
Top 8 speaker diarization libraries and APIs in 2026
In this blog post, we'll look at how speaker diarization works, why it's useful, some of its current limitations, and the top eight speaker diarization libraries and APIs for product teams and developers to use.



In its simplest form, speaker diarization answers the question: who spoke when?
In the field of Automatic Speech Recognition (ASR), speaker diarization refers to (A) the number of speakers that can be automatically detected in an audio file, and (B) the words that can be assigned to the correct speaker in that file.
Today, many modern speech-to-text APIs and speaker diarization libraries apply advanced AI models to perform tasks (A) and (B) with near human-level accuracy, significantly increasing the utility of speaker diarization. Recent advances have dramatically improved performance in challenging real-world conditions—AssemblyAI's updated speaker embedding model delivers a documented 30% improvement in noisy environments—and, just as importantly, diarization now runs in real time on live audio, not just on pre-recorded files.
In this post, we'll look at how speaker diarization works, why it's useful, how to evaluate it, and the top eight speaker diarization libraries and APIs for product teams and developers in 2026—including which ones support real-time streaming.
What is speaker diarization?
Speaker diarization answers the question: "Who spoke when?" It involves segmenting and labeling an audio stream by speaker, allowing for a clearer understanding of who is speaking at any given time. This process is essential for automatic speech recognition (ASR), meeting transcription, and call center analytics, transforming raw audio into structured, actionable insights.
Speaker diarization performs two key functions:
- Speaker detection: Identifying the number of distinct speakers in an audio file.
- Speaker attribution: Assigning segments of speech to the correct speaker.
The result is a transcript where each segment of speech is tagged with a speaker label (e.g., "Speaker A," "Speaker B"), making it easy to distinguish between different voices. This improves the readability of transcripts and increases the accuracy of analyses that depend on understanding who said what.
It's worth noting early that diarization is rarely the end goal. For teams building conversation intelligence, voice agents, and meeting products, diarization is consistently one of the first technical requirements they evaluate—because every downstream step (per-speaker sentiment, speaker-attributed summaries, agent-vs-customer analytics) breaks if the speaker labels are wrong.
How does speaker diarization work?
The fundamental task of speaker diarization is to apply speaker labels (i.e., "Speaker A," "Speaker B," etc.) to each utterance in the transcription text of an audio/video file.
Accurate speaker diarization requires many steps. The first step is to break the audio file into a set of "utterances." What constitutes an utterance? Generally, utterances are at least a half second to 10 seconds of speech. To illustrate this, let's look at the below examples:
Utterance 1:
Hello my name is Bob.Utterance 2:
I like cats and live in New York City.AI models require sufficient audio data for accurate speaker identification, similar to human recognition patterns. Audio segmentation uses silence detection and punctuation markers to create utterances between 0.5–10 seconds.
Once an audio file is broken into utterances, those utterances get sent through a deep learning model that has been trained to produce "embeddings" that are highly representative of a speaker's characteristics. An embedding is a deep learning model's low-dimensional representation of an input. For example, the image below shows what the embedding of a word looks like:
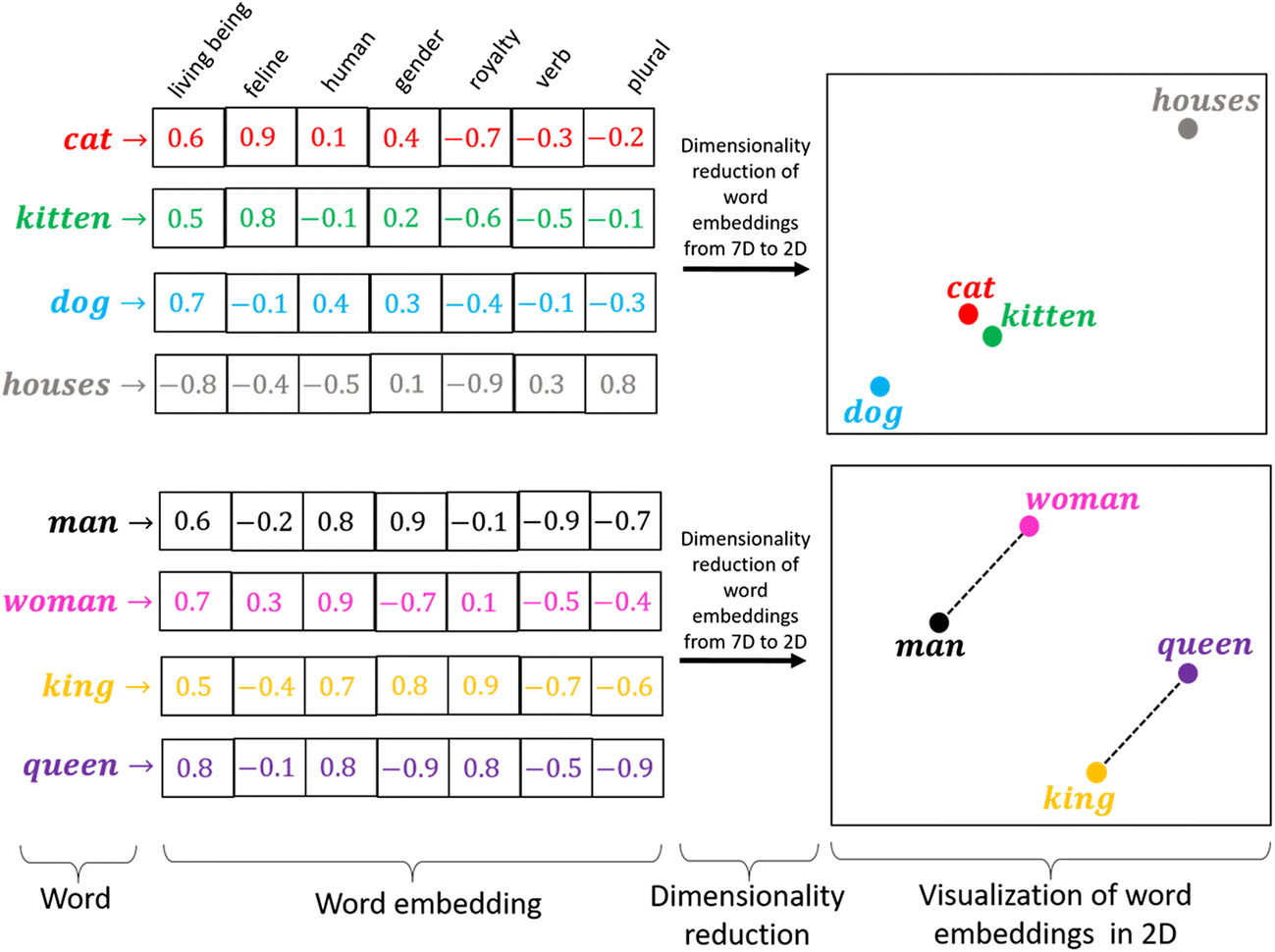
We perform a similar process to convert not words, but segments of audio, into embeddings as well.
Next, we need to determine how many speakers are present in the audio file—this is a key feature of a modern speaker diarization model. Legacy speaker diarization systems required knowing how many speakers were in an audio/video file ahead of time, but a major benefit of modern speaker diarization models is that they can accurately predict this number.
Our first goal here is to overestimate the number of speakers. Using a clustering method, you want to determine the greatest number of speakers that could reasonably be heard in the audio. Why overestimate? It's much easier to combine the utterances of one speaker that has been incorrectly identified as two than it is to disentangle the utterances of two speakers which have incorrectly been combined into one.
After this initial step, we go back and combine speakers, or disentangle speakers, as needed to get an accurate number.
Finally, speaker diarization models take the utterance embeddings (produced above), and cluster them into as many clusters as there are speakers. For example, if a speaker diarization model predicts there are four speakers in an audio file, the embeddings will be forced into four groups based on the "similarity" of the embeddings.
For example, in the below image, let's assume each dot is an utterance. The utterances get clustered together based on their similarity—with the idea being that each cluster corresponds to the utterances of a unique speaker.
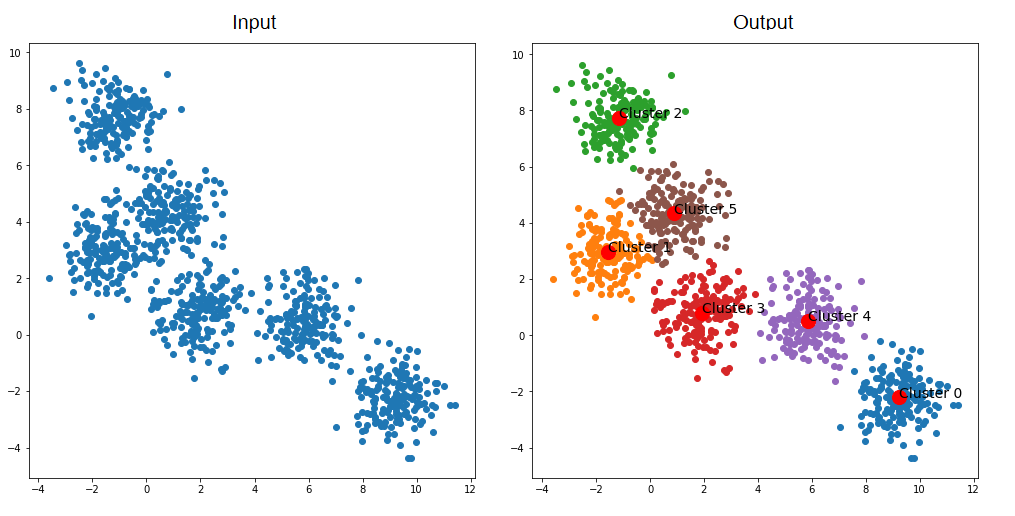
There are many ways to determine similarity of embeddings, and this is a core component of accurately predicting speaker labels. End-to-end approaches that eliminate traditional pipeline stages are on the rise, treating diarization as a unified problem—these newer architectures can better handle overlapping speech and brief utterances that previously challenged traditional systems.
Today's speaker diarization models can determine multiple speakers in the same audio/video file with high accuracy. It's important to note that speaker diarization differs from speaker recognition—diarization identifies different speakers without knowing their identities, while recognition matches voices to known individuals.
Why is speaker diarization useful?
Speaker diarization transforms unstructured transcripts into labeled conversations. Without speaker labels, readers must manually assign utterances to speakers, creating cognitive overhead and processing delays.
For example, let's look at the before and after transcripts below with and without speaker diarization:
Without speaker diarization:
Hello, thanks for calling. How can I help you today? Hi, I'm calling because I noticed an unexpected charge
on my account from last Tuesday. I'm sorry to hear that. Let me pull up your account. Can you give me your
account number? Sure, it's 7-8-4-5-2-1. Got it, I see the charge you're referring to. It looks like that was
a subscription renewal. Oh, I thought I cancelled that last month. Let me check the cancellation history. It
looks like the cancellation was submitted but didn't process before the billing cycle. I can issue a refund
for you right away. That would be great, thank you so much. You're welcome, the refund should appear within
3 to 5 business days. Is there anything else I can help with? No, that's everything. Thanks again. Have a
great day. You too, goodbye.With speaker diarization:
Speaker A: Hello, thanks for calling. How can I help you today?
Speaker B: Hi, I'm calling because I noticed an unexpected charge on my account from last Tuesday.
Speaker A: I'm sorry to hear that. Let me pull up your account. Can you give me your account number?
Speaker B: Sure, it's 7-8-4-5-2-1.
Speaker A: Got it, I see the charge you're referring to. It looks like that was a subscription renewal.
Speaker B: Oh, I thought I cancelled that last month.Speaker A: Let me check the cancellation history. It
looks like the cancellation was submitted but didn't process before the billing cycle. I can issue a refund
for you right away.
Speaker B: That would be great, thank you so much.Speaker A: You're welcome, the refund should appear within
3 to 5 business days. Is there anything else I can help with?
Speaker B: No, that's everything. Thanks again. Have a great day.
Speaker A: You too, goodbye.See how much easier the transcription is to read with speaker diarization?
Speaker diarization is also a powerful analytics tool. By identifying and labeling speakers, product teams and developers can analyze each speaker's behaviors, identify patterns and trends, make predictions, and more. For example:
- A call center might analyze agent and customer calls, requests, or complaints to identify trends that improve communication.
- A podcast service might use speaker labels to identify the host and guest, making transcriptions more readable for end users.
- A telemedicine platform might identify doctor and patient to create an accurate transcript, attach a readable transcript to patient files, or input the transcript into an EHR system.
Enterprises are already leveraging these capabilities to transform their operations and build powerful transcription and analysis tools. Additional practical applications include legal compliance (accurate speaker attribution in proceedings), meeting records (tracking contributions and action items), educational use (helping students follow lectures), and research (analyzing conversational dynamics).
Top 8 speaker diarization libraries and APIs
Choosing the right speaker diarization solution depends on your specific needs: accuracy requirements, whether you need real-time (streaming) or batch processing, integration complexity, and whether you want a managed API or open-source flexibility.
The single most important axis many teams overlook is real-time support. Batch diarization waits for the complete recording; streaming diarization assigns labels live, as people talk—which is what voice agents, live coaching, and real-time captioning require. Here's how the leading solutions compare:
Let's examine each solution in detail.
1. AssemblyAI
AssemblyAI is a Voice AI infrastructure platform that offers highly accurate speech-to-text through its latest models, including Universal-3 Pro. Alongside transcription, it provides a suite of Speech Understanding models for tasks like sentiment analysis, topic detection, summarization, and entity detection.
AssemblyAI's speaker diarization has seen dramatic improvements, achieving a 10.1% improvement in Diarization Error Rate (DER) and a 13.2% improvement in cpWER. The latest models deliver 30% better performance in noisy environments and handle speaker segments as short as 250ms with 43% improved accuracy compared to previous versions. For even greater precision, AssemblyAI also offers Speaker Identification, which replaces generic labels like "Speaker A" with actual names or roles (e.g., "John Smith" or "Customer") inferred from the conversation.
Crucially, AssemblyAI supports diarization in both async and real-time streaming. Streaming diarization runs on the same WebSocket connection you already use for transcription—just add speaker_labels: true—and works with the Universal-3 Pro Streaming model and the multilingual streaming models. That makes it a fit for voice agents and live call intelligence, not just post-call analysis.
Key strengths:
- Industry-leading 2.9% speaker count error rate (based on internal benchmarking)
- Word-level accuracy reported as cpWER, not just DER (more on why that matters below)
- Real-time streaming diarization (public beta) and high-accuracy async diarization
- Enhanced handling of similar voices and short utterances
- Language support: 6 languages with Universal-3 Pro and 99+ languages with Universal models for async diarization
- Pricing: async tiered pricing starting at $0.15/hr for Universal-2 and $0.21/hr for Universal-3 Pro; streaming diarization is a $0.06/hr add-on to streaming transcription
2. Deepgram
Deepgram's diarization emphasizes processing speed and operates in a language-agnostic manner. It supports both batch and streaming diarization and is integrated with its Nova-3 speech recognition model.
Key features:
- No fixed limit on number of speakers
- Language-agnostic operation
- Focus on processing speed (per their benchmarks)
- Integrated with the Nova-3 model
Deepgram's speed-first positioning suits high-throughput pipelines. That said, in independent benchmarks from Hamming.ai across 4M+ production calls, AssemblyAI's Universal-3 Pro Streaming posted 307ms P50 latency and 8.14% word error rate versus Deepgram Nova-3's 516ms P50 and 9.87% WER. Cleaner, faster turn detection also feeds cleaner inputs to the diarizer—so the gap matters for real-time speaker attribution, not just raw transcription. For a fuller side-by-side, see our Deepgram alternatives breakdown.
3. Speechmatics
Speechmatics claims to be 25% ahead of its closest competitor in accuracy according to its own benchmarks. It offers speaker diarization through its Flow platform with both cloud and on-premise deployment, and supports real-time diarization.
Key features:
- Enhanced accuracy through punctuation-based corrections
- Configurable maximum speakers (2–20)
- Support for 30+ languages
- Processing time increase of 10–50% when diarization is enabled (per their documentation)
Speechmatics provides deployment flexibility for enterprise environments with on-premise or specific compliance requirements.
4. Gladia
Gladia combines Whisper's transcription with PyAnnote's diarization, providing an integrated option for developers already using Whisper. Its enhanced diarization mode adds processing for edge cases.
Key features:
- Whisper + PyAnnote integration
- Enhanced diarization mode for challenging audio
- Configurable speaker hints
- Streaming support available
This gives teams already using Whisper a path to add diarization without managing multiple services.
5. PyAnnote
PyAnnote is a widely-used open-source speaker diarization toolkit, now in version 3.1. It reports roughly 10% DER with optimized configurations on standard benchmarks and processes at a 2.5% real-time factor on GPU. It's batch-focused, and serves as the foundation for several commercial solutions, including Gladia.
A note on PyAnnote's benchmarks: they're reported purely as DER, on diarization in isolation from transcription. That's a reasonable academic metric, but it doesn't capture what production teams actually need (more on this in the evaluation section below). PyAnnote is well-suited for research projects and teams with ML expertise who need a customizable, self-hosted solution.
Key considerations:
- Requires training or fine-tuning for optimal performance on specific use cases
- Supports Python 3.7+ on Linux and macOS
- Requires a Hugging Face authentication token for pre-trained model access
- Active research community and regular updates
6. NVIDIA NeMo
NVIDIA NeMo introduces Sortformer, an end-to-end diarization approach using an 18-layer Transformer architecture that treats diarization as a unified problem rather than a multi-stage pipeline.
Key features:
- End-to-end neural architecture
- Multi-scale diarization decoder (MSDD)
- Seamless ASR integration
- GPU-optimized processing
It supports both oracle VAD (ground-truth timestamps) and system VAD (model-generated timestamps). NeMo is designed for researchers and teams building custom multi-speaker ASR systems with GPU resources and ML expertise.
7. Kaldi
Kaldi is a speech recognition toolkit widely used in academic research that includes speaker diarization capabilities, with extensive customization options.
With Kaldi, users can either train models from scratch with full control over the pipeline, or use the pre-trained X-Vectors network or PLDA backend from the Kaldi website. Getting started requires understanding its recipe-based architecture; this Kaldi tutorial provides an introduction. Kaldi is best suited for academic research and teams who need maximum flexibility and control.
8. SpeechBrain
SpeechBrain is a PyTorch-based toolkit offering 200+ recipes for speech tasks, including speaker diarization. It provides both pre-trained models and training frameworks.
Key features:
- Extensive recipe collection covering 20+ speech tasks
- PyTorch-based architecture for easy integration
- Modular design allowing component customization
- Active development community
It includes dynamic batching, mixed-precision training, and single/multi-GPU support, and is particularly suitable for teams familiar with PyTorch who want to experiment with different diarization approaches.
Real-time (streaming) speaker diarization
For a long time, reliable diarization meant batch processing—and the only solid path to real-time speaker separation was multichannel audio, with each speaker on a dedicated channel. That's no longer the case.
Streaming speaker diarization now identifies who's speaking on a single live audio stream, assigning labels within milliseconds as the conversation unfolds. With AssemblyAI, you enable it by adding speaker_labels: true to a streaming WebSocket connection and, optionally, a max_speakers hint (1–10) to improve accuracy when you know how many people are on the call.
The trade-off versus batch is real: streaming can't look ahead, so it commits to a label with only the audio it has heard so far, and the first few turns of a conversation are the least stable. But for use cases where speaker identity has to drive behavior during the conversation—a voice agent that needs to tell the customer from the human agent, live contact center coaching, or real-time captioning—streaming is the only option.
A few practical notes for streaming:
- Turn detection drives latency. The biggest delay isn't the diarization—it's waiting for someone to finish talking. Neural turn detection that uses acoustic and linguistic signals beats voice-activity-detection alone, which tends to misfire on mid-sentence pauses.
- Short utterances are hard. Brief responses like "yeah" or "okay" with under a second of audio may come back labeled UNKNOWN; handle that gracefully in your client.
- Two speakers is the sweet spot. Accuracy is highest with two speakers (agent-customer calls) and degrades as the speaker count climbs.
- Multichannel is still a great option when your infrastructure already separates speakers onto different channels (common in telephony)—you get perfect separation with no diarization overhead.
AssemblyAI's streaming diarization is in public beta, priced at $0.06/hr as an add-on to streaming transcription, and supported on Universal-3 Pro Streaming plus the multilingual streaming models.
Implementation best practices for speaker diarization
Moving from theory to practice requires navigating real-world audio. While no AI model is perfect, you can significantly improve results by following a few best practices.
- Optimize for your use case. For batch processing of large files, you can afford more processing time for the highest accuracy. For real-time applications, balance accuracy against low latency for a smooth experience.
- Handle real-world audio. Background noise, overlapping speech, and similar voices are common. Always test on a sample of your own audio. Models trained on diverse, noisy datasets consistently outperform those trained only on clean audio.
- Debug common errors. Is the model misidentifying the number of speakers? Are two speakers being merged into one label? Listen to the segments where errors occur—this usually reveals audio-quality issues or very short turns you can address.
- Think in pipelines. Diarization is rarely the final step. Once you have accurate speaker labels, you can run per-speaker sentiment analysis, topic tracking, or summarization to extract deeper insights.
How to choose a speaker diarization solution
For production applications:
- High accuracy in noisy conditions → AssemblyAI's 30% improvement in real-world audio and 43% improvement on short segments (250ms)
- Real-time voice agents and live coaching → a provider with mature streaming diarization (AssemblyAI, Deepgram, Speechmatics)
- Whisper ecosystem → Gladia provides integrated Whisper + diarization
- Enterprise deployment flexibility → Speechmatics offers cloud and on-premise options
For conversation intelligence use cases, consider your specific requirements:
- Conference room recordings: Look for solutions tested on noisy, multi-speaker environments
- Call center analytics: Accuracy on brief utterances and speaker count precision are critical
- Meeting transcription: Real-time capabilities and handling of overlapping speech matter
- Interview processing: Clear speaker separation and accurate timestamps are essential
For research and development:
- Maximum control → NVIDIA NeMo's Sortformer architecture
- Established framework → PyAnnote 3.1 with pre-trained models
- Academic benchmarking → Kaldi's extensive configuration options
- PyTorch ecosystem → SpeechBrain's recipe collection
Open-source vs. managed API comes down to development time (APIs ship faster), customization needs (open-source gives model control), infrastructure (self-hosting requires GPUs), and maintenance overhead (APIs handle updates automatically).
How to evaluate speaker diarization quality
Most published diarization benchmarks report a single number: Diarization Error Rate (DER), which combines missed speech, false alarms, and speaker confusion. Lower is better, and production systems often target DER below 10%.
Here's the catch, and it's the most important thing in this guide: DER alone doesn't reflect what most teams actually care about. DER measures diarization in isolation from transcription. But in production, what matters is whether the right speaker label lands on the right words, whether timestamps are precise, whether overlapping speech is transcribed and attributed correctly, and whether the system gets the number of speakers right. A system can post a great DER and still produce transcripts that feel wrong to your users.
That's why AssemblyAI reports cpWER (which ties speaker labels to the actual transcribed words) and speaker count error rate alongside DER. It's also worth being skeptical of standalone, DER-only benchmarks from diarization-only tools: a strong DER on a research dataset doesn't guarantee accurate, word-aligned speaker labels on your audio.
For streaming, two more metrics matter beyond accuracy:
- Latency — the delay between speech and a labeled transcript. 200ms is fine for a voice agent; two seconds isn't.
- Label stability — how often labels change or correct themselves. If "Speaker A" flips to "Speaker B" three times in 30 seconds, your UI looks broken even if the final transcript is right.
Whatever metrics you track, test with audio that matches your real use case—turn-taking speed, audio quality variation, short utterances, and overlapping speech—rather than relying on published benchmark numbers alone.
Limitations of speaker diarization
Speaker diarization has improved dramatically, but some limitations remain. Several factors can still impact accuracy on single-channel audio:
- Speaker talk time
- Conversational dynamics
Historically, speaker talk time directly correlated with identification accuracy, with older systems requiring 15–30 seconds of speech for reliable detection. That's no longer true of modern models—AssemblyAI's Universal-3 Pro reliably identifies speakers from far shorter segments (down to 250ms), and async prompted speaker diarization can attribute even single-word acknowledgments. More audio still generally yields higher confidence, but the old 15–30 second floor is outdated.
Conversational dynamics also affect accuracy:
- Turn-taking patterns: Clear speaker transitions improve labeling.
- Overlapping speech: Crosstalk can reduce accuracy and may create phantom speakers, though modern systems are better at detecting and labeling overlapping segments.
- Background noise: High noise levels (low SNR) can degrade performance.
- Speech energy: Rapid interruptions and very similar voices can challenge clustering algorithms.
These challenging conditions—noisy environments, overlapping speech, and similar voices—are where diarization accuracy varies most between solutions. For real-time applications, you can sidestep single-channel limitations entirely with multichannel audio, where each speaker is on a separate channel. For teams building production applications, it's important to evaluate how each solution performs on your specific audio rather than on clean benchmark sets.
Build live transcription and voice apps with AssemblyAI
AssemblyAI provides production-ready speaker diarization—async and real-time—with documented performance improvements in challenging audio. By integrating diarization with other Voice AI features, teams gain:
- Proven accuracy: Industry-leading 2.9% speaker count error rate and 30% improvement in noisy conditions
- Real-world performance: Optimizations for challenging audio, including 43% improvement on brief utterances (250ms)
- Real-time support: Streaming diarization on the same WebSocket as transcription, for voice agents and live coaching
- Simple implementation: Straightforward API integration with comprehensive documentation and SDKs
- Enterprise security: SOC 2 Type 2 certified with enterprise-grade security practices
- Continuous improvements: Regular model updates based on customer feedback and research
For full real-time voice applications, AssemblyAI's Voice Agent API goes a step further—a single WebSocket that replaces separate STT, LLM, and TTS providers at a $4.50/hr flat rate, with Universal-3 Pro powering the transcription layer.
Test our speaker diarization with your own audio in the AssemblyAI Playground, or sign up for a free account to get started with $50 in credits.
Frequently asked questions about speaker diarization
Is speaker diarization supported for live streams and voice agents?
Yes. AssemblyAI supports real-time streaming speaker diarization on a single live audio stream—enable it by adding speaker_labels: true to a streaming WebSocket connection. It works with the Universal-3 Pro Streaming model and the multilingual streaming models, which makes it suitable for voice agents, live contact center coaching, and real-time captioning. Batch (async) diarization remains available for the highest accuracy on pre-recorded files.
How does diarization handle overlapping speech?
When two people talk simultaneously, single-channel diarization assigns the overlapping segment to one speaker (typically the dominant voice). If crosstalk is frequent in your audio, the most reliable fix is multichannel recording—each speaker on a separate channel—which eliminates overlap entirely and gives perfect speaker separation without diarization overhead.
How does diarization handle speakers with similar voices?
Similar voices are one of the harder cases, because the model distinguishes speakers by comparing voice embeddings. Accuracy improves with more audio per speaker and with a max_speakers (or speakers_expected) hint when you know the count. AssemblyAI's updated speaker embedding model specifically targeted similar-voice and short-utterance failure modes, contributing to a 30% improvement in noisy conditions.
How many speakers can speaker diarization detect?
It depends on the provider. AssemblyAI supports 1–20 expected speakers for async diarization (via speakers_expected) and 1–10 for streaming (via max_speakers). Accuracy is highest with two speakers and gradually decreases as the count rises, since there's less audio per person to build a reliable voice profile.
What's the minimum audio needed to detect a speaker?
Modern models no longer need 15–30 seconds. AssemblyAI's Universal-3 Pro reliably identifies speakers from segments as short as 250ms. In streaming, utterances under one second may occasionally return an UNKNOWN label, so it's good practice to handle those gracefully—but the long minimum-duration requirement of older systems no longer applies.
What is the difference between speaker diarization and speaker recognition?
Speaker diarization answers "who spoke when?" by clustering voices and assigning generic labels like "Speaker A" and "Speaker B"—it doesn't know speakers' real identities. Speaker recognition identifies a specific person by matching their voice to a known profile, answering "Is this person John Doe?" AssemblyAI's Speaker Identification builds on diarization to assign real names or roles from conversational context, without pre-enrolled voiceprints.
How should I evaluate a speaker diarization API?
Don't rely on DER alone. DER measures diarization in isolation, but production quality depends on the right speaker label landing on the right words (measured by cpWER), accurate timestamps, correct speaker counts, and—for live use cases—latency and label stability. Test each solution on audio that matches your real conditions rather than on clean benchmark datasets.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts



