How to choose the best speech-to-text API for voice agents
Choose the right speech-to-text API for voice agents. Learn the latency, accuracy, and integration requirements that actually matter for real conversations.



If you’re building a voice agent, the speech-to-text API underneath it decides whether the conversation feels natural or broken. Latency, accuracy on the tokens you actually care about, and how quickly you can ship all trace back to that one choice. Standard benchmarks won’t tell you the whole story — a builder survey found 76% of respondents treat speech-to-text accuracy as a non-negotiable requirement, alongside latency under load and behavior on the critical tokens their application depends on.
This guide covers what separates real-time speech-to-text from batch, the evaluation criteria that matter for production voice agents, how the leading providers compare, and what implementation looks like from proof of concept to scale. If you want the broader picture first, start with our complete guide to AI voice agents.
What is the best speech-to-text API for voice agents in 2026?
As of 2026, the best speech-to-text API for voice agents is one purpose-built for live conversation: sub-second latency, high accuracy on names, emails, and numbers, and turn detection that knows the difference between a pause and a finished thought. AssemblyAI’s Universal-3.5 Pro Realtime posts a 6.99% word error rate on the public Pipecat voice-agent benchmark and powers the Voice Agent API, which combines speech-to-text, an LLM, and text-to-speech behind one WebSocket at a flat $4.50/hr. Match the API to your latency budget, your critical-token accuracy, and how fast you need to ship.
What is a real-time speech-to-text API?
A real-time speech-to-text API converts spoken audio into text as it’s captured, streaming results back to your application in milliseconds instead of after a recording finishes. Unlike batch APIs that process pre-recorded files, real-time APIs hold a persistent connection — usually a WebSocket — to the audio source, which is what makes live captioning, voice commands, and conversational agents possible.
Real-time vs. batch: the core distinction
There are two primary types of speech-to-text APIs, and a growing third option in between:
- Streaming APIs process live audio as it arrives, essential for voice commands, live captioning, and conversational agents.
- Batch (async) APIs process pre-recorded files and return complete transcripts after processing. Ideal for podcasts, video, and recorded meetings.
- Synchronous APIs sit between the two: one HTTP request in, a full transcript back in ~134 ms for short clips — no WebSocket, no polling. More on where this fits a voice agent below.
Streaming APIs make decisions with limited context, while batch APIs use the entire file for higher accuracy. As this guide explains, batch processing can see the full recording, often producing the highest possible accuracy. Those trade-offs shape pricing and integration complexity.
How streaming transcription works
Real-time speech-to-text relies on a persistent WebSocket connection that streams audio to the API as it’s spoken. The API processes each chunk instantly and returns a stream of transcripts. It sends partial results — words it thinks it heard so far — then finalizes them once it has enough context. For voice agents, the system also handles turn detection: deciding when a user has actually finished speaking rather than just pausing to think.
The key technical considerations for streaming:
- Connection management: keeping WebSocket connections stable and reconnecting gracefully
- Audio format handling: supporting various sample rates, bit depths, and encodings
- Partial vs. final results: knowing when a transcript is tentative versus committed
- Latency optimization: minimizing the gap between speech and an actionable transcript
AssemblyAI’s streaming runs on a single WebSocket endpoint, wss://streaming.assemblyai.com/v3/ws, with the model set to universal-3-5-pro. See the streaming documentation for the full event flow.
What makes real-time speech-to-text different for voice agents
Voice agents need sub-second latency, real-time processing, and turn detection that standard transcription APIs simply don’t have. In batch transcription, speed is a convenience. In a voice agent, it’s the whole experience — human conversation studies put the typical response time in dialogue around 200 ms.
The requirements go beyond speed. Voice agents have to handle the messiness of real conversation: interruptions, corrections, thinking pauses, and overlapping speech. An API built for recorded podcasts won’t hold up in a live exchange.
Key technical differences:
- Real-time processing: immediate transcription without buffering delays, balancing speed against accuracy with limited future context.
- Turn detection: distinguishing a mid-thought pause from a finished turn, so the agent doesn’t cut people off.
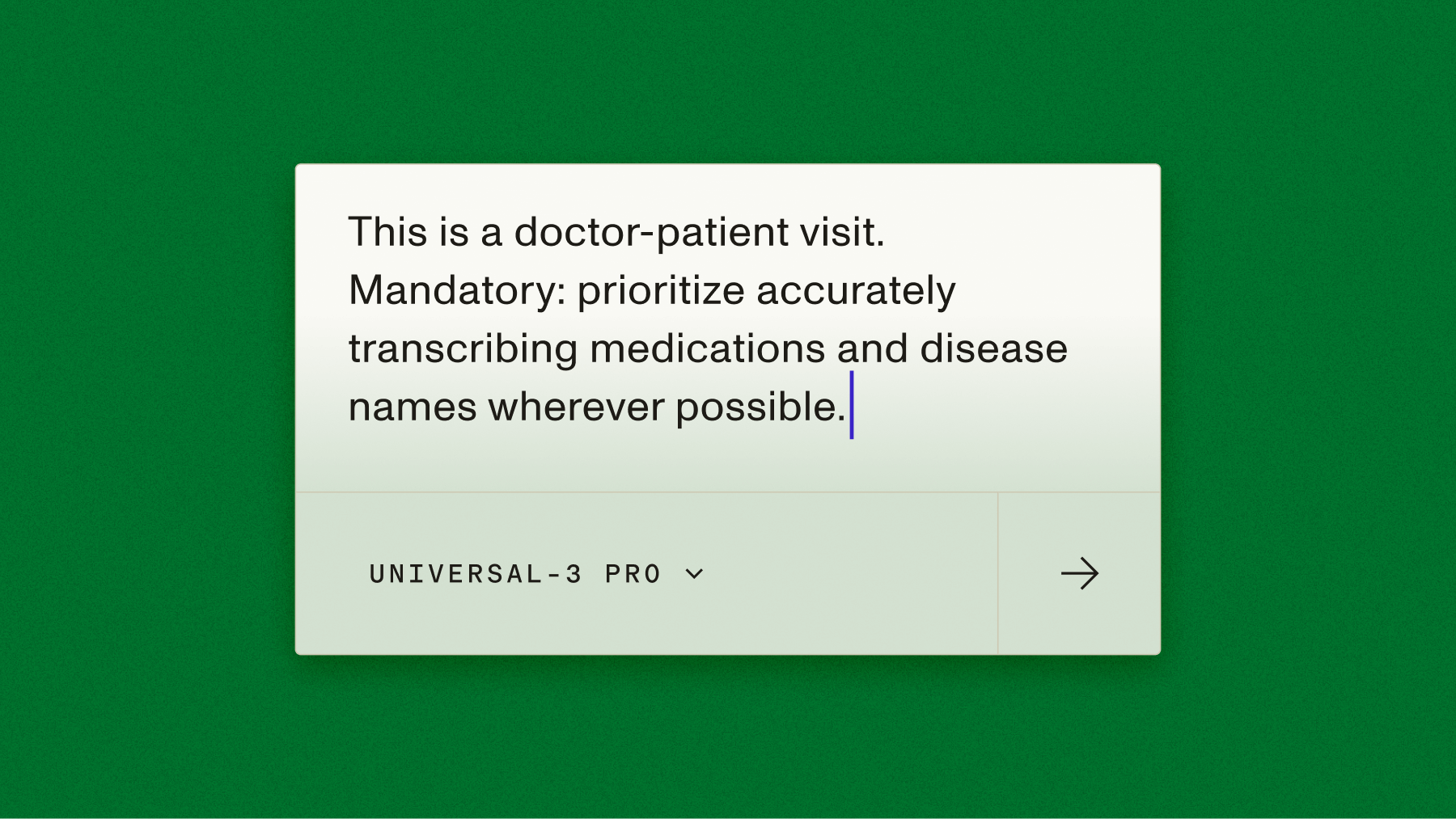
- Critical-token accuracy: perfect capture of business-critical details like emails and phone numbers, where a single error breaks the interaction.
- Stable transcripts: results that don’t churn after delivery and force the agent to backtrack mid-conversation.
Users judge voice agents within seconds — slow responses, misunderstood commands, or awkward interruptions erode trust immediately. In the same builder survey, 95% of respondents said they’ve been frustrated with a voice agent at some point.
Universal-3.5 Pro Realtime: the speech foundation built for voice agents
Universal-3.5 Pro Realtime is AssemblyAI’s current streaming flagship and the speech foundation under the Voice Agent API. It’s tuned specifically for live conversation, with four capabilities that matter for agents:
- agent_context: feed the model the conversation so far and it transcribes the current turn with that context in mind. Across 20,000 voice-agent files, agent_context cut word error rate a further 10.2%.
- Context Carryover: rolling memory across turns, on by default, so accuracy holds as a conversation builds.
- voice_focus: near- and far-field voice isolation that keeps transcription clean when the speaker isn’t right on the mic.
- Turn detection and diarization with revision: speech-aware endpointing plus speaker labels for up to 10 speakers, so the agent knows when to respond and who said what.
You can also tune the latency-accuracy balance with three modes: min_latency, balanced (the default), and max_accuracy.
The latency rule: aim for sub-second responses
Humans respond within about 200 ms in natural conversation — a finding supported by cross-linguistic research that found median response gaps between 0 ms and 300 ms — so anything much slower feels robotic and breaks the flow. Research on conversational dynamics shows faster response times correlate directly with enjoyment and social connection between speakers. This is about end-to-end latency from speech input to an actionable transcript, not just raw processing time.
The red flag is a provider that quotes only “processing time” and never addresses end-to-end latency. The Voice Agent API, built on Universal-3.5 Pro Realtime, targets roughly one second end-to-end for the full speak-listen-reply loop.
Critical-token accuracy: test with your actual data
Generic word error rates tell you little about how a voice agent performs. What matters is accuracy on the specific information your agent has to capture and act on. When your agent mishears john.smith@company.com as johnsmith@company.calm, you’ve lost a customer.
On the public Pipecat open STT benchmark for voice agents, Universal-3.5 Pro Realtime posts a 6.99% word error rate — versus Deepgram Flux at 15.58%, ElevenLabs Scribe v2 at 9.76%, and Google Chirp3 at 9.04%. Its entity error rate is 15.31%, compared with 50.50% for Deepgram, with strong results on the tokens agents live and die by: 3.55% error on phone numbers and 6.28% on place names. See the detailed benchmarks for the full data.
If you want to understand why raw WER can mislead, our take on why word error rate is broken and how to evaluate speech recognition models both go deeper.
Turn detection: move beyond basic silence detection
Basic voice activity detection treats every pause like the end of a turn. That’s a problem — conversational analysis found nearly a quarter of speech segments are self-continuations after a pause, not the end of a turn. Picture someone saying “My email is… john.smith@company.com” with a natural hesitation, and the agent jumping in with “How can I help you?” before they finish.
Look for turn detection that combines configurable silence thresholds with model confidence rather than firing on any pause. Universal-3.5 Pro Realtime’s speech-aware turn detection is on by default and needs no tuning to get started. Test it with realistic speech: have someone give information with hesitation, interruptions, and clarifications, and watch whether the agent waits.
Common use cases and applications
Real-time speech-to-text powers a widening range of voice products, from AI meeting assistants to clinical documentation, across a market projected to reach nearly $50 billion by 2029.
Voice agents and conversational AI
IVR systems and AI assistants rely on speech-to-text as their ears. The API has to process speech in real time, capture commands and questions accurately, and hand that understanding to downstream systems for a response.
Critical voice-agent requirements:
- Sub-second latency for natural conversational flow
- High accuracy on short utterances and commands
- Context awareness across the length of an interaction
- Interruption handling for natural speech patterns and corrections
The Voice Agent API handles the full voice pipeline through a single WebSocket — one connection replaces separate STT, LLM, and TTS providers. Built on Universal-3.5 Pro Realtime, it delivers accurate transcription with turn detection and interruption handling built in, so you focus on product logic instead of voice infrastructure.
Launch voice agents with one WebSocket. Replace separate STT, LLM, and TTS with a single connection, built on Universal-3.5 Pro Realtime for accurate transcripts and turn detection. Talk to a live agent →
Contact center intelligence
Contact centers use speech-to-text to turn every call into a source for quality assurance, agent coaching, and sentiment analysis. Real-time insights help reduce handling time and lift satisfaction, with some organizations saving 25 to 30 percent on contact center costs through better agent performance.
Contact center intelligence needs high accuracy on phone-quality audio, speaker diarization to separate agent and customer, domain-specific terminology handling, and real-time transcription for live agent assist.
AI meeting assistants
Remote work created steady demand for automated meeting documentation — transcribing virtual meetings, extracting action items, and generating summaries. Meeting transcription needs excellent speaker diarization, handling of overlapping speech, and the flexibility to process varied audio quality across participants. Integration with video conferencing and calendar systems is what makes the workflow seamless.
Healthcare documentation
Clinicians spend hours on documentation, and Voice AI is projected to return substantial savings to the healthcare economy by automating it. Healthcare applications need specialized medical vocabulary, extreme accuracy on drug names and dosages, and strict security and compliance.
AssemblyAI enables covered entities and their business associates subject to HIPAA to use the AssemblyAI services to process protected health information (PHI). AssemblyAI is considered a business associate under HIPAA, and we offer a Business Associate Addendum (BAA) that is required under HIPAA to ensure that AssemblyAI appropriately safeguards PHI. Accuracy is non-negotiable here — a system has to reliably distinguish similar-sounding drug names like “Celebrex” and “Celexa.”
Media transcription and captioning
Media platforms use speech-to-text for accessibility compliance and content discovery. Accurate transcripts improve SEO and open content to hearing-impaired viewers. These applications demand multi-speaker support, background-music handling, and time-coded transcripts that sync with video playback.
How to evaluate accuracy and performance
Choosing an API on marketing claims alone leads to disappointment. Real evaluation means understanding the metrics and testing with your own use case.
Understanding word error rate (WER)
Word error rate is the industry-standard accuracy metric: the percentage of words that need correcting to match a reference transcript, counting substitutions, deletions, and insertions. A 5% WER means 95 of 100 words are correct. Context matters — 5% errors on medical terminology carries different weight than 5% on casual conversation.
Critical-token accuracy
WER doesn’t tell the whole story. What matters more is accuracy on the information critical to your business — product names, customer IDs, industry terminology. Test candidate APIs with audio containing your actual vocabulary; an error on an email address or account number is a business problem, not a statistic.
Real-world testing methodology
The only reliable way to evaluate APIs is with your own audio:
- Gather representative samples: collect 10–20 examples of real audio, including edge cases and challenging conditions.
- Create reference transcripts: transcribe them by hand, paying attention to critical business terms.
- Test multiple APIs: run your samples through your top 2–3 choices using their free tiers.
- Measure what matters: calculate both overall WER and accuracy on your critical tokens.
- Evaluate the full experience: weigh integration complexity, documentation, and support alongside accuracy.
Benchmark scores on standard datasets don’t predict performance on your specific use case. An API tuned for podcasts might struggle with customer-service calls despite impressive numbers.
Top real-time speech-to-text API providers compared
The landscape includes providers with different strengths, architectures, and ideal use cases. As of 2026, here’s how they line up for voice agents.
For a wider look at streaming models, see our roundup of the top APIs and models for real-time speech recognition.
Integration and implementation considerations
Technical implementation decides project success more than raw model quality. Three areas deserve careful evaluation: orchestration compatibility, API design, and scaling.
Orchestration framework compatibility
Custom WebSocket implementations cost more developer time than most teams expect, which is why industry data shows a hybrid approach — vendor infrastructure plus custom logic — is the most popular build strategy. The same report found 45% of teams cite integration difficulty as a top challenge. Connection setup is easy; handling drops, managing state, and building proper error recovery gets complex fast.
Pre-built integrations cut development from weeks to days. AssemblyAI ships step-by-step docs and battle-tested code for major orchestration frameworks like LiveKit and Pipecat. If you’re standardizing on a builder like Vapi or LiveKit, pick a speech-to-text provider with native support so you’re not maintaining glue code.
API design quality: evaluate the developer experience
Developer experience directly shapes your timeline and long-term maintenance. Green flags for good API design:
- Comprehensive error handling with clear messages
- Consistent response formats across endpoints
- Robust SDKs in multiple languages
- Clear connection-state management for streaming
- Graceful degradation when network conditions change
Red flags:
- Sparse or outdated documentation
- Limited SDK support that forces raw API calls
- Unclear pricing for production loads
- Complex authentication
- Inconsistent behavior across endpoints
Can you establish a connection, stream audio, and process results with minimal code? The answer tells you whether you’re dealing with a developer-focused API or an afterthought.
A voice agent in practice
The best real-time APIs act as invisible infrastructure. With the Voice Agent API, you create an agent once with a single REST call, then connect to it over one WebSocket. Here’s the create step:
curl -X POST https://agents.assemblyai.com/v1/agents \
-H "Authorization: $ASSEMBLYAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"name": "Support Assistant",
"system_prompt": "You are a friendly customer support agent. Keep
replies short and natural.",
"greeting": "Hi, how can I help today?",
"voice": { "voice_id": "ivy" }
}'
The response returns an id — your agent ID. From a browser or server you then open a WebSocket to wss://agents.assemblyai.com/v1/ws and send a session.update message referencing that agent_id to start the conversation. Because the API is built on Universal-3.5 Pro Realtime, you get highly accurate, low-latency transcription with turn detection and interruption handling out of the box. System prompt, voice, tools, and turn-detection settings can all be updated mid-conversation without reconnecting, and most developers get a working agent running the same afternoon they start. See the Voice Agent API quickstart and our guide on how to build with the Voice Agent API for the full walkthrough.
Where a synchronous API fits the turn loop
Not every voice-agent architecture runs transcription over a live WebSocket. If you already handle turn detection yourself — with a VAD or your orchestrator — you can submit each completed utterance to a synchronous endpoint and get a transcript back in a single HTTP request. AssemblyAI’s Sync API returns a Universal-3.5 Pro transcript in about 134 ms at p50, with a short-form WER of 1.59%, at $0.45/hr — no WebSocket to manage, no polling.
curl -X POST https://sync.assemblyai.com/transcribe \
-H 'Authorization: <YOUR_API_KEY>' \
-H 'X-AAI-Model: u3-sync-pro' \
-F 'audio=@turn.wav;type=audio/wav'It’s a clean fit for push-to-talk interfaces and post-turn-detection transcription where you’re submitting completed utterances rather than a continuous stream. The Sync API accepts clips from 80 ms up to 120 seconds and can take prior turns as conversation_context to boost accuracy. See the Sync API quickstart for details. Between Realtime (WebSocket), Sync (HTTP, short clips), and Async (poll, long files), you can match the transport to each part of your pipeline.
Scaling considerations
Production exposes limits that don’t show up in prototyping. Verify actual concurrent connection limits, not marketing claims — some providers throttle aggressively past the free tier. Geographic distribution matters too: an agent with 150 ms latency in San Francisco but 800 ms in Singapore will fail international expansion. And favor predictable pricing — AssemblyAI’s per-hour, per-second billing with unlimited concurrency avoids the surprises of complex per-minute models with hidden fees. For implementation best practices, see the guide to getting started with streaming transcription.
Pricing models and cost considerations
The sticker price is only part of the total cost. Speech-to-text APIs typically use per-minute or per-hour pricing, per-request pricing, tiered volume pricing, or subscriptions. Most charge extra for advanced features — diarization, custom vocabulary, entity detection, and streaming often add fees that stack up at scale.
The Voice Agent API takes a different approach: $4.50/hr flat covers speech understanding, LLM reasoning, and voice generation — no token math, no separate input/output charges, one bill for the full pipeline. See pricing for the full breakdown.
Beyond direct API costs, weigh total cost of ownership: integration and development time (often more than usage fees early on), maintenance overhead, infrastructure requirements, and the cost of inaccuracy. As the builder survey shows, accuracy failures correlate directly with user frustration — the downstream cost of a wrong transcript usually dwarfs the API itself.
Getting started with real-time speech-to-text
Moving from evaluation to production works best with structure.
Start with a focused proof of concept
Skip the generic demos. Build a proof of concept on your actual use case: real audio from your domain, your latency requirements, your critical vocabulary, your accuracy metrics, and the complete integration experience. Start small — one conversation flow for a voice agent, one team’s calls for meeting transcription.
Prioritize based on constraints
Every project has constraints that should drive the choice:
- Timeline: if you launch in weeks, favor the option with the best existing integrations and support.
- Budget: count development time, not just API pricing — better docs can make a pricier API cheaper overall.
- Technical: your existing stack narrows the field.
- Compliance: healthcare and financial services requirements immediately shorten the list.
Our step-by-step voice agent tutorials and the Voice AI stack for building agents can get you moving quickly.
Plan for monitoring and optimization
Deployment is the start, not the finish. Track accuracy (WER and critical-token accuracy over time), end-to-end latency, error rates, user feedback, and cost per user. Build feedback loops: when users correct a transcript, capture the correction to find systematic errors.
The gap between a voice agent that feels natural and one that feels broken comes down to the API underneath it. Talk to a live agent and hear how purpose-built models change the experience — or start building free.
Frequently asked questions
How does real-time speech-to-text accuracy compare to batch transcription?
Streaming APIs process audio with limited future context, which can slightly reduce accuracy versus batch. Modern models close most of that gap — Universal-3.5 Pro Realtime posts 6.99% WER on the Pipecat voice-agent benchmark while keeping the full conversation loop near one second end-to-end.
What latency should I target for production voice applications?
Aim for sub-second, end-to-end. Human conversation studies put typical response times around 200 ms, so a full loop meaningfully slower than a second feels robotic and leads users to talk over the agent. Measure speech-in to actionable-transcript, not just model processing time.
How does billing work for voice-agent speech-to-text at scale?
Most providers charge per minute or per hour, often with separate fees for features like diarization. The Voice Agent API uses a flat $4.50/hr rate that covers speech understanding, LLM reasoning, and voice generation — no token math, no separate invoices. Universal-3.5 Pro Realtime on its own is $0.45/hr base.
When should I use a synchronous API instead of streaming?
Use a synchronous API when you already handle turn detection and want to submit completed utterances — push-to-talk, voice messages, or post-turn-detection transcription. AssemblyAI’s Sync API returns a transcript in about 134 ms for clips up to 120 seconds over one HTTP request. Use streaming when you need continuous, live transcription of an open microphone.
What’s the fastest way to integrate speech-to-text into an existing voice stack?
Use a provider with a single WebSocket API and pre-built integrations for orchestration frameworks like LiveKit, Pipecat, or Vapi. That eliminates stitching together separate STT, LLM, and TTS providers and can cut development from weeks to an afternoon. See our guide on using the Voice Agent API alongside an existing voice stack.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts