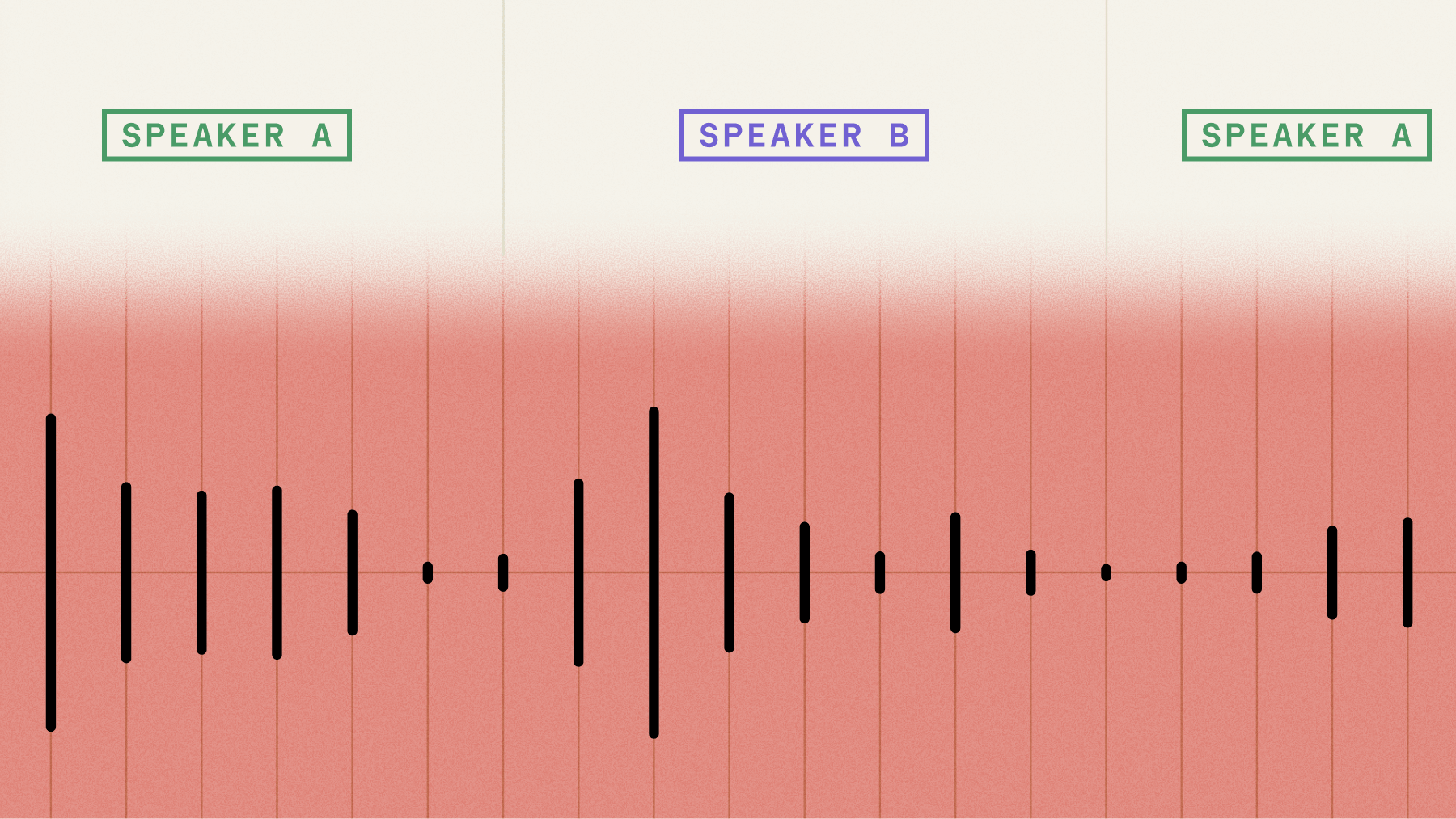
Speaker Diarization: Adding speaker labels for enterprise speech-to-text
Speaker Diarization, or speaker labels, models automatically assign speakers to words spoken in an audio/video transcription. In this article, we look at the benefits, challenges, and use cases for Speaker Diarization.


Speaker diarization transforms multi-speaker audio into actionable business intelligence, and a recent market survey shows the impact: over 70% of companies using conversation intelligence reported a measurable increase in end-user satisfaction. When your sales team records calls with prospects, customer support handles complex inquiries, or product teams analyze user interviews, you need to know more than just what was said—you need to know who said it and when.
This foundational Voice AI capability separates speakers in audio streams, enabling enterprises to extract insights from conversations that would otherwise remain buried in undifferentiated transcripts.
With AI adoption on the rise—a 2024 McKinsey report found 88% of organizations use AI in at least one business function—companies that process enormous amounts of customer data are turning to Voice AI technology such as Automatic Speech Recognition (ASR), Speech Understanding, and Large Language Models to build tools that help their users better understand speech or spoken data.
In this article, we'll explore how speaker diarization creates business value, examine proven enterprise implementations, and provide practical strategies for adding this essential Voice AI capability to your applications.
What is Speaker Diarization?
Speaker diarization automatically identifies and labels different speakers in audio recordings, answering "who spoke when" by assigning consistent labels like "Speaker A" and "Speaker B" throughout multi-speaker conversations. This Voice AI technology enables businesses to analyze conversation dynamics, measure speaker participation, and extract speaker-specific insights from meetings, calls, and interviews.
In the field of Automatic Speech Recognition, Speaker Diarization is broken into two components:
- The number of speakers that can be detected in an audio or video file.
- The words or utterances that can be assigned to the appropriate speaker in the audio or video file.
Thanks to modern advances in AI, Speaker Diarization models can automatically assign the correct number of speakers in the file, as well as the utterances, words, and phrases associated with that speaker.
The speaker labels are typically assigned as "Speaker A," "Speaker B," etc., and remain consistent throughout the transcription text.
Business Benefits and ROI of Speaker Diarization
Speaker diarization makes transcripts immediately more valuable for business analysis. According to an Opus research survey on contact center speech analytics, 72% of organizations saw improved customer experience, 68% reduced costs, and 52% increased revenue by transforming unstructured text into analyzable conversation data.
The readability difference is immediate:
Take a look at this basic transcription text without Speaker Diarization:
But how did you guys first meet and how do you guys know each other? I actually met her not
too long ago. I met her, I think last year in December, during pre season, we were both
practicing at Carson a lot. And then we kind of met through other players. And then I saw her
a few her last few torments this year, and we would just practice together sometimes, and
she's really, really nice. I obviously already knew who she was because she was so good.
Right. So. And I looked up to and I met her. I already knew who she was, but that was cool
for me. And then I watch her play her last few events, and then I'm actually doing an
exhibition for her charity next month. I think super cool. Yeah. I'm excited to be a part of
that. Yeah. Well, we'll definitely highly promote that. Vania and I are both together on the
Diversity and Inclusion committee for the USDA, so I'm sure she'll tell me all about that.
And we're really excited to have you as a part of that tournament. So thank you so much. And
you have had an exciting year so far. My goodness. Within your first WTI 1000 doubles
tournament, the Italian Open.Congrats to that. That's huge. Thank you.And then look at this transcription text with Speaker Diarization:
Speaker A: But how did you guys first meet and how do you guys know each other?
Speaker B: I actually met her not too long ago. I met her, I think last year in December,
during pre season, we were both practicing at Carson a lot. And then we kind of met through
other players. And then I saw her a few her last few torments this year, and we would just
practice together sometimes, and she's really, really nice. I obviously already knew who she
was because she was so good.
Speaker A: Right. So.
Speaker B: And I looked up to and I met her. I already knew who she was, but that was cool
for me. And then I watch her play her last few events, and then I'm actually doing an
exhibition for her charity next month.
Speaker A: I think super cool.
Speaker B: Yeah. I'm excited to be a part of that.
Speaker A: Yeah. Well, we'll definitely highly promote that. Vania and I are both together on the Diversity and Inclusion committee for the USDA. So I'm sure she'll tell me all about
that. And we're really excited to have you as a part of that tournament. So thank you so
much. And you have had an exciting year so far. My goodness. Within your first WTI 1000
doubles tournament, the Italian Open. Congrats to that. That's huge.
Speaker B: Thank you.The second example is much easier to read at a glance, but readability is just the beginning. Speaker Diarization opens up significant analytical opportunities for companies. By identifying each speaker, product teams can build tools that analyze each speaker's behaviors, identify patterns and trends, and extract insights that inform business strategy.
The business impact is measurable across key performance areas:
Explore how labeled transcripts improve CX, cut manual review, and drive revenue across teams. Our experts will map impact to your use case.
Talk to AI expertProven Use Cases and Customer Success Stories
Top companies are already building with Speaker Diarization to create powerful transcription and analysis tools for their customers. Here's how businesses across industries are leveraging this Voice AI capability:
Virtual Meetings and Hiring Intelligence Platforms
With Speaker Diarization, virtual meeting and hiring intelligence platforms can create useful post-meeting/interview transcripts broken down by speaker to serve their users. Then, the platforms can offer additional AI analysis on top of this transcription data, such as meeting summaries, analysis by speaker, or additional insights.
AI-powered meeting recorder Grain, for example, uses transcription and Speaker Diarization to help its customers realize significant time savings in note-taking, record-keeping, and meeting analysis.

Hiring intelligence platform Screenloop added AI-powered transcription and Speaker Diarization to cut the time spent on manual tasks by 90% for its customers. Additional analysis of each conversation also helps its customers perform more effective training, reduce time-to-hire, and reduce hiring bias.
Conversation Intelligence
Speaker Diarization also helps augment Conversational Intelligence platforms by providing users with a readable text of each conversation.

Then, these conversations can be more easily summarized using an AI summarization model, as shown above.
Sentiment Analysis models can also be used to automatically flag changes in sentiments during a conversation that suggest buying indicators or potential problems.

Jiminny, a leading Conversation Intelligence, sales coaching, and call recording platform, incorporated transcription and Speaker Diarization to serve as the foundation for additional AI analysis tools–helping its customers secure a 15% higher win rate.
CallRail, a lead intelligence software company, integrated AI models, including Speaker Diarization, to double the number of customers using its Conversational Intelligence product.
AI Subtitle Generators
AI subtitle generators automatically transcribe audio and video files and add textual subtitles directly onto the specified video. Speaker Diarization models can be used to break down these subtitles by speakers, helping users more easily meet compliance and accessibility requirements, as well as making the videos easier to consume for those who wish to view them without sound.

Call Centers
Call Center platforms are integrating Voice AI systems, including Speaker Diarization, to optimize workflows and realize impressive results for their customers. For example, industry data shows that clients implementing speech technologies see an average ROI of 26% beginning in the second year. Other results include:
- Uncovering intelligent insights that increase agent occupancy.
- Discovering critical customer insights about satisfaction, complaints, brand strength, churn risk, competitor analysis, and more.
- Improving quality monitoring by helping managers review more agent/customer conversations in a shorter time frame.
Sales Intelligence
With a complete Voice AI system that includes Speaker Diarization, sales intelligence platforms are building tools and features that let users perform intensive analysis on all conversational data they process.
Similar to call coaching, sales intelligence platforms that add Voice AI can transcribe and analyze conversations to determine a prospect's past behavior and preferences, as well as to predict future behaviors. This analysis can then be used to create personalized outreach or help users prioritize which leads are more likely to convert.
Voice AI can also be used to automatically recap a list of action items for the representative to take once the call is complete.
Competitive Advantages Through Voice AI Implementation
Leading organizations like Circleback AI, Supernormal, and CustomerIQ trust AssemblyAI's speaker diarization to power their Voice AI applications.
These companies gain measurable competitive advantages:
- Superior product analytics: Speaker-specific analysis including talk time ratios, sentiment progression, and interaction patterns
- Faster market entry: Proven Voice AI infrastructure eliminates months of development time
- Scalable growth: Infrastructure handles millions of processed hours without performance degradation
- Continuous innovation: Latest Voice AI improvements integrated automatically
In today's market, the quality of conversational insights directly impacts competitive positioning. Companies implementing speaker diarization create differentiation through deeper analytical capabilities that competitors using basic transcription simply cannot match.
Implementation Strategies for Enterprise Environments
Most enterprises implement speaker diarization in 2-4 weeks using a systematic approach that ensures measurable ROI:
Start with Clear Business Objectives
Before implementing speaker diarization, identify specific business outcomes you want to achieve. Are you looking to improve customer satisfaction scores? Reduce quality assurance review time? Clear objectives guide implementation decisions and help measure success.
Choose the Right Integration Approach
Speaker diarization can be implemented through several methods, each suited to different use cases:
- Asynchronous processing: Best for batch processing recorded conversations where real-time results aren't required. This approach offers the highest accuracy and is ideal for call centers, meeting platforms, and content creation tools.
- Real-time streaming: Necessary for live applications like virtual assistants or real-time coaching tools. While slightly less accurate than asynchronous processing, modern streaming models deliver impressive results for time-sensitive applications.
- Hybrid approaches: Many enterprises combine both methods, using real-time processing for immediate insights and asynchronous processing for detailed analysis and record-keeping.
Design for Scale from Day One
Enterprise Voice AI implementations must handle varying loads efficiently. Consider these scaling factors:
- Peak usage patterns and seasonal variations
- Multi-language and accent requirements
- Storage and processing infrastructure needs
- Data retention and compliance requirements
Ensure Data Security and Compliance
Voice data often contains sensitive information. Implement robust security measures including:
- End-to-end encryption for data in transit and at rest
- Role-based access controls for transcription data
- Audit logging for compliance requirements
- Data residency options for regulatory compliance
Technical Requirements and Performance Considerations
Despite recent advances, understanding the technical characteristics and limitations of speaker diarization helps set appropriate expectations and design robust systems:
Audio Quality Requirements
- For reliable speaker detection, each person should speak for a sufficient amount of time, as very short utterances can be difficult to attribute correctly. However, documented improvements show that modern systems can now accurately identify segments as brief as 250ms, overcoming previous limitations.
- Well-defined conversations with clear turn-taking will be more accurately labeled than a conversation with over-talking or interrupting.
- While background noise can affect a model's ability to assign speaker labels, recent model improvements have delivered a 30% reduction in error rates for challenging acoustic environments.
- Overtalk, or when speakers talk over one another, may result in an additional imaginary speaker being assigned.
Processing Mode Considerations
The most advanced Speaker Diarization models are designed for asynchronous transcription while real-time Speaker Diarization requires a different type of model. Choose your processing mode based on your specific use case requirements:
Integration Best Practices
Keep in mind that Speaker Diarization models work best when each speaker contributes a sufficient amount of speech throughout the conversation. If a speaker only utters short phrases, such as "Right," or "Yes," the model may struggle to associate these utterances with a separate speaker.
Also, there is sometimes a limitation on the number of speakers a Speaker Diarization model can detect. If the enterprise platform is going to be processing a lot of noisy audio/video files, or files with many speakers, Speaker Diarization accuracy may be impacted.
However, for most enterprise platforms–such as call centers, hiring platforms, or sales intelligence–Speaker Diarization can be an extremely valuable addition to any AI-powered transcription or analysis tool.
Speaker Diarization is available as a feature of AssemblyAI's Universal model for pre-recorded audio. Users wishing to add speaker labels to a transcription simply need to have their developers include the speaker_labels parameter in their request body and set it to true. See a more detailed description of how to do this in the AssemblyAI docs.
Transform Your Business with Voice AI
Speaker diarization represents a fundamental shift in how businesses extract value from conversational data. It's not just about knowing what was said—it's about understanding the dynamics, patterns, and insights that emerge when you can attribute every word to its speaker.
The enterprises seeing the greatest returns from speaker diarization share common characteristics: clear business objectives, proven technical approaches, and scalable Voice AI partnerships.
In today's market, every customer interaction contains competitive insights. The ability to accurately separate and analyze speaker contributions has become essential for business growth.
Whether you're building a conversation intelligence platform, enhancing your call center analytics, or creating the next generation of meeting tools, speaker diarization provides the foundation for transformative Voice AI applications. The technology is mature, the business value is proven, and the implementation path is clear.
Ready to see how speaker diarization can transform your conversational data into actionable insights? Try our API for free and discover why leading companies trust AssemblyAI for their Voice AI needs.
Frequently Asked Questions About Speaker Diarization
What is the difference between speaker diarization and speaker identification?
Speaker diarization separates conversations by labeling speakers as "Speaker A" and "Speaker B" without knowing their identities, while speaker identification matches those labels to specific known individuals.
How do you evaluate speaker diarization performance?
The Diarization Error Rate (DER) measures the percentage of time incorrectly labeled, combining speaker confusion, false alarms, and missed detections—lower DER means higher accuracy.
What audio formats work best for speaker diarization?
High-quality recordings (16kHz+) with minimal background noise and limited speaker overlap deliver optimal results across formats like WAV, MP3, and MP4.
How long does implementation typically take?
Basic implementation takes hours using modern APIs, while production-ready systems with proper integration require 2-4 weeks depending on existing infrastructure complexity.
Can speaker diarization work in real-time?
Yes, real-time processing is available for immediate applications, though asynchronous processing typically delivers higher accuracy for detailed analysis needs.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts