'rb' flag ensures proper audio file handling
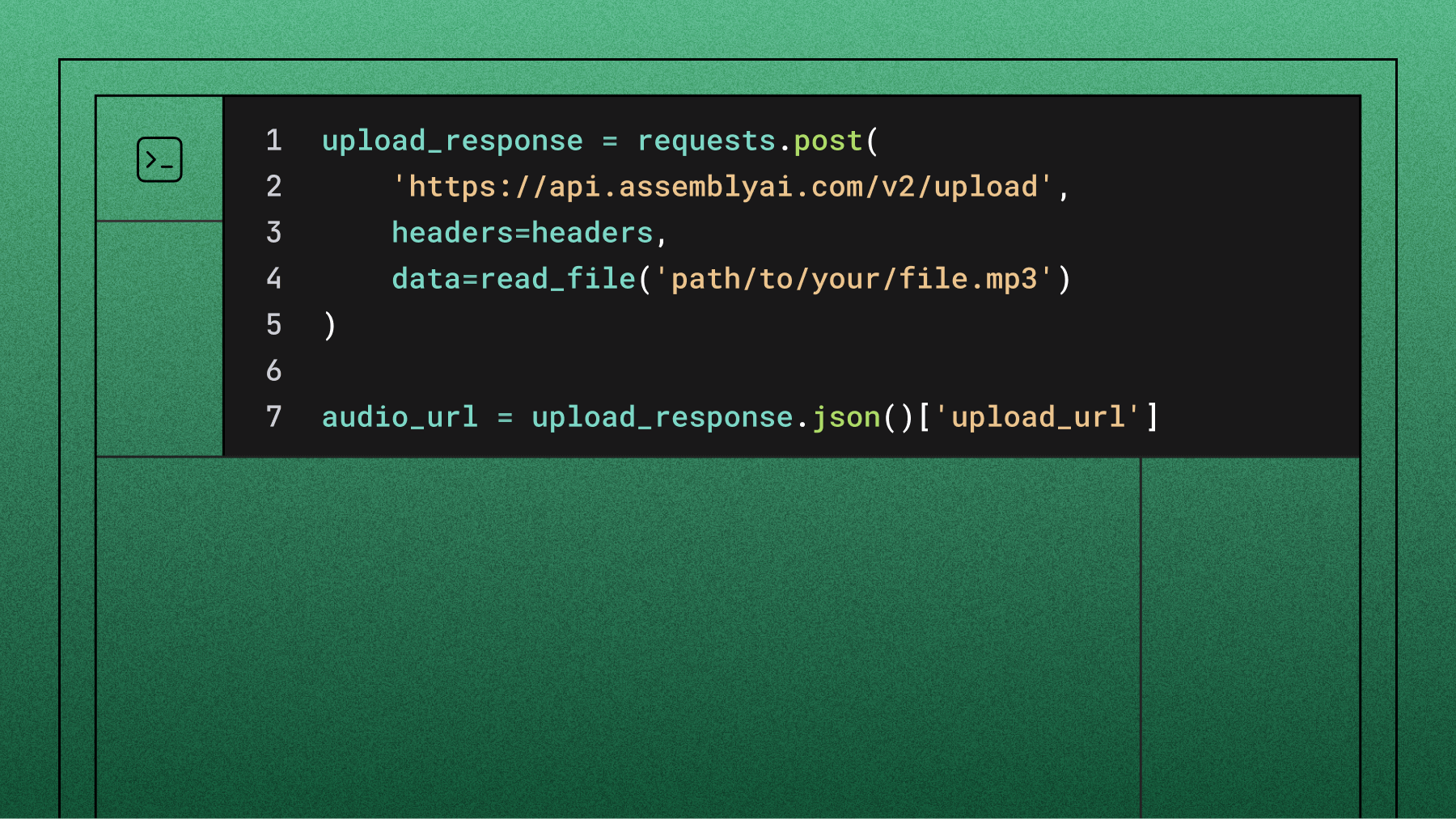
# Upload the file
upload_response = requests.post(
'https://api.assemblyai.com/v2/upload',
headers=headers,
data=read_file('path/to/your/file.mp3')
)
audio_url = upload_response.json()['upload_url']
In the JSON response, there will be an upload_url key that points to the file we uploaded to AssemblyAI. This file is only accessible to AssemblyAI's servers, so you won't be able to access this URL in your browser.
Below, we'll pass the upload_url to the transcription endpoint, which tells AssemblyAI to convert our MP3 file to text:
transcript_request = {'audio_url': audio_url}
endpoint = "https://api.assemblyai.com/v2/transcript"
transcript_response = requests.post(endpoint, json=transcript_request, headers=headers)
transcript_id = transcript_response.json()['id']
Save the returned transcript ID to poll for completion:
# Poll for transcription completion
polling_endpoint = f"https://api.assemblyai.com/v2/transcript/{transcript_id}"
while True:
polling_response = requests.get(polling_endpoint, headers=headers)
status = polling_response.json()['status']
if status == 'completed':
# Save the transcription to a text file
with open(f'{transcript_id}.txt', 'w') as f:
f.write(polling_response.json()['text'])
print(f'Transcript saved to {transcript_id}.txt')
break
elif status == 'error':
print(f"Transcription failed: {polling_response.json()['error']}")
break
else:
print(f"Status: {status}")
time.sleep(5) # Wait before polling again
It's as simple as that. All we have to do to convert an MP3 file to text using AssemblyAI's speech-to-text API is get an API key, upload our MP3 file to the API, and make 2 simple API calls!
Handle errors and optimize performance
Production implementations require robust error handling and polling strategies.
Status handling:
- processing → transcription in progress
- completed → transcript ready
- error → check error message in response
Polling best practices:
- Add 5-second delays between requests
- Implement exponential backoff for retries
- Set maximum timeout (10 minutes recommended)
Here's a more robust implementation with proper error handling and retry logic:
import requests
import time
import sys
def transcribe_with_retry(audio_url, headers, max_retries=3):
"""Transcribe audio with automatic retry on failure"""
for attempt in range(max_retries):
try:
# Submit transcription request
transcript_response = requests.post(
"https://api.assemblyai.com/v2/transcript",
json={'audio_url': audio_url},
headers=headers
)
if transcript_response.status_code != 200:
print(f"Error submitting transcript: {transcript_response.status_code}")
if attempt < max_retries - 1:
time.sleep(5 * (attempt + 1)) # Exponential backoff
continue
return None
transcript_id = transcript_response.json()['id']
# Poll with timeout
polling_endpoint = f"https://api.assemblyai.com/v2/transcript/{transcript_id}"
timeout = time.time() + 600 # 10 minute timeout
while time.time() < timeout:
polling_response = requests.get(polling_endpoint, headers=headers)
status = polling_response.json()['status']
if status == 'completed':
return polling_response.json()
elif status == 'error':
error_msg = polling_response.json().get('error', 'Unknown error')
print(f"Transcription error: {error_msg}")
return None
time.sleep(5)
print("Transcription timed out")
return None
except requests.exceptions.RequestException as e:
print(f"Network error on attempt {attempt + 1}: {e}")
if attempt < max_retries - 1:
time.sleep(5 * (attempt + 1))
else:
return None
return None
For large-scale processing, consider implementing batch processing to handle multiple files efficiently:
def batch_transcribe(file_paths, headers):
"""Process multiple MP3 files in parallel"""
transcripts = {}
# Submit all files for transcription
for path in file_paths:
with open(path, 'rb') as f:
upload_response = requests.post(
'https://api.assemblyai.com/v2/upload',
headers=headers,
data=f
)
audio_url = upload_response.json()['upload_url']
transcript_response = requests.post(
"https://api.assemblyai.com/v2/transcript",
json={'audio_url': audio_url},
headers=headers
)
transcripts[path] = transcript_response.json()['id']
# Poll for all results
results = {}
for path, transcript_id in transcripts.items():
polling_endpoint = f"https://api.assemblyai.com/v2/transcript/{transcript_id}"
# Implementation continues with polling logic...
return results
Advanced audio transcription features
Converting an MP3 to text is just the beginning. With the same API call, you can unlock deeper insights from your audio data. Companies like Veed and CallSource use AssemblyAI to power their platforms.
Enable advanced features with simple boolean flags:
- Speaker Diarization: speaker_labels: true
- Sentiment Analysis: sentiment_analysis: true
- Entity Detection: entity_detection: true
- Content Safety: content_safety: true
transcript_request = {
'audio_url': audio_url,
'speaker_labels': True,
'sentiment_analysis': True
}
Here's how to enable these advanced features:
transcript_request = {
'audio_url': audio_url,
'speaker_labels': True, # Enable speaker diarization
'sentiment_analysis': True, # Enable sentiment analysis
'entity_detection': True, # Detect entities like names and locations
'auto_highlights': True, # Automatically identify key moments
'content_safety': True, # Flag potentially sensitive content
'iab_categories': True # Classify content into IAB taxonomy categories
}
When you enable speaker diarization, the response includes detailed speaker information:
# Process speaker diarization results
if result['speaker_labels']:
for utterance in result['utterances']:
speaker = utterance['speaker']
text = utterance['text']
start = utterance['start']
end = utterance['end']
print(f"Speaker {speaker} ({start}ms - {end}ms): {text}")
For sentiment analysis, each sentence includes sentiment scores:
# Process sentiment analysis results
if result['sentiment_analysis_results']:
for sentence in result['sentiment_analysis_results']:
sentiment = sentence['sentiment'] # POSITIVE, NEGATIVE, or NEUTRAL
confidence = sentence['confidence']
text = sentence['text']
print(f"{sentiment} ({confidence:.2f}): {text}")
You can also process audio files in different formats and from various sources:
# Transcribe from a URL instead of uploading
transcript_request = {
'audio_url': 'https://example.com/podcast.mp3'
}
# Enable language detection for non-English content
transcript_request = {
'audio_url': audio_url,
'language_detection': True # Automatically detect the language
}
Frequently asked questions about MP3 to text conversion
How do I transcribe large MP3 files?
Upload large files to cloud storage first, then pass the public URL to our API to avoid timeouts.
What other audio formats can I use?
Our API supports a wide range of formats beyond MP3, including WAV, FLAC, M4A, and OGG. You can submit them using the exact same API workflow described in this tutorial without any changes to your code.
How can I improve transcription accuracy for specific terms?
If your audio contains niche terminology, product names, or unique acronyms, you can use the word_boost parameter. This feature lets you provide a list of important words, increasing the probability that our AI models will recognize them correctly in the transcript.
What are the rate limits and how do I handle them?
Rate limits scale with your account tier. Handle 429 status codes with exponential backoff and 5-second delays between retries.
How do I implement real-time MP3 transcription?
Use AssemblyAI's Streaming Speech-to-Text API with WebSocket connections for real-time processing instead of batch uploads.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.