How to identify languages in audio data using Python
Learn how to use Python to automatically identify languages in audio files.



Working with audio content in different languages has become increasingly common. Whether you're developing a transcription service, creating a language learning app, or analyzing phone calls and meetings with AI, the ability to automatically identify the language spoken in an audio file is invaluable.
This blog post teaches you step-by-step how to use Python and the AssemblyAI API to identify languages in audio data - a process also known as automatic language detection (ALD).
We’ll also learn how we can use language confidence scores to ensure high accuracy in our application, and explore the best ALD models and supported languages.
#Set up your environment
To follow along with this tutorial, you’ll need to have Python installed and an AssemblyAI API key - you can get one for free here:
The easiest way to interact with the AssemblyAI API is by using one of the official SDKs. Install the AssemblyAI Python SDK with the following command:
pip install -U assemblyai
Then, create a new file main.py, import the library, and set your API key:
import assemblyai as aai
aai.settings.api_key = "YOUR_API_KEY"
#Implement language detection
To perform language detection, we need to transcribe an audio file with language detection enabled. To see what languages are supported, see the section below.
Specify the location of the audio file you would like to use. This location can be either a local file path or a publicly-accessible URL. Add the following lines to main.py, optionally changing the audio_file to a file of your choice:
💡
Minimum audio length: To reliably identify the dominant language, the file must contain at least 50 seconds of spoken audio. This ensures enough linguistic data for accurate detection.
# You can use a local filepath
audio_file = "./public_benchmarking_portugese.mp3"# Or a remote URL
audio_file = "https://storage.googleapis.com/aai-web-samples/public_benchmarking_portugese.mp3"
To enable language detection, create an aai.TranscriptionConfig object and set language_detection to True. Then, create an aai.Transcriber object and call the transcribe function to perform language identification while transcribing the file. Pass in both the audio_url and the config you specified:
config = aai.TranscriptionConfig(
language_detection=True
)
transcriber = aai.Transcriber()
transcript = transcriber.transcribe(audio_url, config)
This code transcribes the audio file and automatically detects the dominant language.
The response includes a "language_code" field that you can then print:
print(transcript.json_response["language_code"])# 'pt'
Finally, run your code with python main.py and inspect the output.
#Use the confidence score and confidence threshold
Confidence score: The API returns a confidence score for the detected language, ranging from 0.0 (low confidence) to 1.0 (high confidence). You can access the score like this:
print(transcript.json_response["language_confidence"])# 0.9969
Set a confidence threshold: To ensure high accuracy in your application, you can set a minimum confidence threshold for language detection:
threshold = 0.4
config = aai.TranscriptionConfig(
language_detection=True,
language_confidence_threshold=threshold
)
If the language confidence is below this threshold, an error will be returned. The error can be accessed through the transcript.error variable. Here’s an example:
transcript = transcriber.transcribe(audio_url, config)print(transcript.error)# detected language 'en', confidence 0.0401, is below the requested confidence threshold value of '0.3'
Route to a default language: If the confidence score is below your user defined threshold, you can define a default language as fallback and set the language manually:
if (
transcript.error
and transcript.json_response["language_confidence"] < threshold
):
default_language = "es"
config = aai.TranscriptionConfig(language_code=default_language)
transcript = transcriber.transcribe(audio_url, config)
#Supported languages for language detection
AssemblyAI offers two different model tiers: Best and Nano. The Best tier is designed for the highest accuracy possible and currently supports 17 languages, whereas Nano is a more cost-efficient tier with support for 99 different languages.
For a list of all supported languages in both tiers, see our developer documentation.
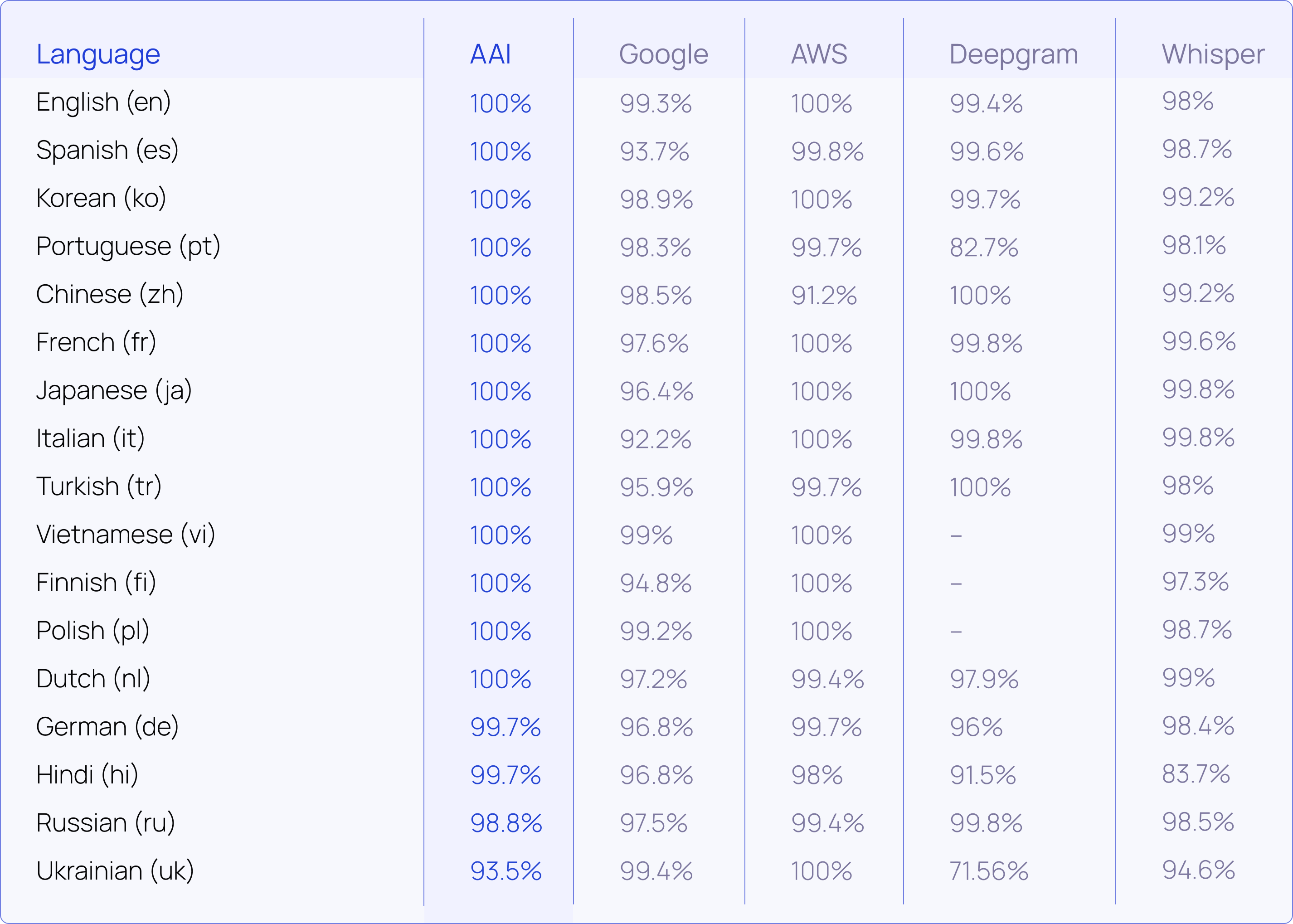
#Benchmarks of different language detection models
AssemblyAI recently introduced language detection model updates with increased performance. Using the industry-standard FLEURS benchmark, we've measured our model against four popular model providers and achieved best in class accuracy in 15 of 17 languages:
#Perform language detection separately from the transcription process
If you’re only interested in the detected language and not in the transcribed text, you can slice the first 60 seconds of audio and run it through the models.
While it’s not possible to completely separate language detection from the transcription process, we recommend to enable audio slicing by setting the audio_end_at configuration parameter:
config = aai.TranscriptionConfig(
audio_end_at=60000, # first 60 seconds (in milliseconds)
language_detection=True,
)
transcript = transcriber.transcribe(audio_url, config)
You can change this parameter to a duration of your choice. Keep in mind that the longer the audio duration, the more accurate the language detection results will be.
#Conclusion
Implementing language detection in audio data using Python and AssemblyAI is straightforward and powerful. By leveraging this capability, you can create more intelligent and user-friendly applications that work seamlessly across multiple languages.
Remember to handle edge cases, such as audio files shorter than 50 seconds, and utilize the confidence score if you want to ensure high language detection accuracy in your application.
To learn more about how to analyze audio and video files with AI, check out more of our blog, like this article on using Claude 3.5 Sonnet with audio data. Alternatively, feel free to check out our YouTube channel for educational videos on AI and AI-adjacent projects, like this tutorial on how to automatically detect speakers in audio files:
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts