Speaker diarization vs speaker recognition - what's the difference?
Learn the differences between speaker diarization and speaker recognition, as well as speaker verification and speaker identification in audio analysis



An increasing number of applications are incorporating features that build on speech data. One of the most common capabilities used as the bedrock of these features pertains to separating speech based on speakers; however, it can be a difficult area to navigate. The field of audio analysis is intimately coupled to academic research, and some of the associated jargon consequently finds its way into more common usage, which in turn can cause a point of confusion for developers trying to build features around spoken language.
Phrases like "speaker diarization", "speaker recognition", "speaker identification", "voice fingerprinting" and more show up and bring with them questions like "what are the differences between these terms?" and "do these terms mean the same thing?".
In this article, we'll take a high-level look at each of these terms and more to help you navigate this corner of the field of speech technology, including some example use cases to concretize how each is used.
Speaker Diarization vs Speaker Recognition
The two most common and commonly conflated terms in this area are speaker diarization and speaker recognition. Broadly, the differences between these terms mostly lie in their ability to work on novel data and what it means to "identify" a speaker.
Speaker Diarization
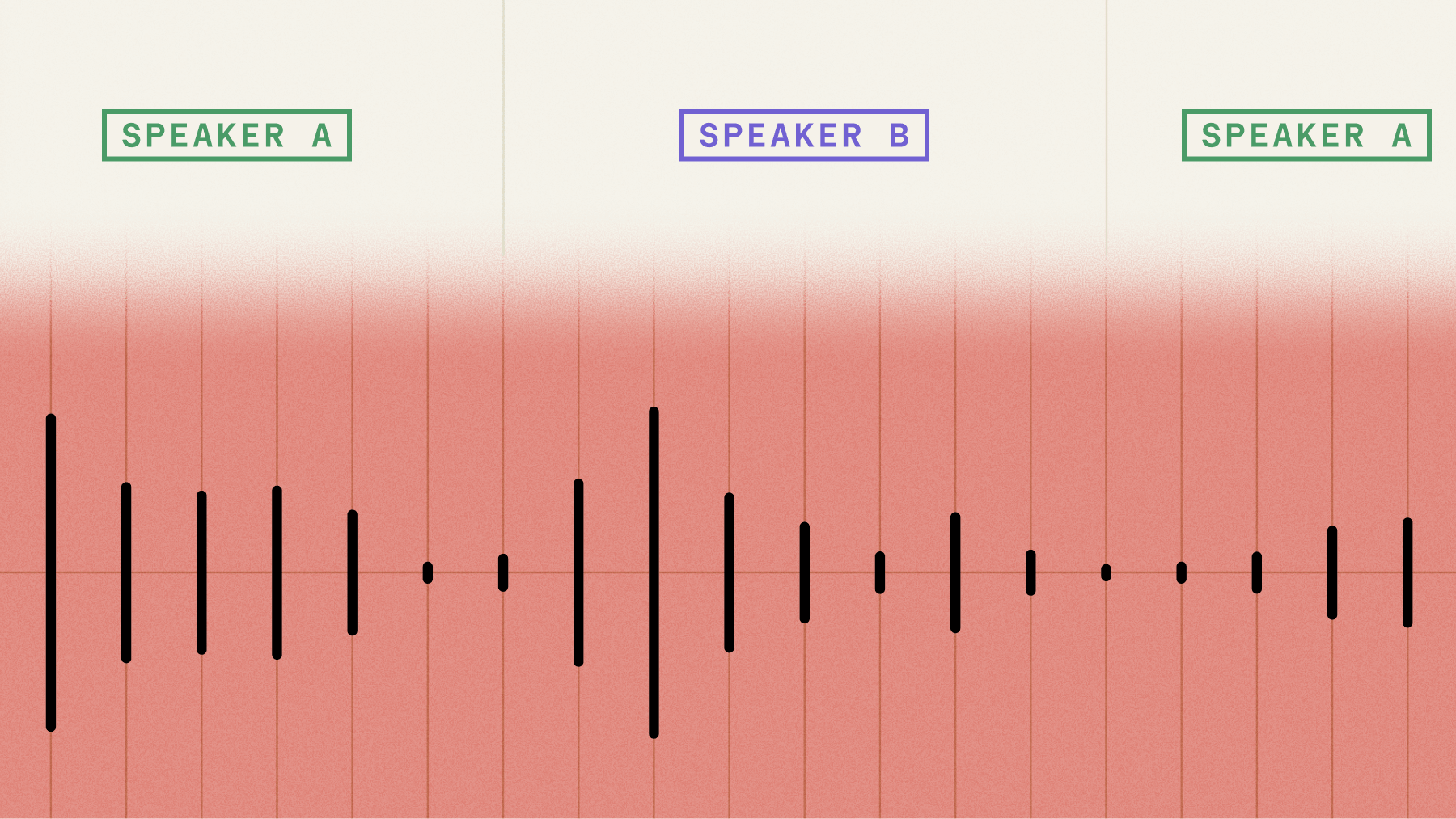
Speaker diarization is the process of partitioning an audio file into segments according to speaker identity. It answers the question, "who said what when?" by grouping segments of the audio file by speaker, without prior knowledge of the speakers' personal identities. In other words, speaker diarization alone can "bucket" each utterance in the file according to speaker, but it can't label those buckets with the speakers' names.

Here's an example output of speaker diarization on a call center call:
As we can see, speaker diarization successfully maps each utterance to a unique speaker, but these speakers are not personally identified and are instead labeled, in this case, as A, B, etc.
Speaker diarization is particularly useful in scenarios where the goal is to understand the structure of a conversation. For example, in a business meeting recording, speaker diarization can segment the audio into parts where each participant is speaking, making it easier to follow the conversation and understand the participants' reasoning as a whole. Speaker diarization can also be used to great effect when the personal identities of speakers are obvious or implied, like in a call center.
Speaker Recognition
Speaker recognition involves analyzing vocal patterns to determine or verify the identity of a speaker. It it an umbrella term that encompasses both speaker identification and speaker verification. This technique is used in security systems, voice-activated devices, and other applications in which identifying or verifying a speaker's identity is necessary. For instance, a smart home device could utilize speaker recognition for personalized responses without the need to explicitly specify a name to the system. When a user asks "What's on my schedule?", the device could use speaker recognition to identify who is speaking in order to return events from that particular person's calendar.

Benefits and drawbacks
The central advantage of speaker diarization is its ability to operate on unseen data. Since speaker diarization groups utterances spoken by the same speaker, it requires no a priori knowledge about those speakers themselves. On the other hand, for some applications this is not sufficient, and the personal identities of speakers are required.
Conversely, speaker recognition has the advantage of identifying speakers in the colloquially-understood way. Here, "identify" really does mean identify the personal identity of the speaker, rather than just as a speaker in contrast to all others. On the other hand, speaker recognition necessarily requires some additional information to map vocal patterns to personal identities. It therefore needs a "ledger" of voices on which it has been trained that it can reference when trying to identify a voice. This additionally means that speaker recognition can be brittle in the way it handles previously-unencountered speakers.
It may be desirable to combine both speaker diarization and recognition to achieve segmented audio that also personally identifies the speakers, to achieve something like this:
Speaker Verification vs Speaker Identification
In addition to speaker diarization and speaker recognition, you may come across the terms speaker verification and speaker identification. These are both subsets of speaker recognition.
Speaker Verification
Speaker verification, sometimes referred to as "voice fingerprinting," confirms that a voice belongs to a preselected identity profile. This technique is commonly used in security systems to verify the identity of a person. For example, a financial institution might use voice fingerprinting to verify the identity of customers during phone transactions, ensuring that the person on the phone is indeed the account holder.

Speaker Identification
Speaker identification is used to map a voice to a pool of potential identities. This technique requires a pre-existing database of vocal patterns and seeks to map the vocal patterns in the audio to one of the known speakers in the database. If you have a diarized transcript, speaker identification can map speakers to their identities. This is useful in scenarios where every voice needs to be mapped to someone in the pool, such as in a meeting where all participants are known.
Final Words
Understanding the differences between speaker diarization, speaker recognition, speaker verification, and speaker identification is essential for effectively analyzing and interpreting audio data. Each technique offers unique benefits and can be applied in various scenarios to extract valuable insights from audio recordings. Combining these techniques can create a robust audio analysis pipeline, leveraging the strengths of each method to achieve more accurate and comprehensive results.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts