Florence-2: How it works and how to use it
Microsoft's Florence-2 is a foundational image model that can perform almost every common task in computer vision. Learn how Florence-2 works and how to use it in this guide.



LLMs have dominated the past several years and seen rapid integration across a litany of industries. The primary cause for this sudden appearance of LLMs to the general public and subsequent adoption by wider industry was the discovery that scaling LLMs renders them generally capable agents.
Additionally, besides being generally performant on many tasks, LLMs are also "foundational models". This means that they can be used as the bedrock for more complicated processing pipelines that cannot rely on "in-context learning", whether this be explicit finetuning or architecture adaptation for specialized tasks.
What happened to language with LLMs is now happening to vision with Large Vision Models (LVMs). The field of Computer Vision has lagged in developing large foundational models akin to LLMs due to difficulties that are intrinsic to developing such models. Microsoft's new LVM Florence-2 represents a significant step towards this goal of a unified vision model, demonstrating impressive results with a compact, parameter-efficient model.
Florence-2 is capable of performing a wide variety of image-language tasks, being able to produce image-level, region-level, and pixel-level outputs. Here is a compilation of the tasks that Florence-2 can perform out-of-the-box after pre-training:

In this article, we'll look at an overview of what Florence-2 can do, how it works, and how to use it.
What can Florence-2 do?
Several years ago in Natural Language Processing, bespoke models were trained and deployed for tasks like summarization, question answering, and more. LLMs constituted a seminal moment via the convergence of specialized architectures into a single, general-purpose model with a simple training paradigm
Florence-2 follows in the footsteps of LLMs, leveraging a unified architecture and simple training paradigm paired with a vast amount of data to become competent at many different tasks. Florence-2 can be considered a sort of GPT-2.5 - being able to perform tasks like:
- Captioning
- Optical Character Recognition
- Object Detection
- Region Detection
- Region Segmentation
- Vocabulary Segmentation
and more with one set of weights and no architectural modifications by providing special task tokens to the model at inference. This lies in contrast to older LVMs which are great at transfer learning but are not so good at performing tasks in isolation with simple instructions.
Building such a model is a complicated task that presents a number of unique challenges - let's take a look at one of the central challenges now.
Challenges
A central challenge of developing an LVM is instilling in it an ability to work at different levels of semantic and spatial resolution - what the authors refer to as "semantic granularity" and "spatial hierarchy". A general vision model requires an ability to complete tasks at any combination of levels across these two axes:

Florence-2 addresses this challenge by following in the footsteps of LLMs. That is, Florence-2 follows the "playbook" of LLM research, building on top of other recent vision research, to learn general representations that are useful for many tasks.
Following this playbook requires three things:
- A singular network architecture
- A large, sufficiently diverse dataset
- A unified pre-training framework
Let's take a look at each of these components in turn.
How does Florence-2 work?
Architecture
Florence-2 is designed in a simple way - to take in textual prompts (in addition to the image being processed), and generate textual results. Unifying the way in which diverse types of information - masked contours, locations, etc. - are input to the model permits (i) a unified training procedure and (ii) easy extension to other tasks without the need for architectural modifications, which are the two hallmarks of a foundational model.
In particular, Florence-2 adopts a classic seq2seq transformer architecture into which both visual, textual, and location embeddings are fed. The input image and prompt are mapped into embeddings which are then simply concatenated and passed into the standard Transformer encoder-decoder. Check out our video on word embeddings to learn more about how embedding models work.

Additional information
Language and region token embeddings are generated with an extended language tokenizer/word embedding layer, where the tokenizer's vocabulary is expanded to include location tokens (in order to accommodate region information). Input images are encoded with a DaViT encoder into a series of visual tokens, and then projected to the dimensionality of the language embeddings. The visual and language embeddings are then concatenated and fed into a standard transformer encoder-decoder.
Florence-2's architecture is essentially a standard Transformer encoder-decoder architecture - it is not particularly special and in fact it shouldn't be. The critical lesson learned from LLMs is that architectural minutiae are not particularly important, and instead simply scaling a model's size and training data can yield significant performance heights.
In many ways, it is really the dataset that is most important.
Dataset - FLD-5B
To be a foundational model, Florence-2 needs to be trained to have image-level understanding (for e.g. captioning), spatial understanding (for e.g. region detection), and visual-semantic alignment (for e.g. phrase grounding). Imbuing the model with understanding at these various levels demands a large, diverse dataset.
To this end, the authors curate FLD-5B - an open-source dataset of 5.4 billion annotations on 126 million images. This one-to-many relationship between images and annotations allows them to "get more juice" out of their collected images, and additionally potentially allows for learning more powerful representations by processing the same images in distinct ways.
FLD-5B contains text annotations, text-region annotations, and text-phrase-region annotations (linking regions to phrases within captions that provide global context about the image) at various degrees of granularity for the images in the dataset:

Compiling such a large, intricate dataset is a complicated task. Unlike LLMs, for which you can scrape basically any available, human-written textual data online, image-text pairs are harder to come by, and "naturally-occurring" annotations for tasks like object detection are virtually nonexistent.
To circumvent this issue, the authors use specialist AI models to generate labels for training. For example, they use specialized region-detection models and APIs to generate region annotations for images collected in the dataset.
This process of using AI models to generate labels (called pseudolabels) isn't uncommon. In fact, we've done this at AssemblyAI as first described in our blog on Conformer-1, a previous generation of our Speech-to-Text model. The authors use a variety of specialized models and a multi-step label generation "engine" to generate useful annotations across a wide range of spatial and semantic granularities:

For any images sourced from a pre-existing dataset (like ImageNet), the human-generated annotations are merged with the synthetic ones, and then this entire dataset is used to train Florence-2.
They then use Florence-2 to generate new pseudolabels (measuring an improvement over many of the specialized models), filter these pseudolabels for quality, and then mix them into the set of original annotations and iteratively repeat this process. That is, Florence-2 itself is used as a specialist model to compile FLD-5B.
A final note of interest: the original pseudolablels are the result of many models working together to reach a consensus. Such techniques are not uncommon, and AssemblyAI also utilized this technique when training Conformer-2, the predecessor to our new Universal-1 Speech-to-Text model.
Training
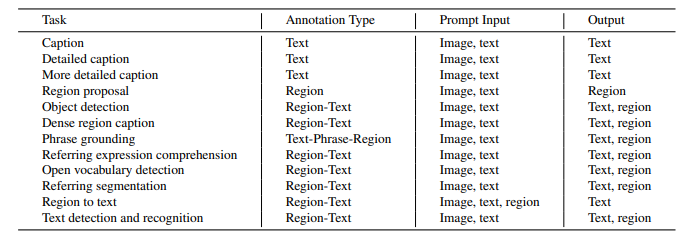
Florence-2's training is standard language modeling with cross-entropy loss - here is a table of the annotation types, prompt inputs, and outputs for the various tasks:
Locations are specified as the special tokens <loc_x><loc_y>, where x and y are integers in the range [0, 1000]. These integers indicate coordinates on the image with a 0.1% resolution in either direction. That is, the string <loc_250><loc_500> means the point on the image that is 25% of the way across the horizontal axis, and 50% of the way down the vertical axis (<loc_0><loc_0> is the top left corner of the image).
By extending the tokenizer's vocab to include location tokens, Florence-2 can process region-specific info in a unified learning format. This eliminates the need for task-specific heads for different tasks and allows for a more data-centric approach
Now that we understand how Florence-2 works, let's take a look at how to use it.
How to use Florence-2
The easiest way to get started with Florence-2 is to check out the Colab associated with this article.
It is an adapted version of the original Florence-2 inference Colab where the code sections have been re-organized with more context and useful information to help you understand how to use this model. These sections use helper functions defined in utils.py, which you can check out on GitHub.
Let's look at how to run each task now:
Captioning
Florence-2 supports 3 types of captioning tasks at different levels of detail - we run each here and print the results:
Here is the output
Optical Character Recognition (OCR)
Florence-2 can perform whole-image OCR, optionally returning bounding boxes. To perform OCR only, you can use the following code:
Here is the output:
To run OCR with regions returned, you can use this code:
Here is the output:

Object detection
Florence-2 can detect objects, optionally returning either categorical or descriptive labels. Here's how to run object detection with Florence-2:
And here is a gif of the results (the resizing of the last frame is just due to the GIF’s processing):

Segmentation
To segment an object in a particular region, supply Florence-2 with a bounding box in the format "<loc_x1><loc_y1><loc_x2><loc_y2>", where the first point is the top left corner of the bounding box and the second is the bottom right.
Here's how to perform segmentation with Florence-2:
Here is the result, where both the input bounding box and output segment are drawn:

Region description
Florence-2 can also perform region description, which is effectively object detection or captioning for a subset of the image. Region description maps a region to either a category or descriptive annotation - here's a script to perform it:
Here's a GIF of the results:

Phrase grounding
Given a textual input, Florence-2 can perform object detection conditioned on a textual input. The model performs object detection for the objects described in the text prompt, linking each identified region to an associated phrase in the textual input. Here we show how Florence-2 detects and labels two regions that correspond to the two salient phrases in the provided input:
Here's the output:

Vocabulary detection
Florence-2 can also identify an object given a single phrase. Vocabulary detection is similar to phrase grounding except that it is one-to-one instead of one-to-many, and except that vocabulary detection can also detect text in the image. Here's how to perform vocabulary detection with Florence-2:
Here's the output:

Here is an example of how vocabulary detection can be used to find text that is present in the image:
Here's the output:

Vocabulary Segmentation
Florence-2 can also perform vocabulary segmentation, which is like vocabulary detection except for the fact that it identifies segments rather than regions:
Here's the result:

Note that vocabulary segmentation does not work with text as vocabulary detection does.
Cascaded Tasks with Florence-2
We can chain multiple tasks together to develop more complicated processing pipelines using only Florence-2. For example, here we supply nothing but an image. From this image, we derive a description using captioning, and then identify salient regions with phrase grounding:

From there, we can go a step further and use region segmentation to identify the segments in these regions:

So, we have taken nothing but an image, generated a caption for it, identified the salient objects in the image, and then identified these objects' outlines.
What's next?
Florence-2 is a big step forward - it can perform a variety of tasks, demonstrates strong zero-shot performance, attains state-of-the-art results on several tasks once finetuned, and is a compact model for its level of performance. Additionally, the contribution of FLD-5B to the open source community is significant and will aid in future research.
Additional work needs to be done to train an LVM that can perform novel tasks via in-context learning as LLMs can. We'll be having another article coming out with a deeper dive into the development of LVMs in the coming weeks, so subscribe to our newsletter to stay in the loop when we release new content.
Alternatively, check out some of our other resources on AI progress, like:
- How Reinforcement Learning from AI Feedback works
- RLHF vs RLAIF for language model alignment
- The Full Story of Large Language Models and RLHF
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.