Cut transcription costs with guardrails
Filter low-value audio before it reaches your systems. Apply efficiency controls that block silence and hold music at the API level.
Start free
Recent market analysis projects the conversational AI market will reach $41.39 billion by 2030. As voice AI adoption accelerates, processing efficiency becomes a competitive advantage, not just a cost consideration.
Business impact of voice AI guardrails
Voice AI guardrails transform compliance from a cost center into a competitive advantage. Organizations implementing comprehensive guardrail strategies report improvements across three critical business dimensions.
Business Impact Area | Without Guardrails | With Guardrails | Typical ROI Timeline |
|---|
Compliance Risk | Potential HIPAA/PCI violations | Automated protection | Immediate |
Processing Efficiency | Manual review overhead | Automated filtering | First billing cycle |
Data Quality | Degraded model performance | Clean training data | 2-4 weeks |
Compliance penalty avoidance and risk mitigation
Every unredacted PHI exposure or payment card data leak represents potential regulatory action. Voice AI guardrails eliminate this exposure systematically. Healthcare organizations processing thousands of patient conversations daily can operate with confidence, knowing sensitive medical information never enters their storage systems.
Financial services companies handling payment discussions maintain PCI compliance without manual review processes or post-processing scrubbing. The business value extends beyond penalty avoidance. Organizations with robust guardrails accelerate their voice AI deployments because legal and compliance teams have pre-approved safeguards in place.
Operational efficiency gains and cost reduction
Manual compliance review processes consume significant resources. According to a 2023 report, organizations that use security AI and automation extensively have average data breach costs that are $1.76 million lower than those that do not. Teams spending hours reviewing transcripts for sensitive data can redirect that effort toward higher-value work when guardrails handle protection automatically. Contact centers report dramatic reductions in quality assurance overhead when profanity filtering and content moderation happen during transcription rather than through manual review.
Processing efficiency delivers immediate cost savings. Organizations implementing speech threshold controls eliminate charges for non-productive audio like hold music and silence. Meeting platforms avoid transcribing empty conference rooms while healthcare applications skip ambient noise between patient visits.
Quality improvement and competitive advantages
Clean training data produces better AI models. When guardrails filter profanity, irrelevant content, and low-quality audio before it enters training pipelines, the resulting models demonstrate improved accuracy and reliability. Contact centers using filtered transcripts for agent coaching see better performance outcomes than those working with unfiltered data; for example, one platform found that its AI-powered coaching tools helped customers achieve a 15% higher win rate on average.
Organizations with comprehensive guardrails move faster in competitive markets. While competitors struggle with compliance concerns or data quality issues, companies with robust protection launch voice AI features confidently. This acceleration creates market advantages that compound over time.
Safety guardrails
Safety guardrails prevent compliance violations by automatically removing or blocking sensitive information before it reaches your systems.
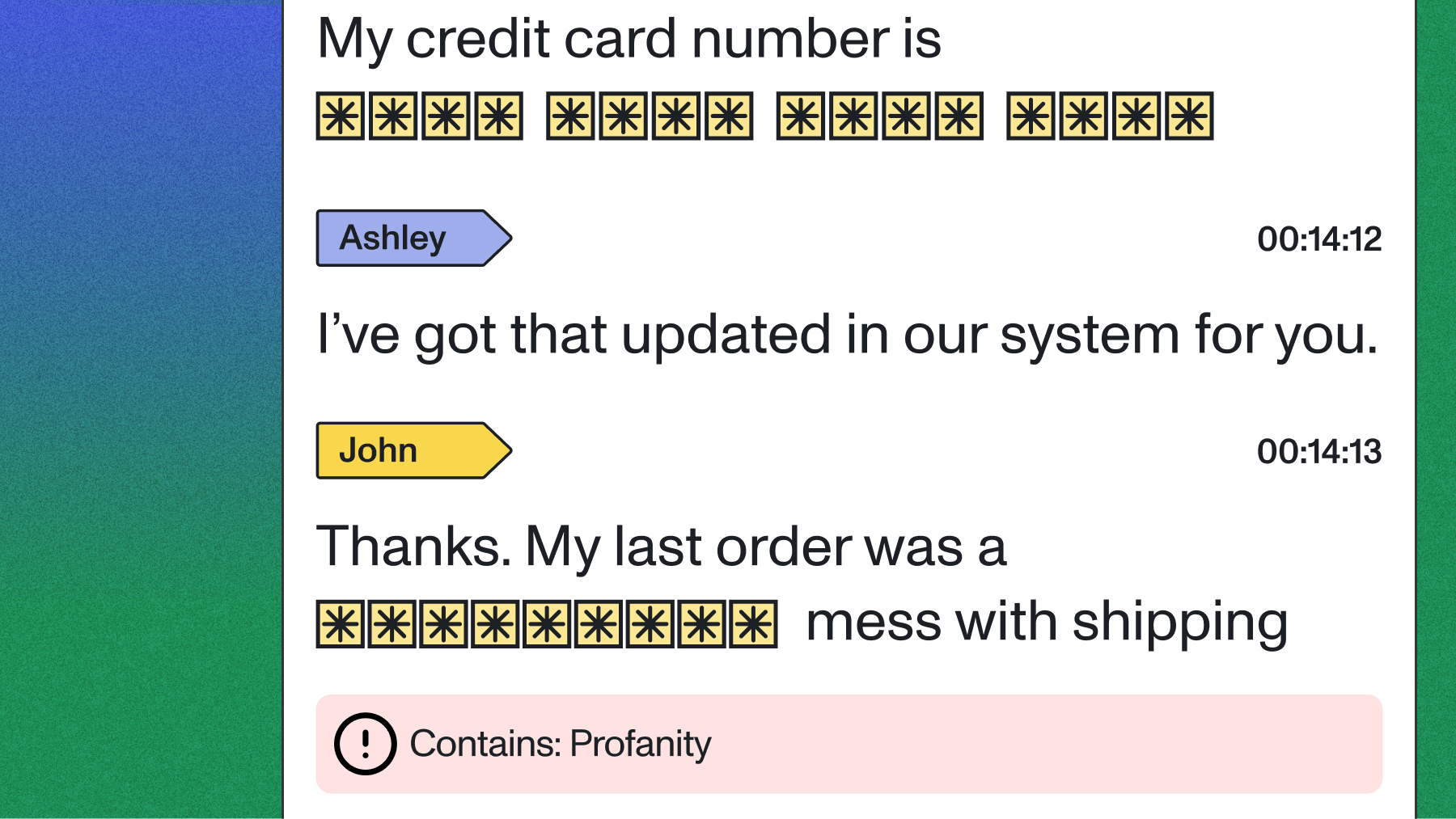
PII redaction for compliance-critical applications
Healthcare, finance, and legal applications require systematic removal of personally identifiable information. Patient names, account numbers, social security digits, and addresses create compliance liability when stored in transcripts or passed to downstream AI models.
PII Redaction removes personal information from both transcript text and audio outputs across over 50 languages. The system detects and redacts:
- Person names and ages
- Phone numbers and email addresses
- Social security numbers and credit card digits
- Physical addresses and locations
- Medical record numbers and patient identifiers
- Bank account and routing numbers
Healthcare platforms use PII Redaction to process clinical conversations while maintaining HIPAA compliance. Financial services applications remove cardholder data before storing call transcripts. Legal tech platforms redact client information from recorded consultations.
Implementation requires a single API parameter. When enabled, PII Redaction processes transcripts during generation, with no post-processing filters or manual review required.
The redaction system supports entity-level filtering through the redact_pii_policies parameter. Rather than removing all PII categories, you can specify which entities require redaction based on your compliance requirements. A healthcare application might redact patient names and medical record numbers while preserving location data needed for demographic analysis.
Automatically remove PII from transcripts
Enable redaction with a single API parameter across 50+ languages. Prevent names, IDs, and account numbers from ever reaching your storage.
Sign up free
Audio redaction: Remove sensitive content from source files
Text redaction protects transcripts, but the original audio files still contain sensitive information. Organizations that store, share, or analyze audio recordings need content removal at the source level.
Audio Redaction generates new audio files with sensitive content replaced by silence. This enables compliant audio storage, safe file sharing with third parties, and protected training data for speech models.
Contact centers use Audio Redaction to share customer calls with quality assurance teams without exposing payment information. Healthcare platforms create anonymized audio datasets for clinical research. Training platforms distribute coaching materials without revealing customer identities.
The system applies the same PII detection used in text redaction, but operates on the audio timeline. When the transcription system identifies a credit card number spoken between 1:34 and 1:42 in a recording, Audio Redaction mutes that specific segment while preserving the surrounding conversation.
Quality guardrails
Quality guardrails filter unwanted content and maintain transcript standards across your voice AI pipeline.
Profanity filtering for quality assurance
Training data quality determines model performance. Profanity in transcripts degrades sentiment analysis accuracy, creates inappropriate training examples, and compromises customer-facing AI applications.
Profanity filtering detects and removes offensive language from transcripts. The filter operates during transcription, blocking profanity before it enters your training pipeline or appears in customer-facing applications.
Contact centers use profanity filtering to generate clean transcripts for quality assurance reviews. Customer support platforms apply filtering before running sentiment analysis. Meeting intelligence applications remove offensive language from searchable transcripts.
The system supports language-specific profanity detection across multiple languages and provides filtering options from light to aggressive based on your application requirements.
Content moderation for safe AI applications
Beyond profanity, voice content may contain hate speech, threats, or other harmful material that requires systematic detection and filtering. Applications processing user-generated content need automated content moderation to prevent policy violations.
Content Moderation analyzes transcripts for sensitive content categories including violence, hate speech, harassment, and adult content. The system generates severity scores for each category, enabling automated filtering or flagging based on your content policies.
Social platforms use Content Moderation to identify policy violations in voice messages. Community applications filter harmful content from voice chat. Moderation teams prioritize review queues based on automated severity scoring.
Detect and filter unsafe speech
Analyze transcripts for violence, hate speech, harassment, and adult content with severity scores. Try it in the Playground, no code required.
Try playground
Efficiency guardrails
Efficiency guardrails reduce unnecessary processing costs by filtering low-value audio before transcription.
Speech threshold: Stop paying for silence
Call recordings often contain extended hold periods, pre-call silence, or post-conversation dead air. Transcribing files with minimal speech content wastes processing resources and inflates costs.
Speech Threshold solves this by transcribing only files that meet your minimum speech percentage requirement. Files that fall below your threshold are rejected before transcription, preventing unnecessary API charges.
A contact center might set a 30% speech threshold to skip recordings that contain mostly hold music. A meeting platform could require 50% speech content to filter out recordings where participants never joined. Healthcare applications might use a 20% threshold to exclude ambient recordings between patient visits.
The system calculates speech percentage during initial audio analysis, then applies your threshold before starting transcription. This prevents processing costs for low-value files while maintaining accuracy for content-rich recordings.
Keyterms prompting: Prioritize accuracy for domain-specific terminology
General-purpose speech recognition models struggle with specialized vocabulary. As one guide on medical AI highlights, a generic model may not know the difference between clinically distinct terms like "Celebrex" and "Celexa." Medical terminology, brand names, technical jargon, and proper nouns frequently appear as transcription errors, creating downstream problems for search, analytics, and AI applications.
Keyterms prompting increases transcription accuracy for domain-specific terms by allowing you to provide a custom vocabulary list. The system prioritizes these terms during transcription, improving recognition accuracy for the vocabulary that matters most to your application.
Healthcare platforms use Keyterms prompting for medical terminology, drug names, and procedure codes. Legal applications boost case names, statute references, and legal terms of art. Contact centers boost product names, competitor brands, and industry-specific vocabulary.
The number of supported terms varies by model. For example, you can provide up to 200 words with our Universal-2 model, or up to 1,000 words with our Universal-3 Pro model. Rather than retraining models or maintaining custom vocabularies, you specify important terms through a simple API parameter.
Customer success stories and industry applications
Organizations across industries leverage voice AI guardrails to transform compliance challenges into competitive advantages. From healthcare providers protecting patient privacy to financial services ensuring PCI compliance, companies are discovering that systematic protection enables faster innovation.
Healthcare: PHI protection and clinical workflow optimization
Healthcare organizations face unique challenges with PHI protection while maintaining clinical efficiency. Companies like Nuvia Dental Implant Center use comprehensive guardrails to process patient conversations at scale while maintaining compliance.
Key outcomes from healthcare implementations:
- 75% reduction in documentation review time
- Zero PHI exposure incidents post-implementation
- Real-time clinical documentation without compliance delays
Clinical teams report significant improvements when guardrails handle PHI protection automatically. Automated redaction enables real-time documentation while ensuring sensitive medical information never enters unprotected systems.
Implementation Timeline:
- Week 1-2: Initial guardrail configuration and testing
- Week 3-4: Production deployment with monitoring
- Week 5+: Full-scale implementation and optimization
Measured outcomes at 90 days:
- 100% HIPAA compliance maintenance
- 65% reduction in documentation overhead
- Zero manual PHI review requirements
Financial services: PCI compliance and call quality improvement
Financial services companies including RightCapital implement multi-layered guardrail strategies like audio redaction, PII redaction, profanity filtering, and more, that deliver measurable results:
This comprehensive approach maintains PCI compliance while enabling full call analysis. Organizations report 60% faster quality assurance cycles with zero compliance incidents.
High-volume contact centers like CallSource process millions of customer interactions monthly. By implementing efficiency guardrails, these organizations optimize their transcription spend while improving data quality for analytics and coaching.
Speech Threshold prevents transcription of non-productive audio, delivering immediate cost savings. Profanity filtering ensures clean transcripts for agent training materials. Content moderation identifies problematic interactions for priority review.
The impact extends beyond cost savings. Contact centers using filtered, high-quality transcripts for agent coaching report improved customer satisfaction scores and reduced escalation rates. When training data quality improves, so does agent performance.
Implementing guardrails in production
Voice AI guardrails integrate directly into your existing AssemblyAI implementation through API parameters. No separate authentication, additional endpoints, or post-processing pipelines required.
Adding PII redaction
Enable PII redaction by including the redact_pii parameter in your transcription request:
import axios from "axios";
import { readFile } from "fs/promises";
const baseUrl = "https://api.assemblyai.com";
const headers = {
authorization: "<YOUR_API_KEY>",
};
const path = "./my-audio.mp3";
const audioData = await readFile(path);
const uploadResponse = await axios.post(`${baseUrl}/v2/upload`,
audioData, {
headers,
});
const uploadUrl = uploadResponse.data.upload_url;
const data = {
audio_url: uploadUrl, // You can also use a URL to an audio or video
file on the web
redact_pii: true,
redact_pii_policies: ["person_name", "organization", "occupation"],
redact_pii_sub: "hash",
};
const url = `${baseUrl}/v2/transcript`;
const response = await axios.post(url, data, { headers: headers });
const transcriptId = response.data.id;
console.log("Transcript ID: ", transcriptId);
const pollingEndpoint = `${baseUrl}/v2/transcript/${transcriptId}`;
while (true) {
const pollingResponse = await axios.get(pollingEndpoint, {
headers: headers,
});
const transcriptionResult = pollingResponse.data;
if (transcriptionResult.status === "completed") {
console.log(transcriptionResult.text);
break;
} else if (transcriptionResult.status === "error") {
throw new Error(`Transcription failed:
${transcriptionResult.error}`);
} else {
await new Promise((resolve) => setTimeout(resolve, 3000));
}
}
The redact_pii_policies parameter accepts an array of entity types to redact. Available policies include person names, phone numbers, email addresses, social security numbers, credit card numbers, dates of birth, medical conditions, and more.
Guardrails apply during transcription without adding separate processing steps. PII redaction and profanity filtering add negligible latency compared to baseline transcription times. Speech threshold actually reduces processing time by rejecting low-value files before transcription starts.
Audio redaction requires additional processing to generate modified audio files, adding approximately 10-15% to total processing time. This overhead is often acceptable given the compliance benefits of source-level content removal.
Building secure voice AI workflows
Implementing guardrails transforms voice AI from a compliance risk into a strategic asset. But protection alone isn't enough—you need a comprehensive workflow that balances security with innovation speed.
Start by mapping your data flow. Identify where sensitive information enters your system, how it moves through your pipeline, and where it gets stored or shared. This visibility reveals which guardrails provide maximum impact.
Layer your protections strategically. Combine safety guardrails for compliance, quality filters for data integrity, and efficiency measures for cost optimization. A financial services application might implement PII Redaction for account numbers, profanity filtering for customer sentiment analysis, and speech threshold to avoid transcribing hold music.
Test incrementally with real-world data. Start with a subset of your audio processing, enable guardrails, and measure the impact on both protection and performance. Organizations often discover unexpected benefits—like improved model accuracy from cleaner training data or faster QA cycles from pre-filtered transcripts.
Build monitoring into your workflow from day one. Track which guardrails trigger most frequently, what types of content get filtered, and how protection affects downstream processes. This data helps you refine thresholds, adjust policies, and demonstrate compliance to stakeholders.
Consider the developer experience. Your engineering team needs clear documentation, predictable behavior, and simple integration paths. When guardrails integrate through standard API parameters rather than complex configuration, adoption accelerates and maintenance overhead decreases.
The most successful implementations treat guardrails as enablers, not obstacles. They unlock use cases that were previously too risky, accelerate deployments that would have stalled in compliance review, and create competitive advantages through superior data quality. Ready to build with built-in protection? Try our API for free.
Frequently asked questions about voice AI guardrails
What's the typical ROI timeline for voice AI guardrails?
Organizations see immediate returns from efficiency guardrails, with most reporting positive ROI within the first billing cycle. Avoiding a single compliance violation typically justifies the entire implementation cost.
Guardrails enhance rather than hinder performance. Features like PII Redaction and profanity filtering apply during transcription without adding separate processing steps, maintaining the same speed you expect from AssemblyAI's models. Speech Threshold actually improves overall processing time by rejecting low-value files before transcription begins.
What compliance frameworks do voice AI guardrails support?
Voice AI guardrails support HIPAA (healthcare PHI protection), PCI-DSS (payment card data), and attorney-client privilege requirements. The flexible policy configuration adapts to specific regulatory needs across industries.
How complex is integration with existing systems?
Integration is remarkably straightforward. Guardrails activate through simple API parameters in your existing AssemblyAI transcription requests. Adding PII Redaction requires one line of code, and enabling Speech Threshold takes a single parameter.