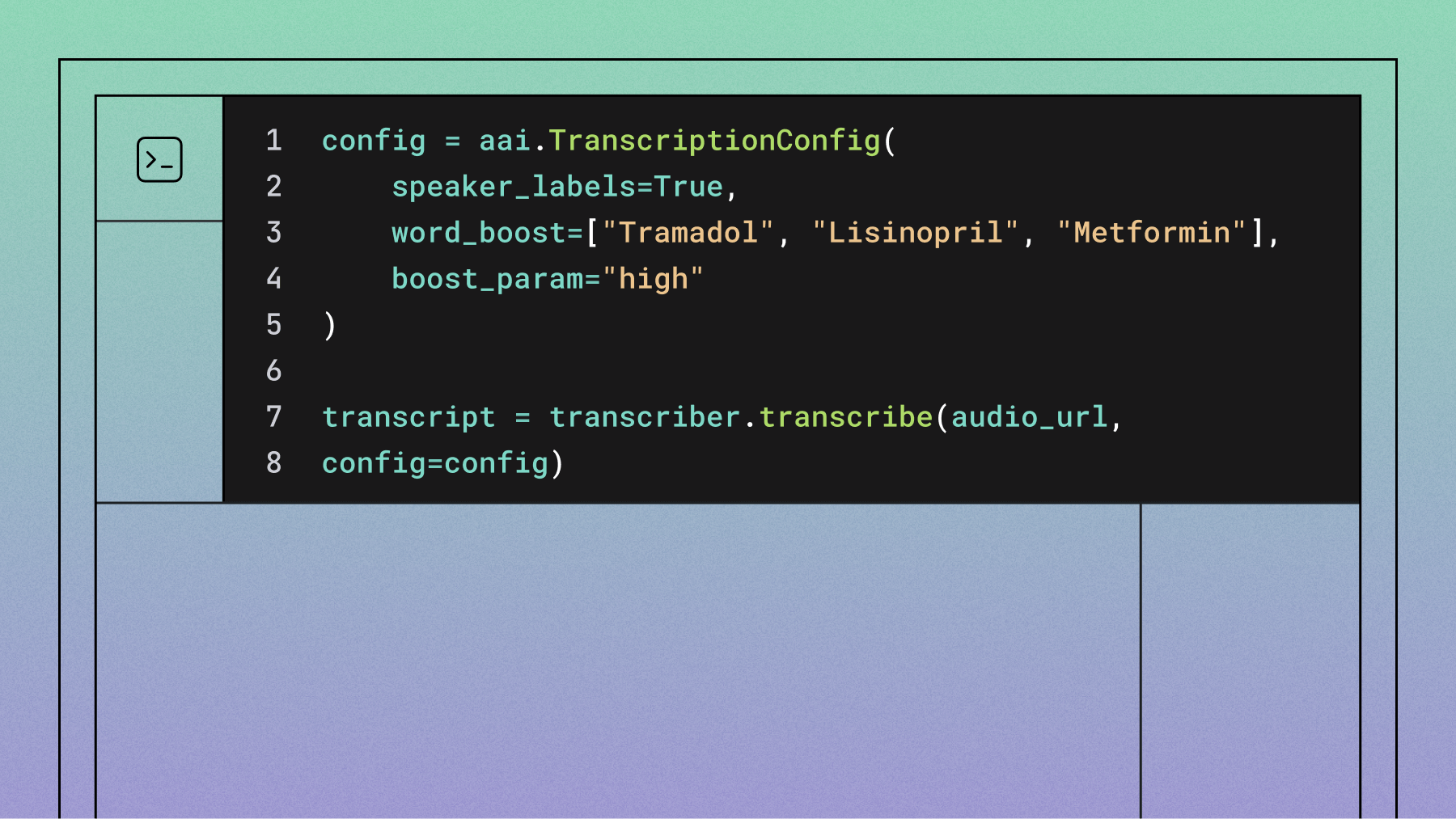
Speaker diarization: Speaker labels for mono channel files
AssemblyAI Speech-to-Text API's Speaker Diarization (speaker labels) is the process of splitting audio or video inputs automatically based on the speaker's identity. It helps you answer the question "who spoke when?".



Speaker diarization is AI technology that automatically identifies "who spoke when" in audio recordings with multiple people. A recent market survey reveals that 76% of companies embed conversation intelligence in more than half of their customer interactions, making it crucial to understand core components like diarization. It separates conversations by voice, labeling each speaker consistently throughout the recording (Speaker A, Speaker B, etc.) without identifying specific individuals by name.
For developers building Voice AI applications, speaker diarization transforms undifferentiated audio into structured, analyzable conversations. Without it, you get a wall of text. With it, you get clear attribution that makes transcripts actionable.
This guide covers:
- How speaker diarization works technically
- Quality evaluation methods and metrics
- Implementation approaches and challenges
- Practical use cases across industries
What is speaker diarization?
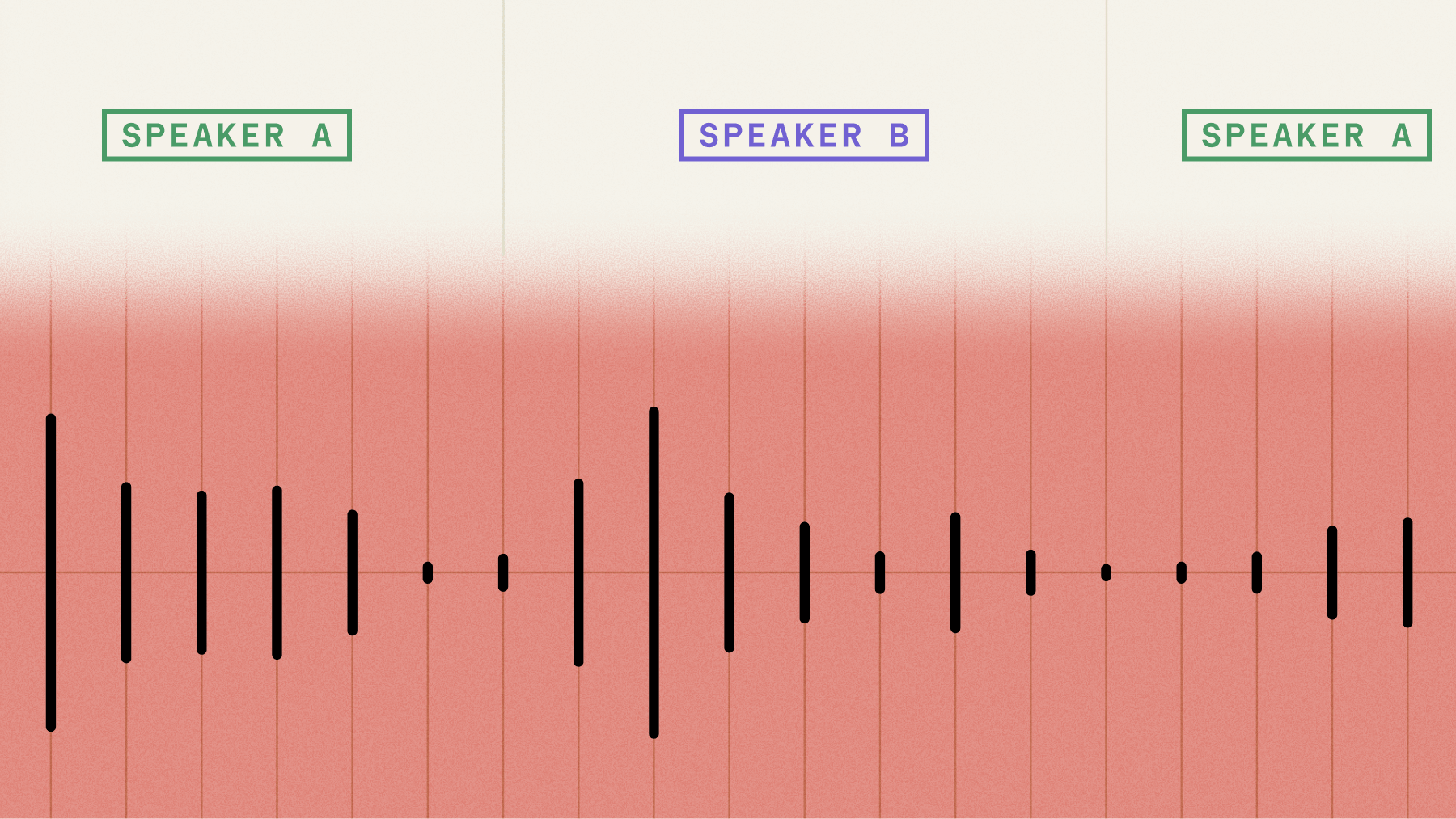
Speaker diarization automatically segments audio recordings by speaker, creating distinct labels for each voice in a conversation (e.g., Speaker A, Speaker B). While the core technology distinguishes between different voices and consistently labels them, it can be combined with AssemblyAI's Speaker Identification feature to replace these generic labels with actual names or roles, like "Agent" or "Customer".
Consider a customer service call. Raw transcription gives you:
"Hi I'm calling about my order it hasn't arrived yet I'm sorry to hear that let me look that up for you can you provide your order number sure it's 12345"
With speaker diarization, the same conversation becomes:
Speaker A: "Hi, I'm calling about my order. It hasn't arrived yet."
Speaker B: "I'm sorry to hear that. Let me look that up for you. Can you provide your order number?"
Speaker A: "Sure, it's 12345."
This structure immediately reveals the conversation flow, making it possible to analyze agent performance, customer sentiment, or conversation patterns. The labels remain consistent—Speaker A stays Speaker A throughout the entire recording.

Why speaker diarization matters
Accurate speaker diarization transforms conversations from raw data into structured information that drives business insights and automation.
Industries that rely on speaker diarization include:
- Media monitoring: Track which speakers mention specific topics or brands
- Telephony: Analyze customer service and sales call performance
- Podcasting: Create searchable transcripts with speaker attribution
- Telemedicine: Separate doctor-patient conversations for documentation
- Web conferencing: Generate meeting notes with clear speaker attribution
For customer service operations, diarization enables quality assurance at scale. Managers can analyze agent talk time ratios, identify coaching opportunities, and ensure compliance—all without listening to entire calls. Companies like Jiminny use speaker-separated transcripts to help sales teams identify winning conversation patterns.
Meeting intelligence platforms depend on accurate speaker labels to generate useful summaries. When action items are correctly attributed to specific participants, follow-ups become automatic. Teams using tools built on accurate diarization report significant reductions in time spent on manual meeting notes.
Upload a call or meeting recording to see speakers separated and labeled automatically. Preview turn-by-turn transcripts—no setup or code required.
In healthcare, speaker diarization separates doctor-patient conversations for accurate medical documentation. This is critical, as research shows patient history contributes to 76% of initial diagnoses, making an accurate record of the conversation essential. Legal teams require precise speaker attribution for depositions and hearings where misattribution could have serious consequences. Media companies use diarization to make content searchable by speaker, improving accessibility and engagement.
The impact compounds across use cases. Poor diarization doesn't just create confusion—it undermines every downstream application. When your system can't reliably separate speakers, analytics become unreliable, insights become questionable, and automation becomes impossible.
How speaker diarization works
Modern speaker diarization has evolved from statistical methods to AI-powered systems that achieve dramatically better accuracy, with documented improvements of 30% in noisy environments for some models.
Today's AI models learn unique voice patterns—not just pitch differences, but subtle patterns in pronunciation, rhythm, and speaking style that distinguish speakers even in challenging conditions.

The key breakthrough is that these models learn from massive datasets to understand subtle voice patterns that distinguish speakers—not just obvious differences like pitch, but complex patterns in pronunciation, rhythm, and speaking style.
Main approaches to speaker diarization
Speaker diarization systems use three main architectural approaches:
Clustering-Based Approaches
Process entire audio files to group segments by speaker similarity using K-means or spectral clustering. Best for offline processing.
End-to-End Neural Approaches
Use transformer architectures to predict speaker labels directly from audio features. Excel at handling overlapping speech.
Hybrid Pipeline Systems
Combine Voice Activity Detection, neural embeddings, and clustering. Allows optimization of each component independently.
Clustering-Based Approaches
Traditional clustering methods extract embeddings for audio segments, then group segments from the same speaker using algorithms like K-means. This approach works well for offline processing where the entire audio is available upfront.
End-to-End Neural Approaches
Recent advances have produced end-to-end neural networks that treat diarization as a single optimization problem. These models, like those using transformer architectures, learn to directly predict speaker labels from raw audio features. They excel at handling overlapping speech and maintaining consistency across long recordings.
Hybrid Pipeline Systems
Many production systems combine multiple techniques in a pipeline. They might use Voice Activity Detection (VAD) to identify speech regions, neural embeddings to characterize speakers, and sophisticated clustering to group segments. This modular approach allows optimization of each component independently.
Infrastructure of speaker diarization
Understanding the technical pipeline reveals how modern diarization systems achieve their accuracy. Each stage addresses specific challenges in separating speakers from raw audio.

Step 1 - Speech Detection – Use Voice Activity Detector (VAD) to identify speech and remove noise.

Step 2 - Speech Segmentation – Extract short segments (sliding window) from the audio & run LSTM network to produce D vectors for each sliding window.

Step 3 - Embedding Extraction – Aggregate the d-vector for each segment belonging to that segment to produce segment-wise embeddings.
Step 4 - Clustering — Cluster the segment-wise embedding to produce diarization results. Determine the number of speakers with each speaker's time stamps using clustering algorithms integrated into the diarization system.
- Offline Clustering - Speaker labels are produced after the embeddings of all segments are available
- K-Means Clustering: use KMeans++ for initialization to determine the number of speakers. The system uses the "elbow" of the derivatives of conditional Mean Squared Cosine Distances (MSCD) between each embedding to its cluster centroid
- Spectral Clustering: 1) construct the affinity matrix, 2) perform refinement operations 3) perform eigen-decomposition on the refined affinity matrix 4) use K-Means to cluster these new embeddings, and produce speaker labels

Related posts