

Architecture Overview
Here’s the general flow our app will follow:Getting started
Before we begin, make sure you have:- An AssemblyAI account and an API key. You can sign up for a free account and get your API key from your dashboard.
- An AWS account, an Access key, and permissions to S3, Lambda, and CloudWatch.
- A Genesys Cloud account with the necessary permissions to create call flows, phone numbers, and routes.
- ngrok installed.
Genesys AudioHook Monitor
In order to stream your voice calls to third party services outside of the Genesys Cloud platform, Genesys offers an official integration called AudioHook Monitor. This integration allows you to specify the URL of a WebSocket server that implements the AudioHook Protocol, and once a connection has been established, Genesys will send both text (metadata messages/events encoded as JSON) and binary data (WebSocket frames containing the raw audio data in μ-law (Mu-law, PCMU) format). An understanding of this integration and protocol is recommended before proceeding with this tutorial. Here are some helpful resources to get started:Step 1: Create a call flow in Genesys (optional)
You may already have an inbound call flow set up in Genesys (if so, skip to Step 3), but we’ll create a simple one from scratch for the sake of this tutorial.Adapting existing call flowsAll you need to add is the Audio Monitoring step from the toolbox and make
sure Suppress recording for the entire flow is unchecked in the flow’s
Recording and Speech Recognition settings.
1
Within the Architect tool, click Add to create a new call flow. Enter a Name for your flow and click Create Flow. Select the newly created flow to open the drag and drop editor.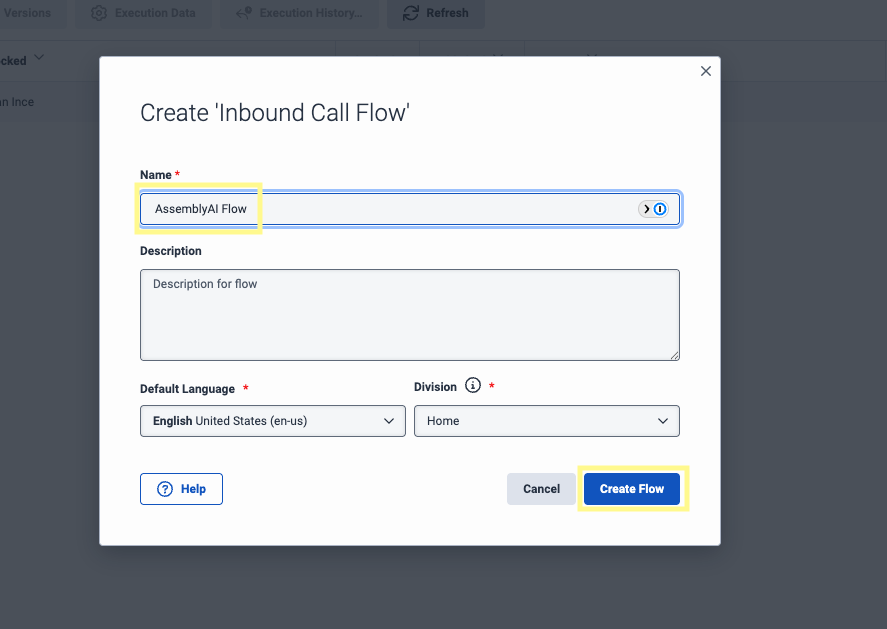
2
Create a Reusable Task from the bottom left of the left-side menu. From the Toolbox, search for Audio Monitoring and drag it just after the Start step of our flow. In the right-side menu for this option, make sure Enable Monitoring is enabled.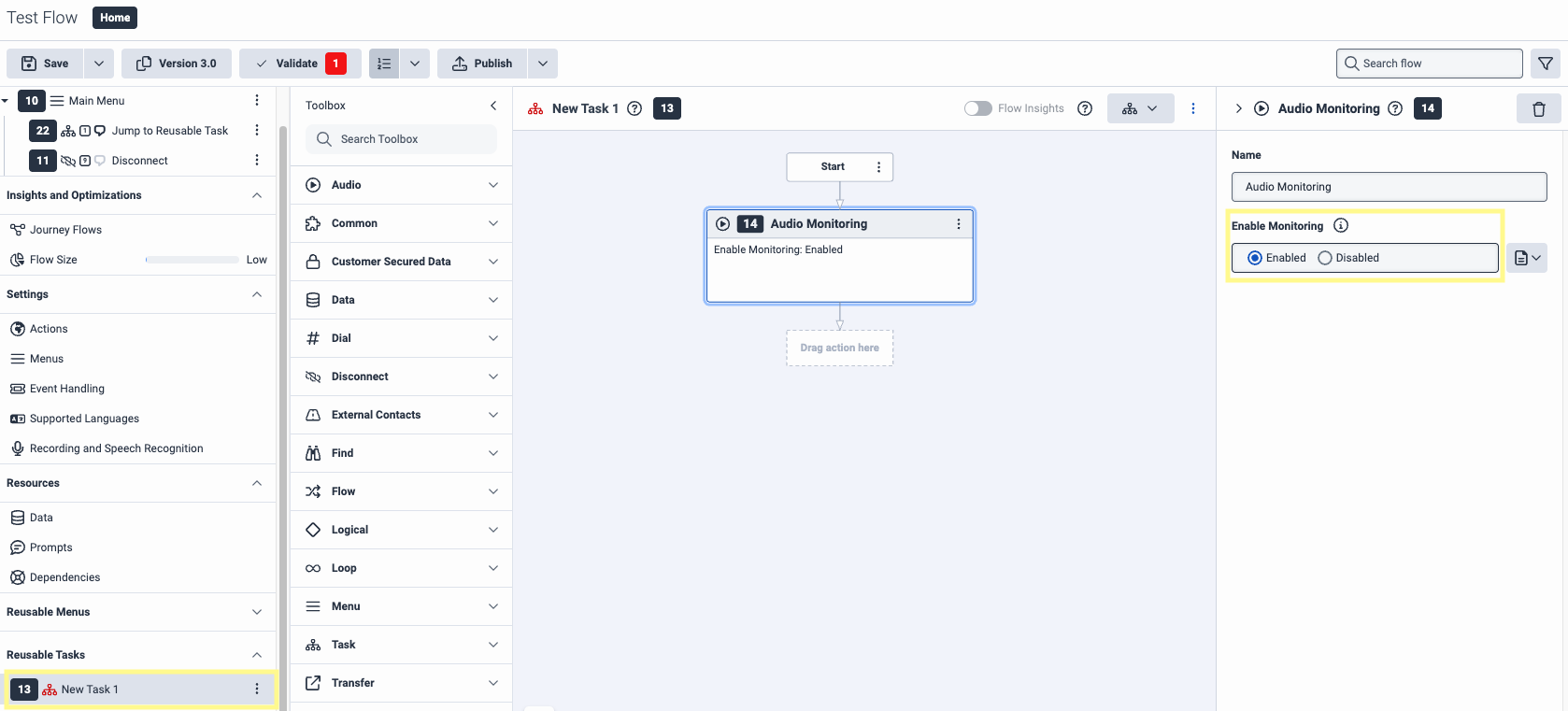
3
Back in the Toolbox, search for Transfer to User and set that as the next step. In the right-hand menu, under User select a caller. Under Pre-Transfer Audio and Failed Transfer Audio, type your preferred messages.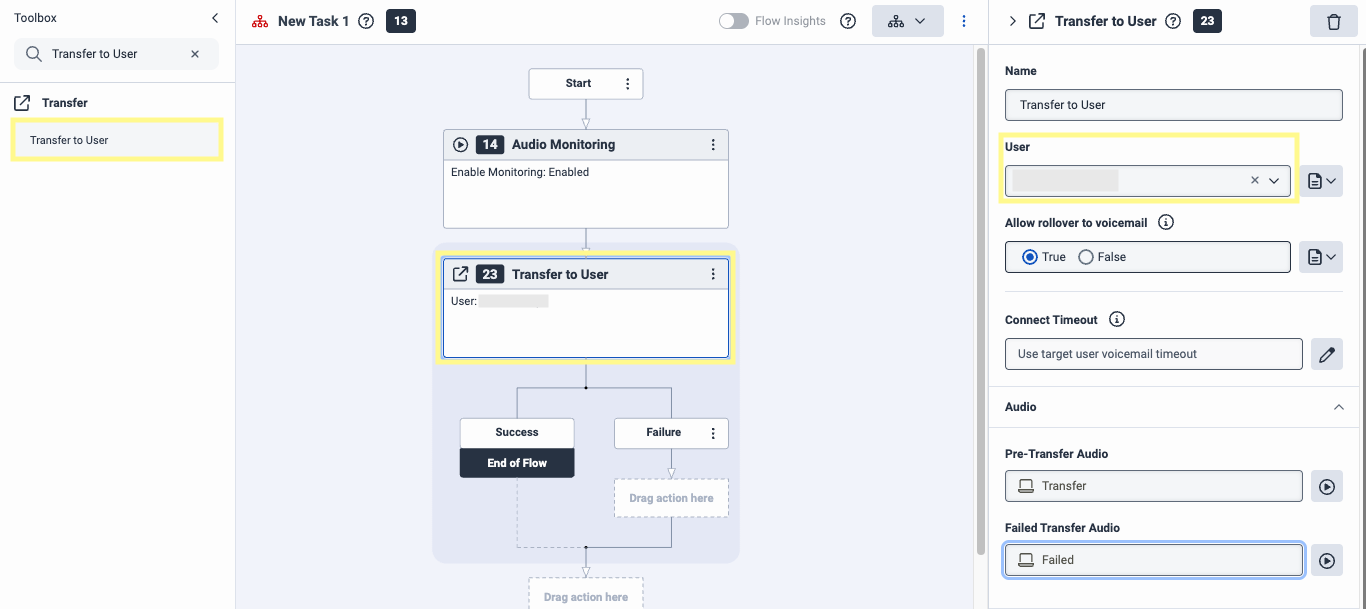
4
Search for Disconnect in the toolbox and drag that as the step following Failure.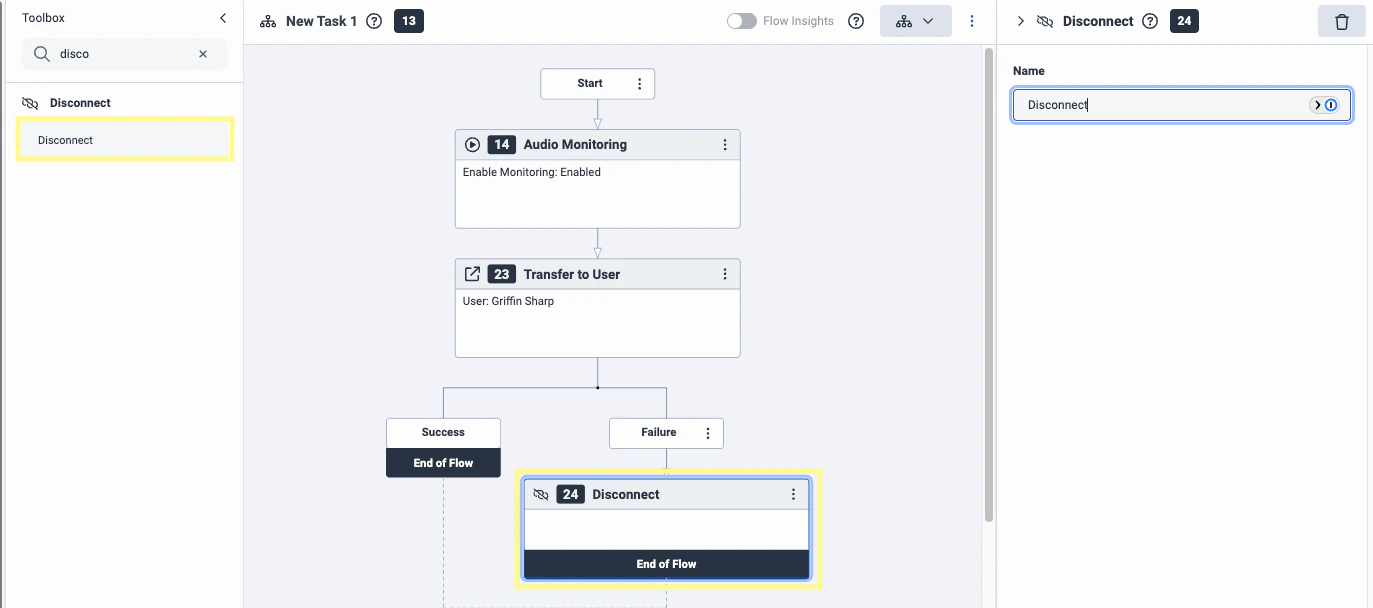
5
Search the Toolbox for Jump to Reusable Task and drag this tool to the Main Menu at the top of the left-side menu. Select a DTMF and Speech Recognition value (this will be used to transfer your call to the agent). Under Task, select the task you just created.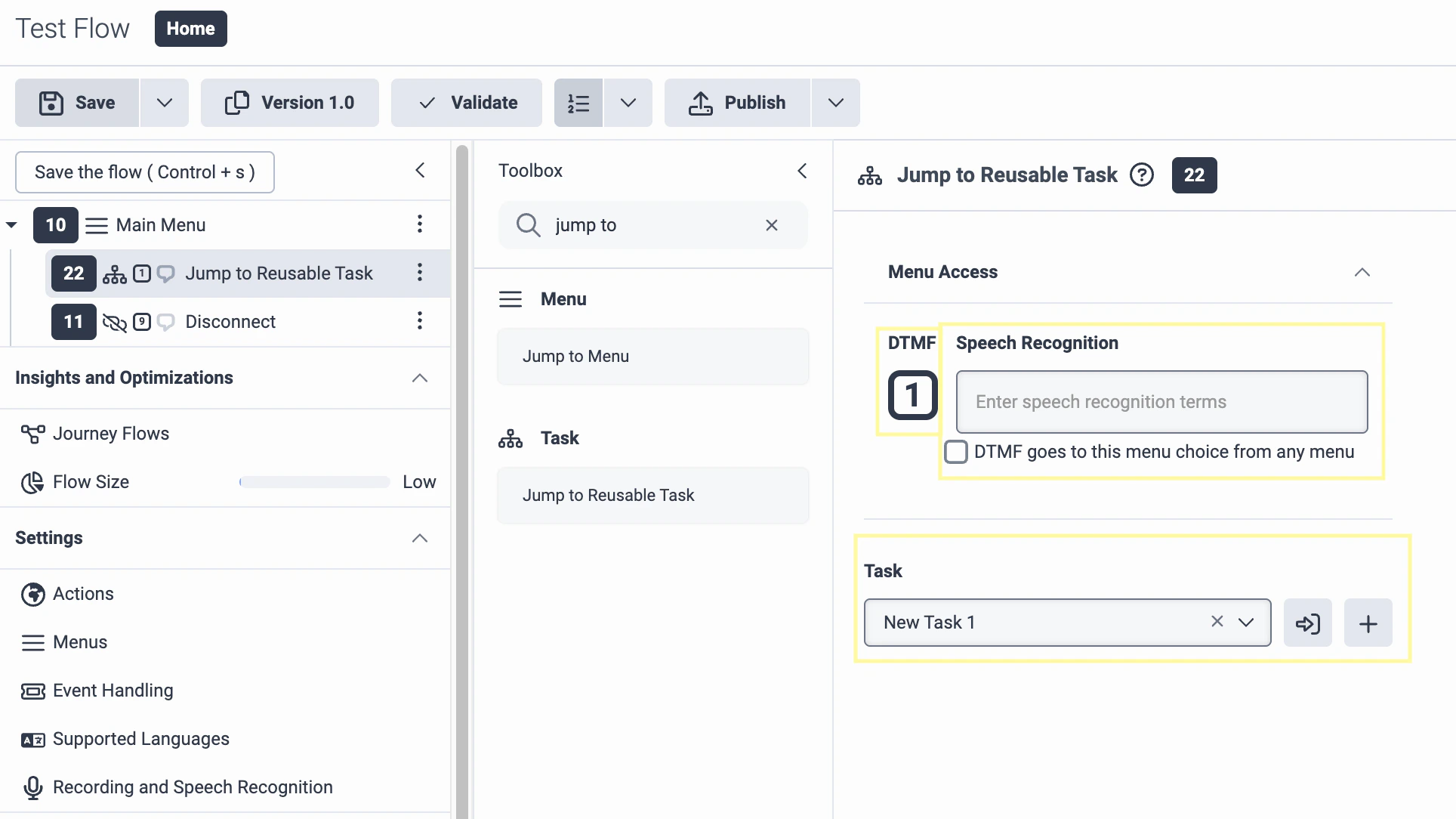
6
Under Settings in the left-side menu, navigate to the Recording and Speech Recognition section. Make sure Suppress recording for the entire flow is unchecked.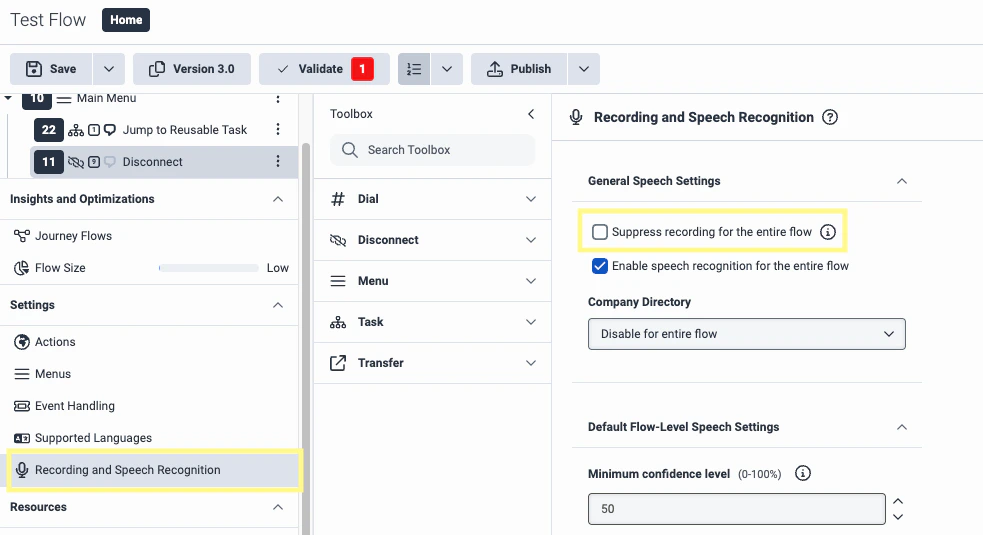
7
In the top navbar, make sure to click Save and then click Publish to have your changes take effect.
Step 2: Setup a phone and routing for your flow (optional)
1
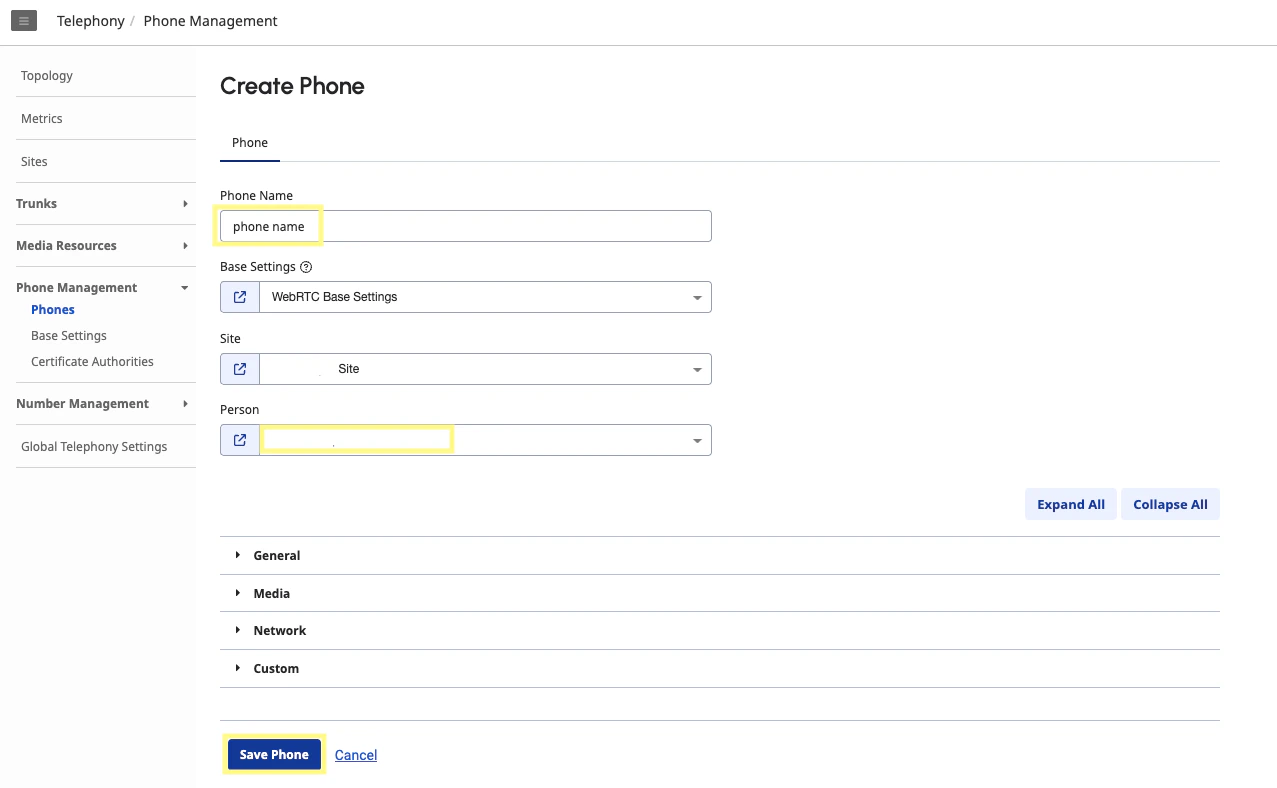
In the Genesys Cloud Admin section, navigate to the Phones page under the Telephony section and click Add to create a new phone. For Person, assign the User from your organization that you selected for the Transfer to User step in the previous section.
2
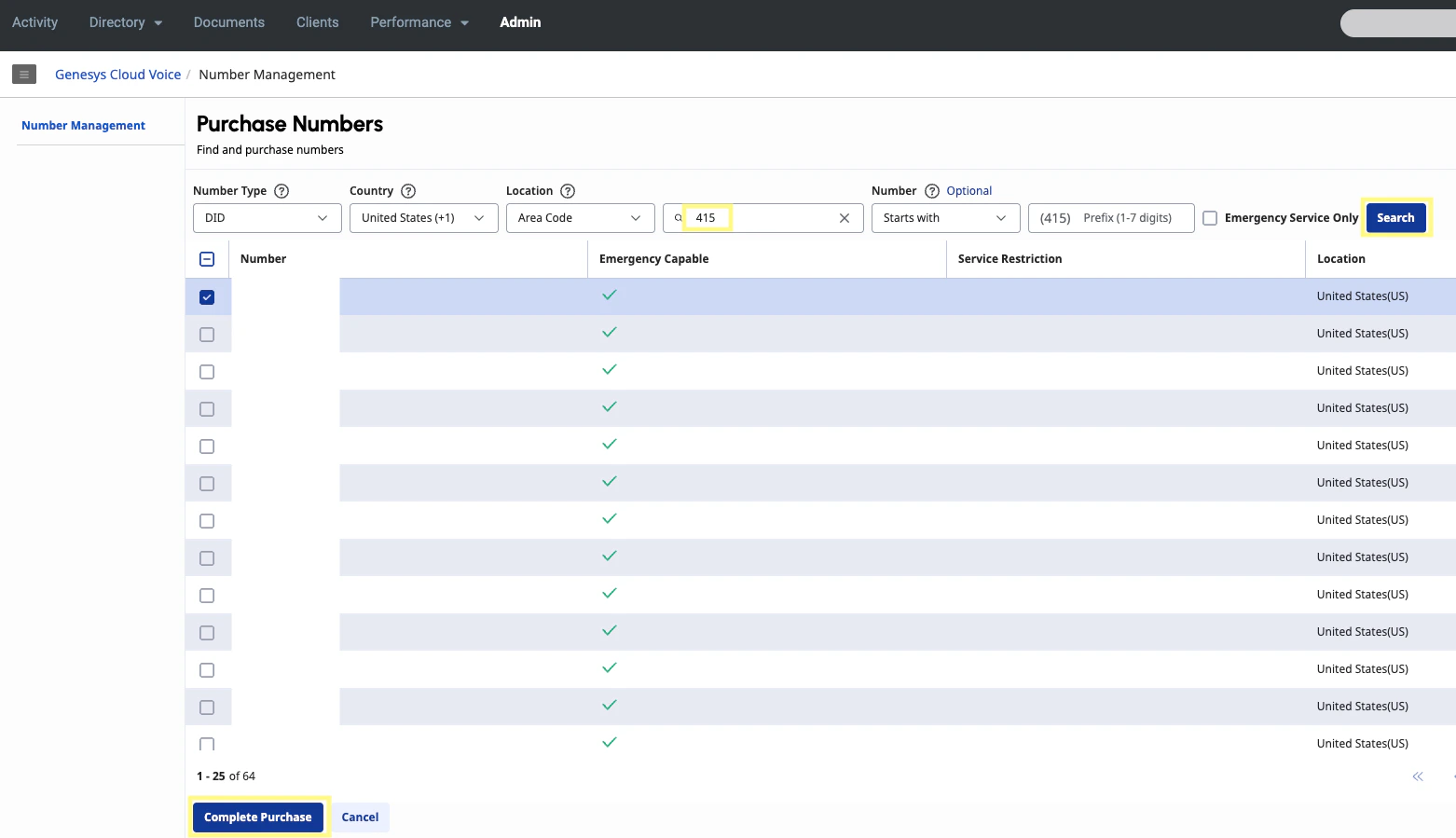
Navigate to the Number Management page under the Genesys Cloud Voice section and select Purchase Numbers.
Enter an area code and click Search. Select a phone number from the list and click Complete Purchase.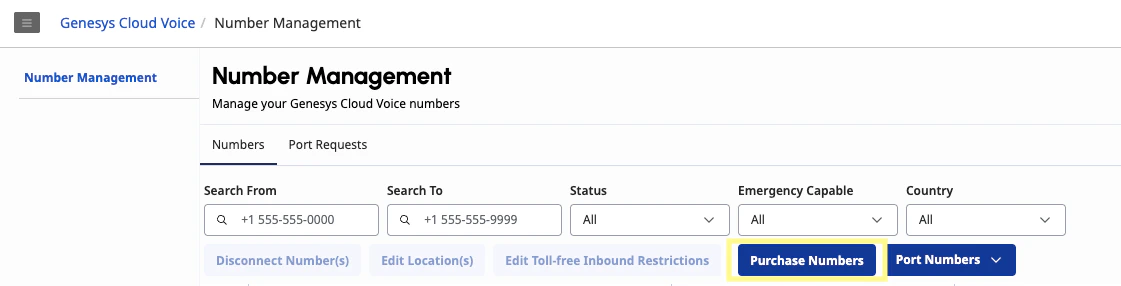
3
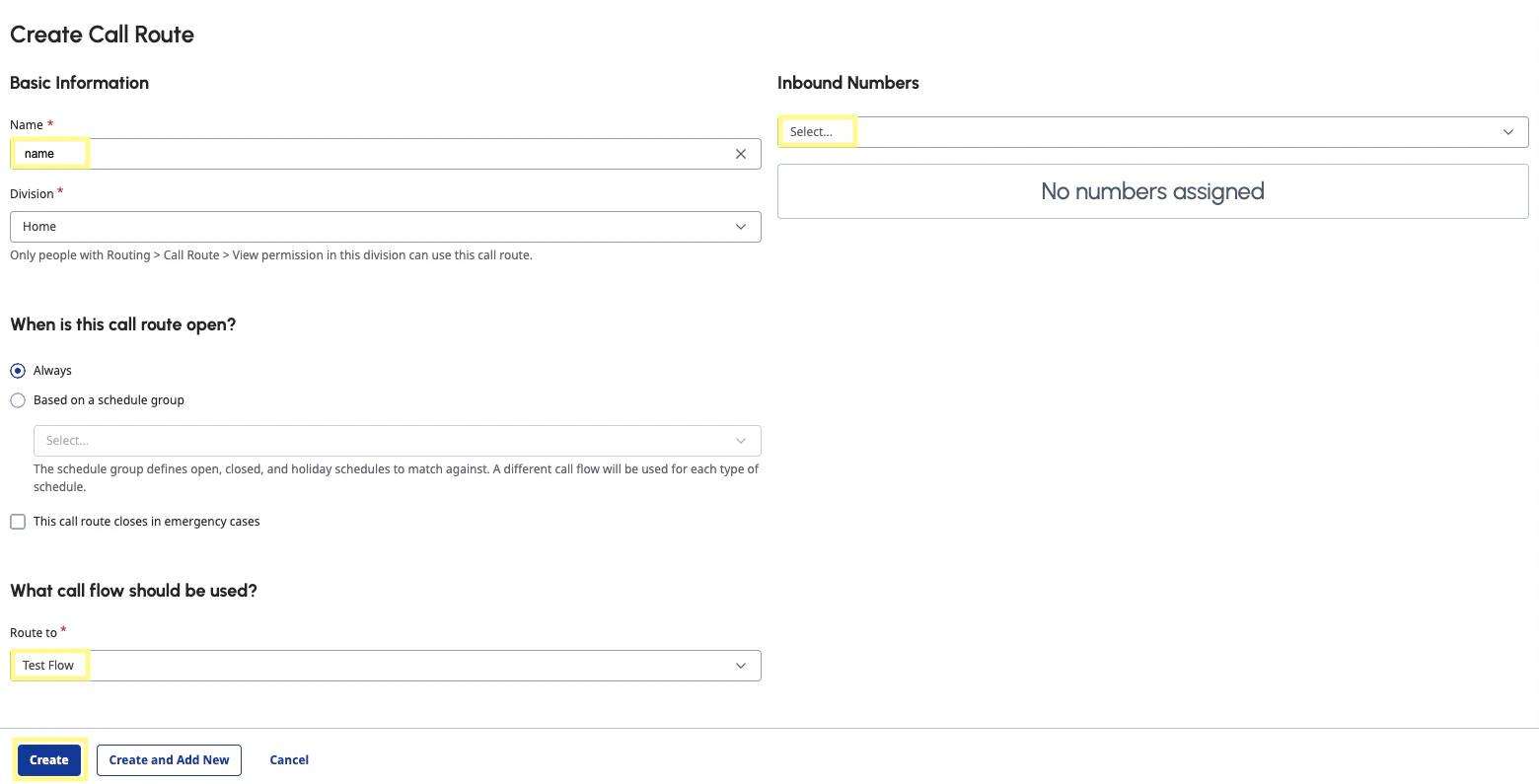
Navigate to the Call Routing page under the Routing section and select Add. Under What call flow should be used? select your flow. For Inbound Numbers, type the number you purchased in the above step. Then click Create.
4
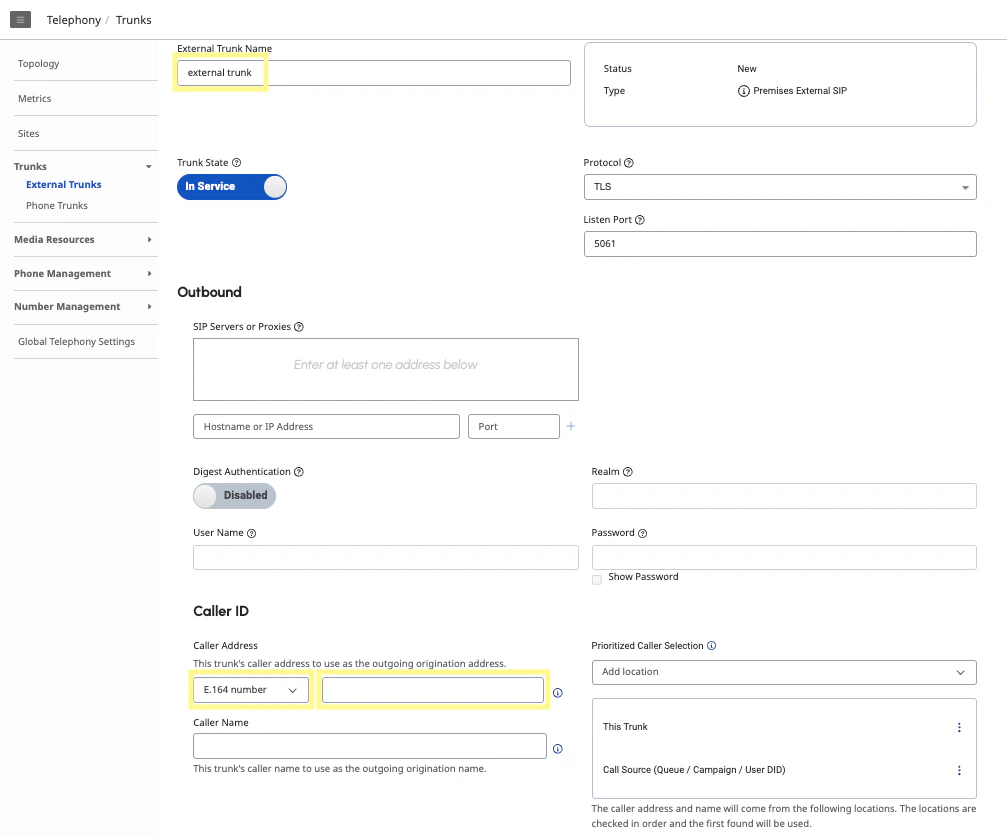
Under the Telephony section, navigate to the External Trunks page. Click Create New. Under Caller ID, the Caller Address will be an E.164 number and the phone number you created.
5
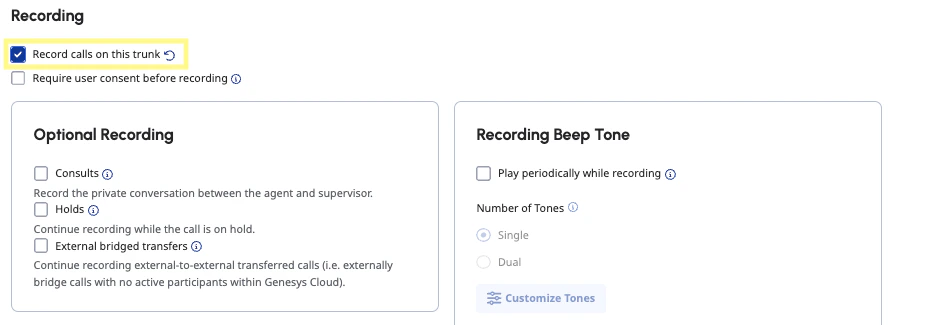
Under SIP Access Control, select Allow All (note: this is only for development and testing purposes, please specify actual IPs in production). Under the Media section, make sure you select Record calls on this trunk. Then click Save External Trunk (it may take a few moments for your trunk to be ready).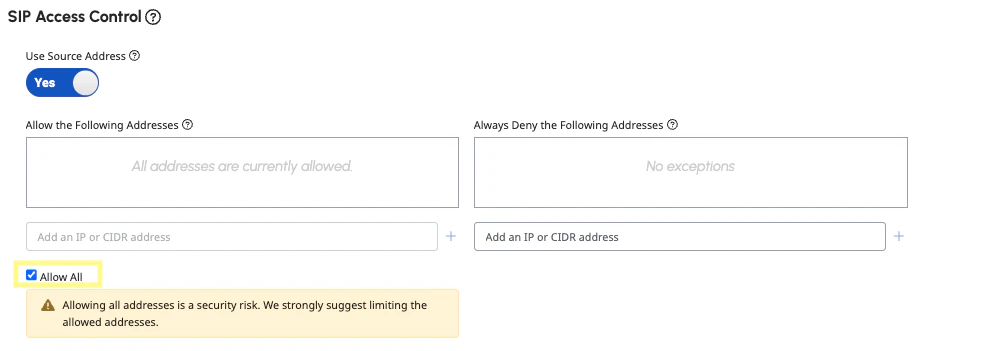
Step 3: Create a S3 bucket
After our Genesys call ends, store the audio file in S3.1
Click Create bucket. Give your bucket a name like 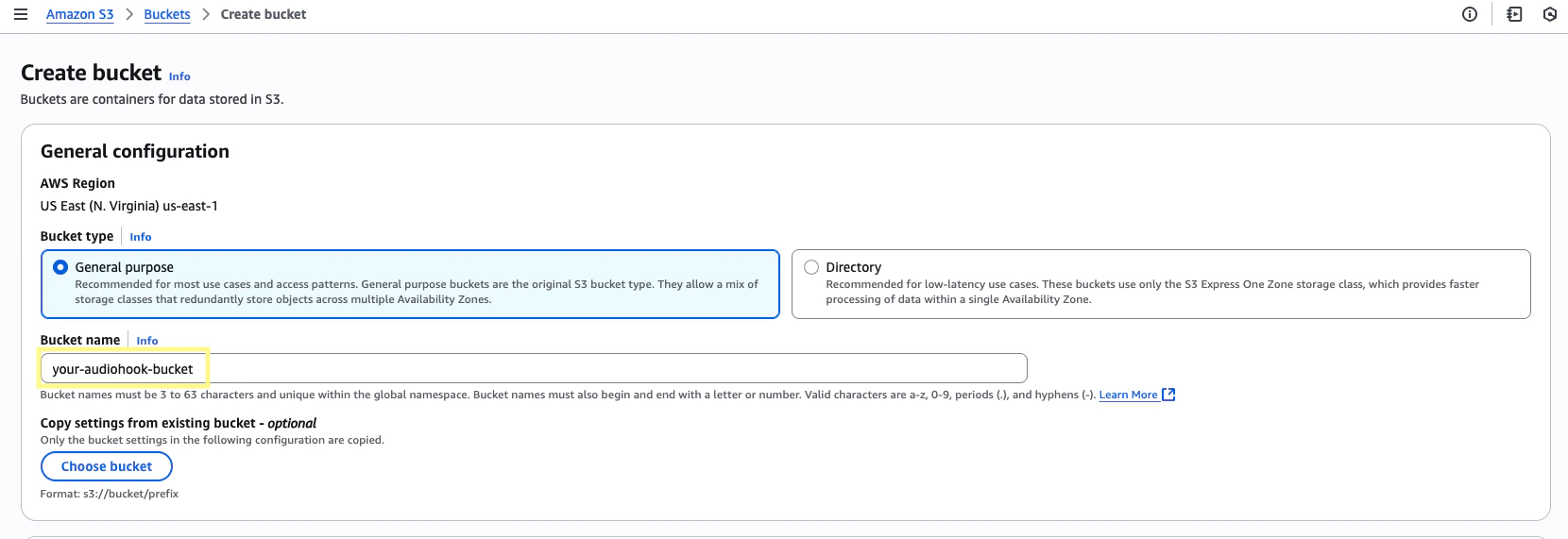
your-audiohook-bucket. Scroll down and click Create bucket.Step 4: Create a WebSocket server
In this step, we’ll set up a WebSocket server to receive messages and audio data from Genesys as they are sent. Our server must respond to certain events (i.e.open, close, ping, pause, etc.) according to the AudioHook protocol.
Outside of these event messages, audio data is also transferred. We’ll capture and temporarily store this audio locally until the connection is closed, at which point the server processes the audio to a wav file and uploads both the wav and raw audio files to a S3 bucket.
The AudioHook Monitor will send requests to a WebSocket URL we specify when setting up the integration in Step 5.
When first enabled, AudioHook Monitor will do a quick verification step to ensure that the WebSocket server has implemented the AudioHook protocol correctly.
For this example, the server is written in JavaScript (Express) and hosted locally. We’ll use ngrok to create a secure tunnel that exposes it to the internet with a public URL so that Genesys can make a connection.
However, the server can be implemented using your preferred programming language and deployed in whatever environment you choose, provided both support WebSocket TLS connections for secure bidirectional text and binary message exchange.
Server implementationThis server is a method to get up and running quickly for development and
testing purposes without the complexity of a production deployment. How you
implement this in practice will vary widely depending on your traffic volume,
scaling needs, reliability requirements, security concerns, etc.
1
Clone this example repo of a WebSocket server that implements the AudioHook protocol.
Follow the
README instructions to download the necessary dependencies and start the server.
Make sure to look over server.js to get an understanding of how the requests from Genesys are received, processed, and responded to, as well as how the audio is stored, converted, and uploaded to our S3 bucket.2
Make sure to create a
.env file and set the variables:AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY can be found on your account’s
IAM > Security Credentials
page.
API_KEY is explained further in the next
step, but it can be anything you
want to verify that the requests are actually originating from Genesys.3
Download ngrok. Assuming your server is running on 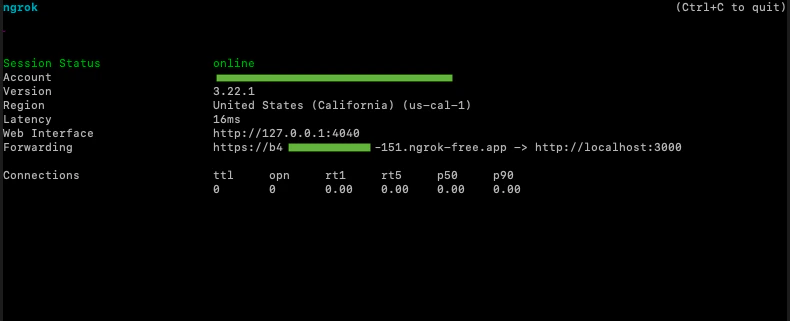
port 3000, run ngrok http 3000 --inspect=false in your terminal.
From the resulting terminal output, note the forwarding url that should look something like this: https://<id>.ngrok-free.app. This is our WebSocket server URL that we’ll provide to the AudioHook Monitor in the next step.Step 5: Setting up AudioHook Monitor
1
In the Genesys Cloud Admin section, navigate to the Integrations page. Add a new integration via the plus sign in the top right corner.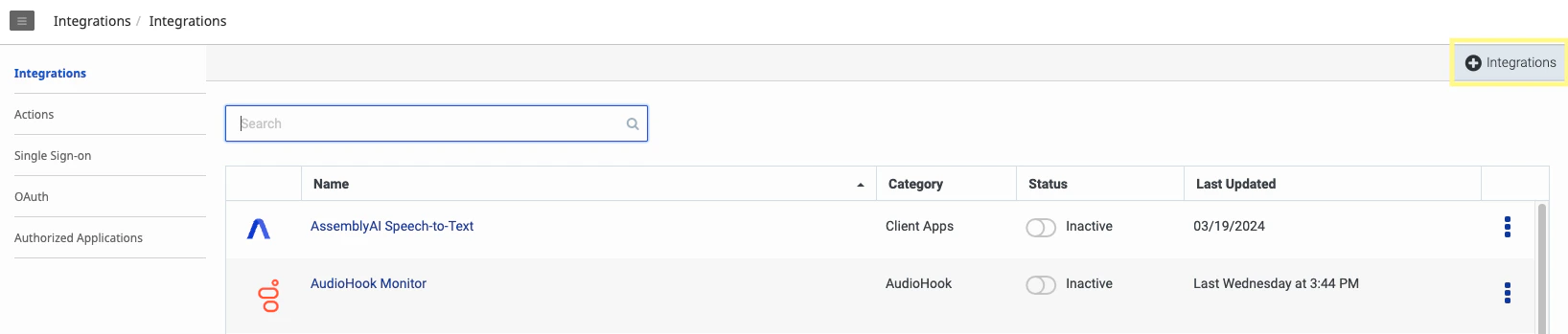
2
Search for AudioHook Monitor and install.
3
Navigate to the AudioHook Monitor’s Configuration tab. Under the Properties section, make sure both channels are selected and the Connection URI is set to the ngrok url from the previous step. For the ngrok url, replace 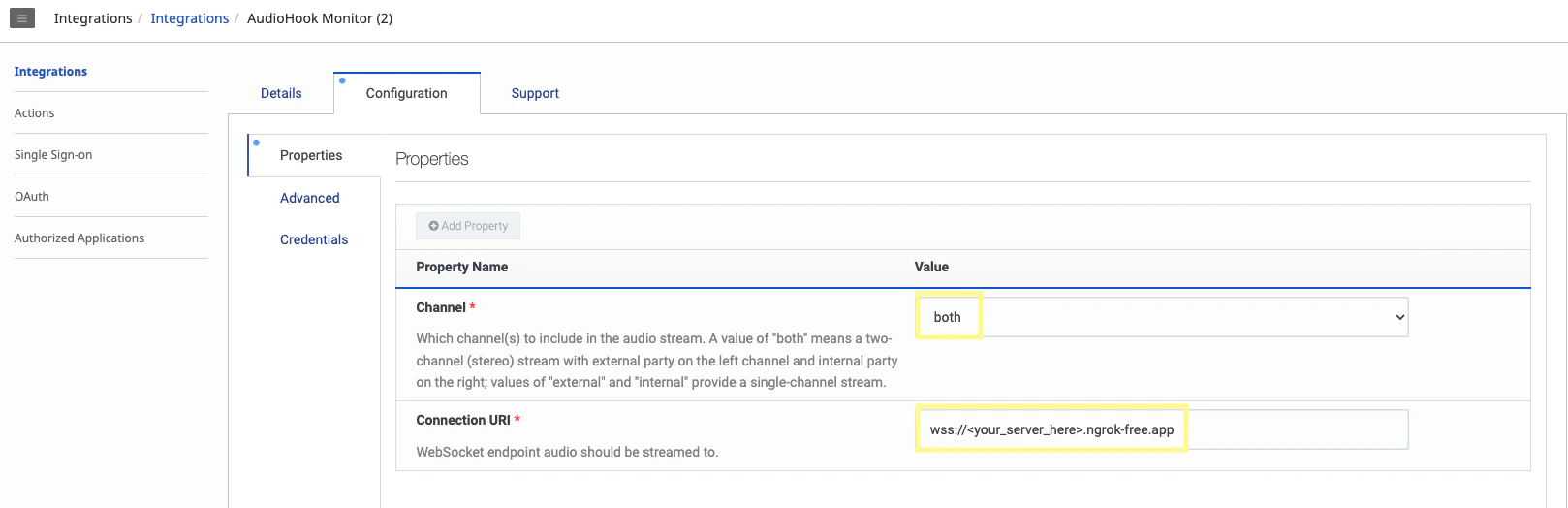
https with wss.4
In the Configuration tab, navigate to the Credentials section, and click Configure. Here you can set an API key to a value our server will use to verify that requests originated from Genesys. This is done via the 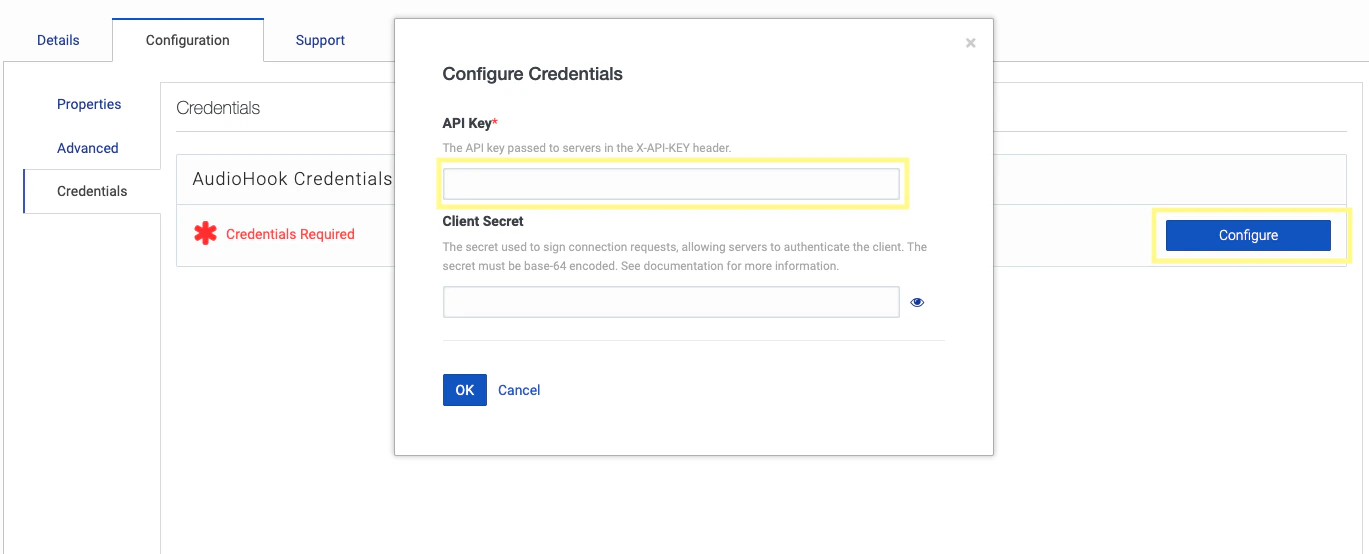
X-API-KEY request header. Our server will compare this key to the value we set in our .env for API_KEY, so make sure they match. Click Save.5
Back on the Integrations page, click the toggle button under the Status column to activate your AudioHook. Genesys will attempt to verify our server is correctly configured according to the AudioHook protocol. If it is unable to do so, a red error will show with the reason for the failed connection. If it succeeds, the connection will toggle to Active.
Step 6: Set up your AssemblyAI API call
1
Navigate to the Lambda services page, and create a new function. Set the runtime to 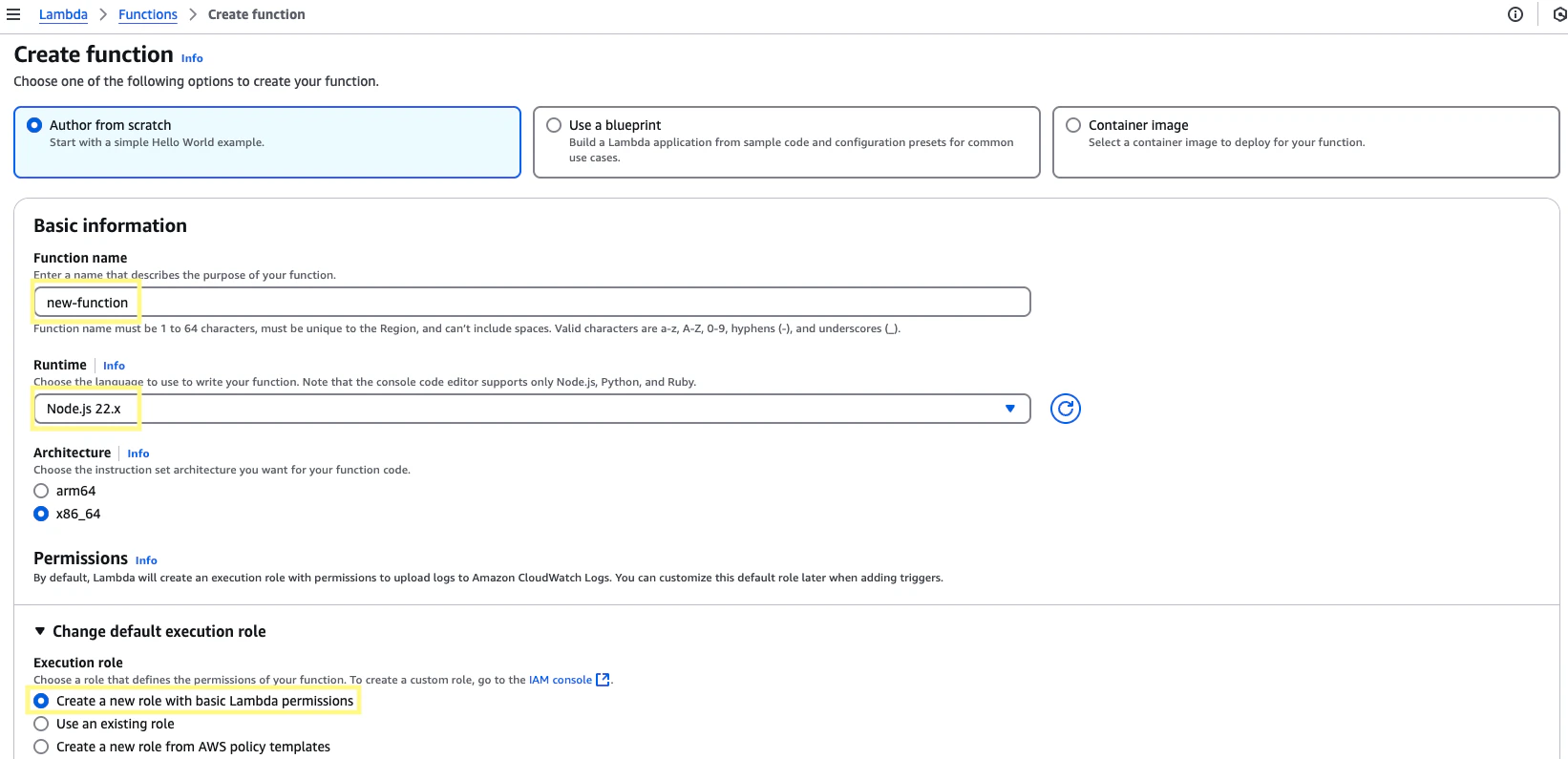
Node.js 22.x. In the Change default execution role section, choose the option to create a new role with basic Lambda permissions. Assign a function name and then click Create function.2
In this new function, scroll down to the Code Source section and paste the following code into
index.js:3
At the top of the Lambda function, you can edit the config to enable features for your transcripts. Since our call is two channels, we’ll want to set
multichannel to true. To see all available parameters, check out our API reference.4
Once you have finished editing the Lambda function, click Deploy to save your changes.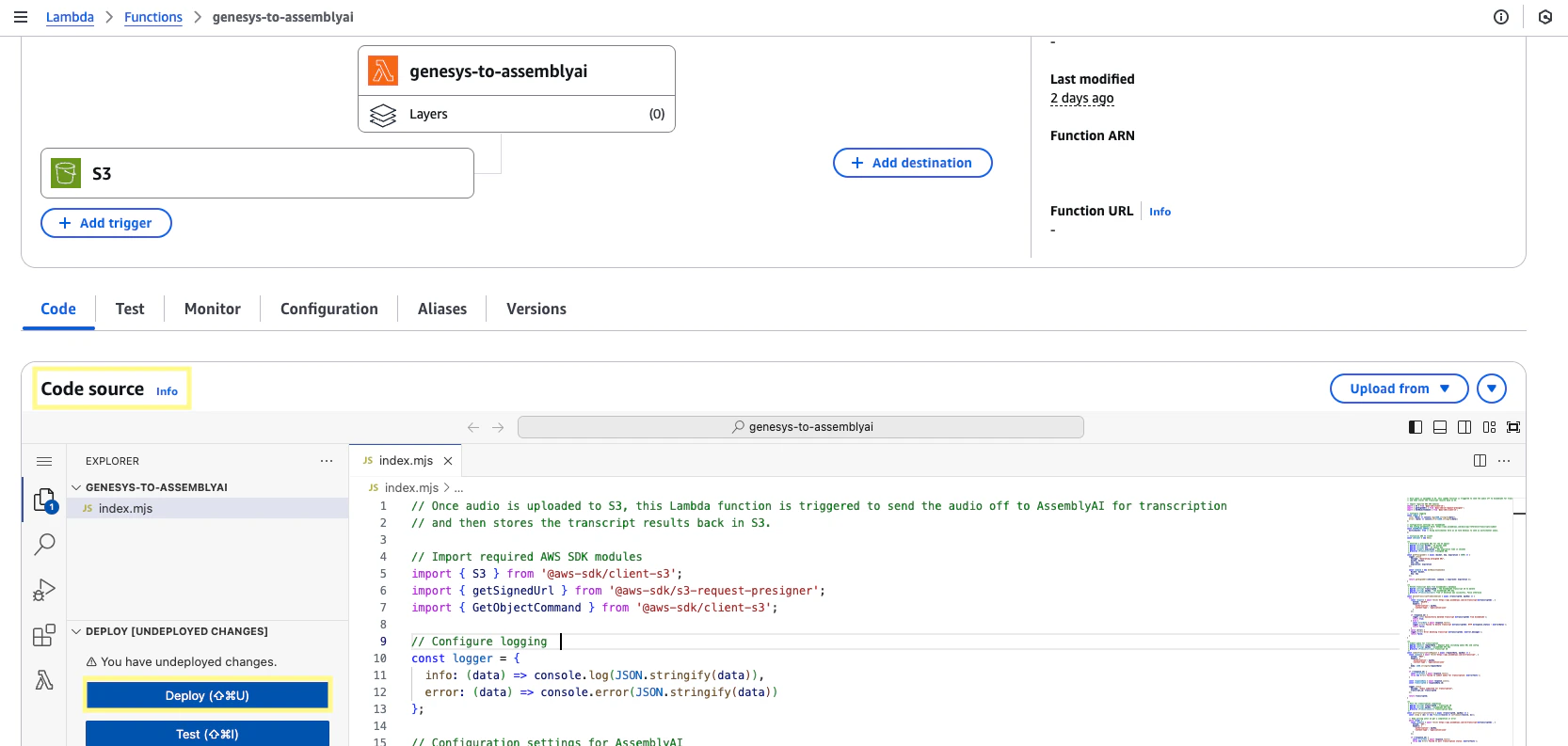
5
On the same page, navigate to the Configuration section. Under General configuration, click Edit, and then adjust Timeout to 
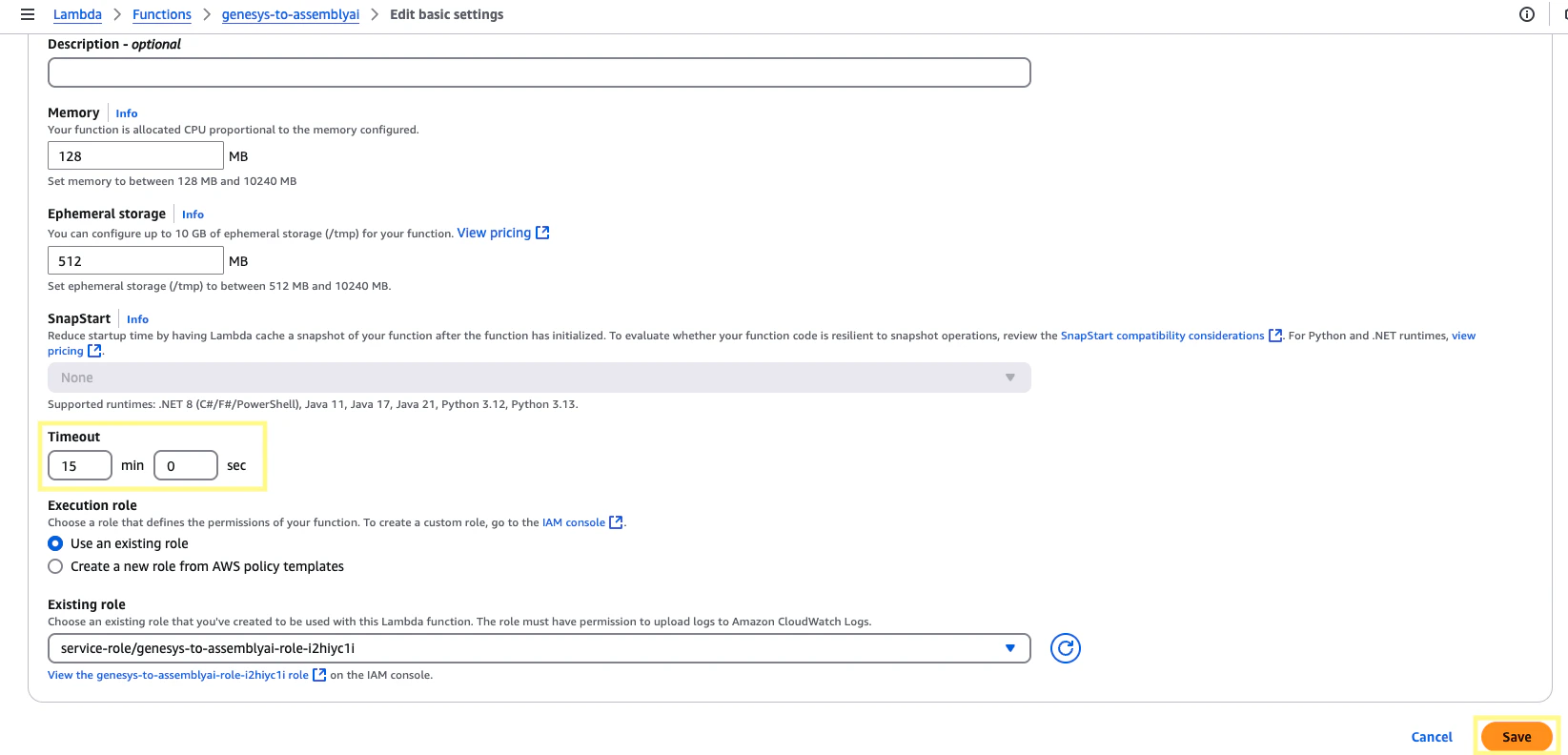
15min 0sec and click Save. The processing times for transcription will be much shorter, but this ensures the function will have plenty of time to run.6
On the left side panel, click Environment variables. Click Edit. Add an environment variable, 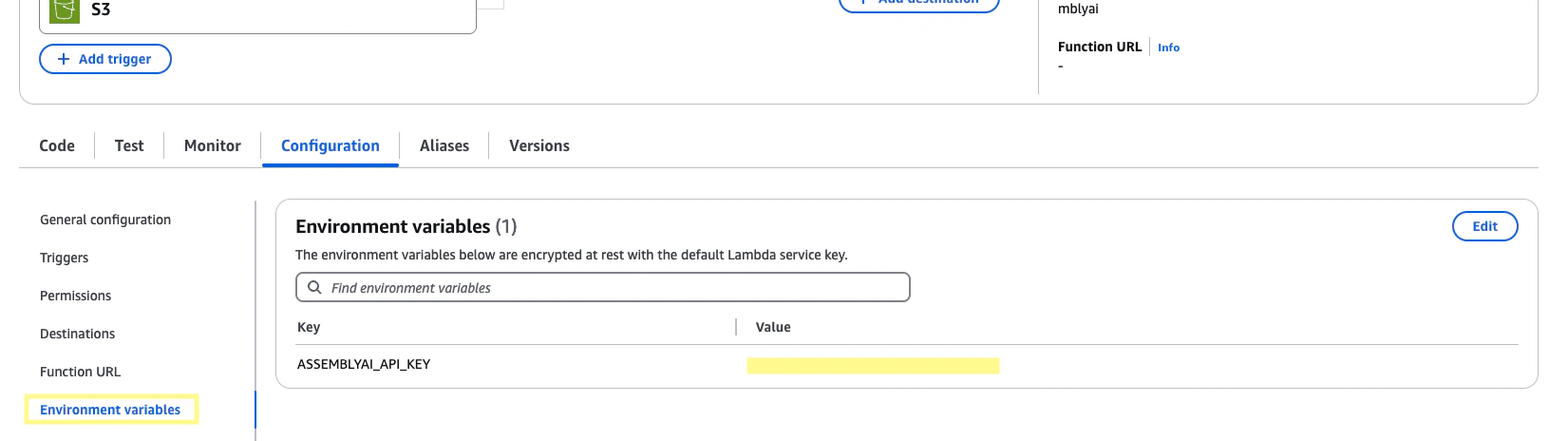
ASSEMBLYAI_API_KEY, and set the value to your AssemblyAI API key. Then click Save.7
Now, navigate to the IAM services page. On the left side panel under Access Management, click Roles and search for your Lambda function’s role (its structure should look like 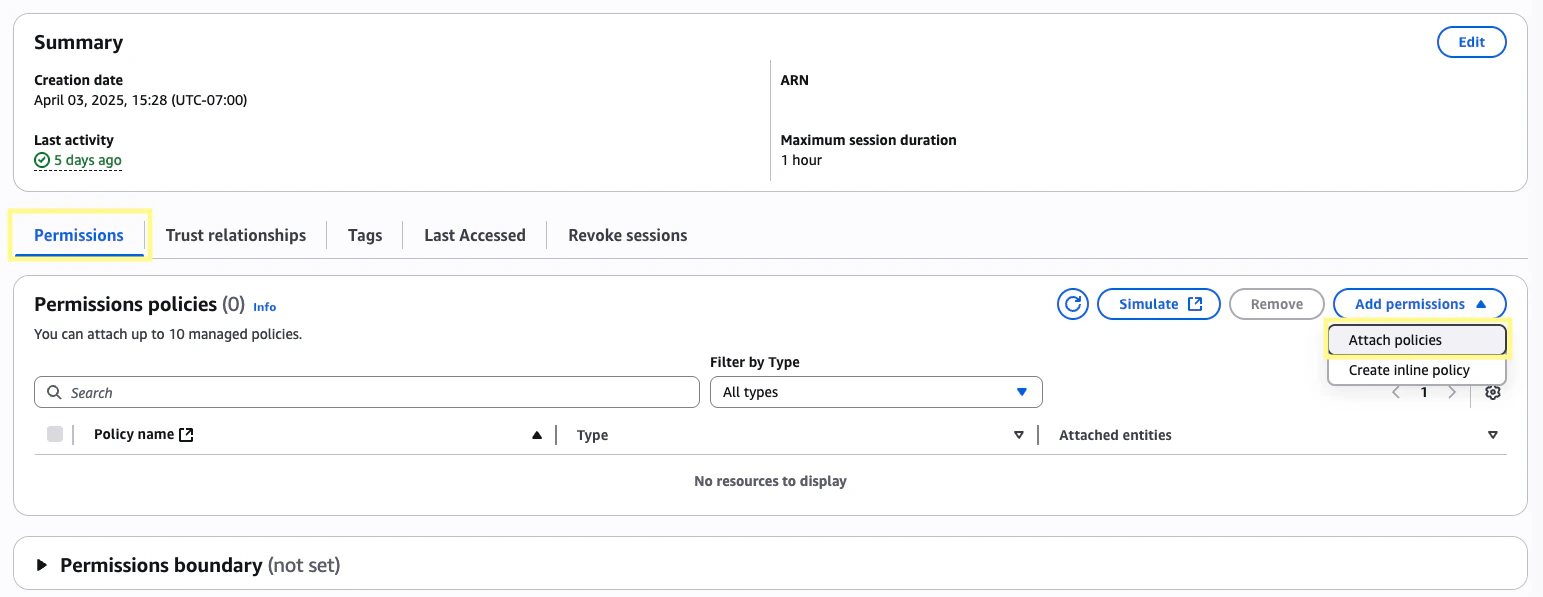
<function_name>-<role_id>). Click the role and then in the Permissions policies section click the dropdown for Add permissions and then select Attach policies.8
From this page, find the policies named 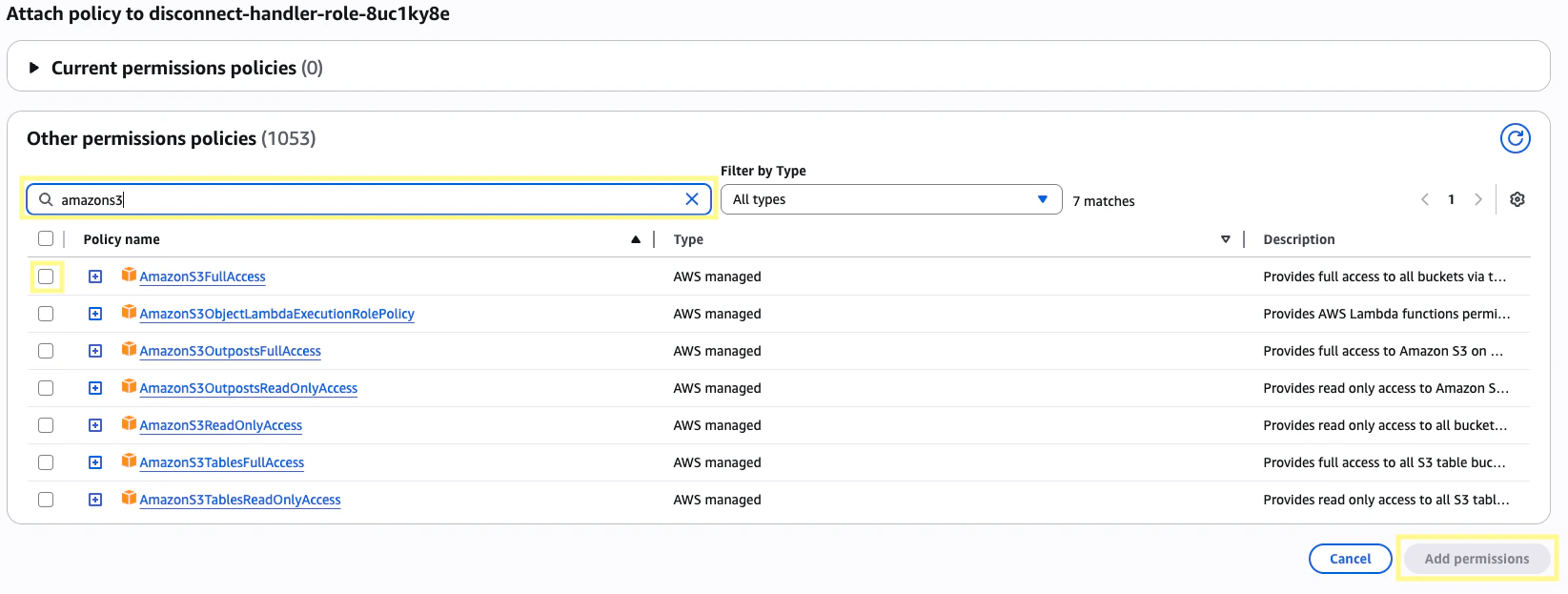
AmazonS3FullAccess and CloudWatchEventsFullAccess. Click Add permissions for both.CloudWatchEventsFullAccess is optional, but helpful for debugging purposes. Once your Lambda runs, it should output all logs to CloudWatch under a Log group /aws/lambda/<your-lambda-fn>9
Now, navigate to the S3 services page and click into the general purpose bucket where your Genesys recordings are stored. Browse to the Properties tab and then scroll down to Event notifications. Click Create event notification.
10
Give the event a name and then in the Prefix section enter 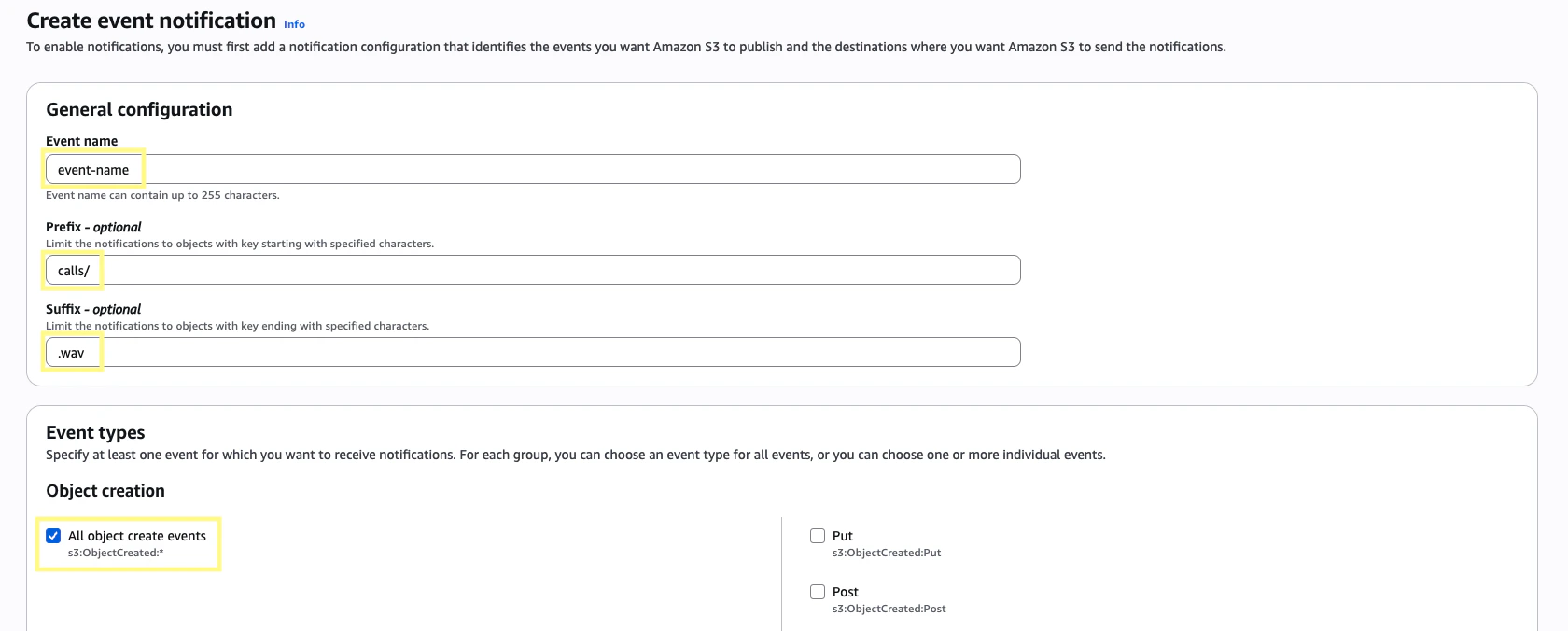
calls/ (or whatever S3_KEY_PREFIX is set to), and in the Suffix section enter .wav. This will ensure the event is triggered once our wav file has been uploaded. In the Event types section, select All object create events.11
Scroll down to the Destination section, set the destination as Lambda function and then select the Lambda function we created in Step 6. Then click Save changes.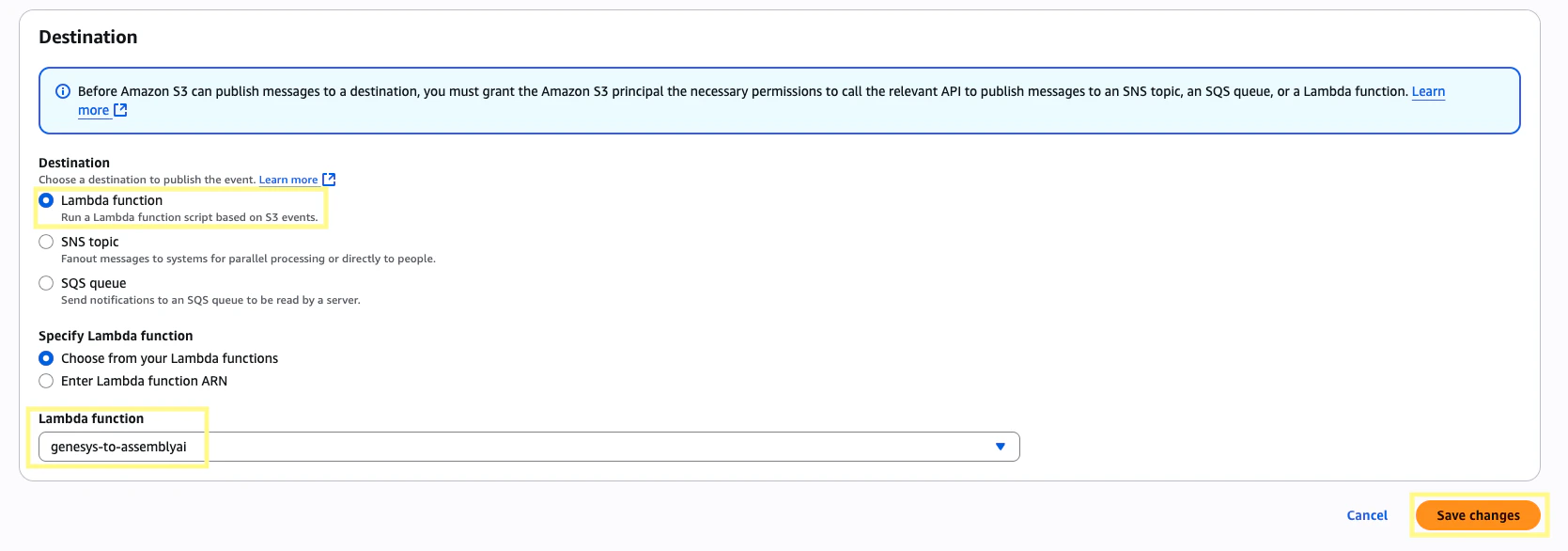
Step 7: Transcribe your first call
1
To test everything is working, call the phone number you linked to this flow in Step 2. Referring to the example flow above, press the DTMF value on the key pad or say the Speech Recognition value. Once transferred, your WebSocket server should start to receive data and output to console:
2
Once the call has ended, you should see the following server logs:
3
To view the logs for this Lambda function, navigate to the CloudWatch services page and under the Logs section, select Log groups.
Select the log group that matches your Lambda to view the most recent log stream. This can be very useful for debugging purposes if you run into any issues.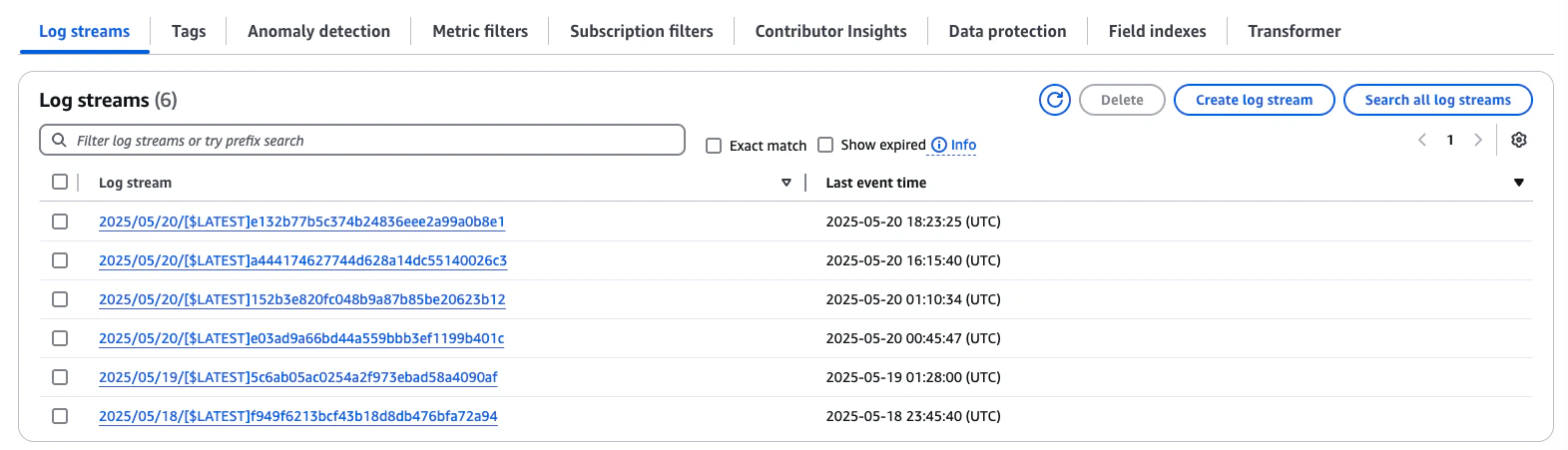
4
Head to your S3 bucket. Within the 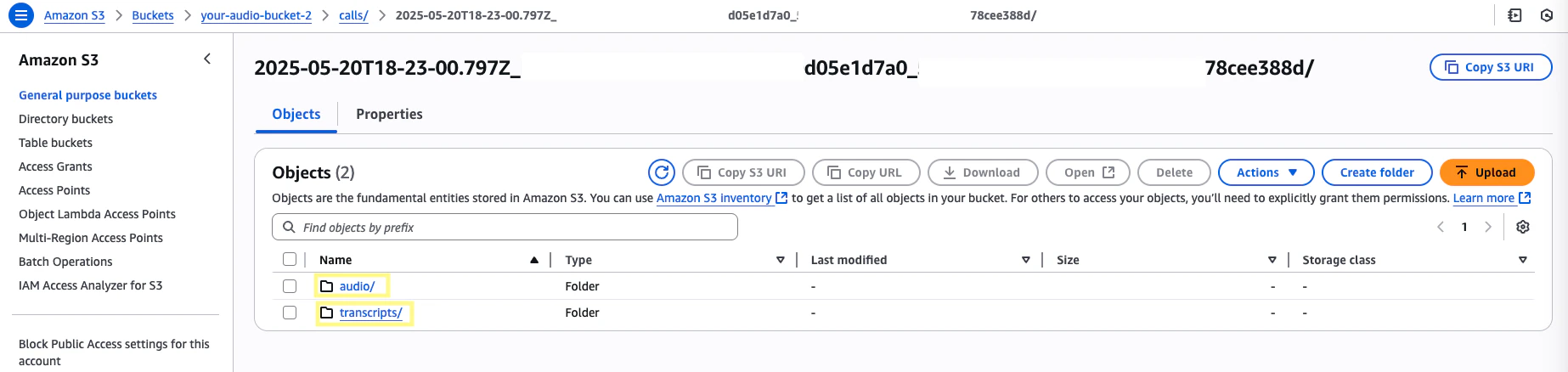
/calls directory, files will be stored under a unique identifier with the following structure:your-audiohook-bucket/calls/<timestamp>_<call_id>_<speaker_id>/<file_type>with audio files (both raw and wav) under /audio and transcript responses under /transcripts.The
raw file can be nice to have for conversions to other formats in the
future, but this step can be omitted to save on storage costs.5
Success! You have successfully integrated AssemblyAI with Genesys Cloud via AudioHook Monitor. If you run into any issues or have further questions, please reach out to our Support team.
Other considerations
Supported audio formats
- Audio is sent as binary WebSocket frames containing the raw audio data in the negotiated format. Currently, only μ-law (Mu-law, PCMU) is supported.
- Before being uploaded to S3, the audio is converted to
wavformat using ffmpeg. As a lossless format,wavgenerally results in high transcription accuracy, but is not required. A full list of file formats supported by AssemblyAI’s API can be found in our FAQ.
Multichannel
- As mentioned in Step 6, the
multichannelparameter should be enabled as the files are stereo utilizing one channel for each participant. When possible, multiple channels are recommended by AssemblyAI for the most accurate transcription results. - If single channel is preferred, you can simplify the approach to only send a single channel with both speakers (via AudioHook) and adjust your server code to be single channel.